 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSE: A diffusion probabilistic model for automatic structure elucidation of organic compounds
Oct 30, 2025Automatic structure elucidation is essential for self-driving laboratories as it enables the system to achieve truly autonomous. This capability closes the experimental feedback loop, ensuring that machine learning models receive reliable structure information for real-time decision-making and optimization. Herein, we present DiSE, an end-to-end diffusion-based generative model that integrates multiple spectroscopic modalities, including MS, 13C and 1H chemical shifts, HSQC, and COSY, to achieve automated yet accurate structure elucidation of organic compounds. By learning inherent correlations among spectra through data-driven approaches, DiSE achieves superior accuracy, strong generalization across chemically diverse datasets, and robustness to experimental data despite being trained on calculated spectra. DiSE thus represents a significant advance toward fully automated structure elucidation, with broad potential in natural product research, drug discovery, and self-driving laboratories.
A Multi-Source Retrieval Question Answering Framework Based on RAG
May 29, 2024



With the rapid development of large-scale language models, Retrieval-Augmented Generation (RAG) has been widely adopted. However, existing RAG paradigms are inevitably influenced by erroneous retrieval information, thereby reducing the reliability and correctness of generated results. Therefore, to improve the relevance of retrieval information, this study proposes a method that replaces traditional retrievers with GPT-3.5, leveraging its vast corpus knowledge to generate retrieval information. We also propose a web retrieval based method to implement fine-grained knowledge retrieval, Utilizing the powerful reasoning capability of GPT-3.5 to realize semantic partitioning of problem.In order to mitigate the illusion of GPT retrieval and reduce noise in Web retrieval,we proposes a multi-source retrieval framework, named MSRAG, which combines GPT retrieval with web retrieval. Experiments on multiple knowledge-intensive QA datasets demonstrate that the proposed framework in this study performs better than existing RAG framework in enhancing the overall efficiency and accuracy of QA systems.
D-Bot: Database Diagnosis System using Large Language Models
Dec 06, 2023



Database administrators (DBAs) play an important role in managing, maintaining and optimizing database systems. However, it is hard and tedious for DBAs to manage a large number of databases and give timely response (waiting for hours is intolerable in many online cases). In addition, existing empirical methods only support limited diagnosis scenarios, which are also labor-intensive to update the diagnosis rules for database version updates. Recently large language models (LLMs) have shown great potential in various fields. Thus, we propose D-Bot, an LLM-based database diagnosis system that can automatically acquire knowledge from diagnosis documents, and generate reasonable and well-founded diagnosis report (i.e., identifying the root causes and solutions) within acceptable time (e.g., under 10 minutes compared to hours by a DBA). The techniques in D-Bot include (i) offline knowledge extraction from documents, (ii) automatic prompt generation (e.g., knowledge matching, tool retrieval), (iii) root cause analysis using tree search algorithm, and (iv) collaborative mechanism for complex anomalies with multiple root causes. We verify D-Bot on real benchmarks (including 539 anomalies of six typical applications), and the results show that D-Bot can effectively analyze the root causes of unseen anomalies and significantly outperforms traditional methods and vanilla models like GPT-4.
Topic-switch adapted Japanese Dialogue System based on PLATO-2
Feb 22, 2023Large-scale open-domain dialogue systems such as PLATO-2 have achieved state-of-the-art scores in both English and Chinese. However, little work explores whether such dialogue systems also work well in the Japanese language. In this work, we create a large-scale Japanese dialogue dataset, Dialogue-Graph, which contains 1.656 million dialogue data in a tree structure from News, TV subtitles, and Wikipedia corpus. Then, we train PLATO-2 using Dialogue-Graph to build a large-scale Japanese dialogue system, PLATO-JDS. In addition, to improve the PLATO-JDS in the topic switch issue, we introduce a topic-switch algorithm composed of a topic discriminator to switch to a new topic when user input differs from the previous topic. We evaluate the user experience by using our model with respect to four metrics, namely, coherence, informativeness, engagingness, and humanness. As a result, our proposed PLATO-JDS achieves an average score of 1.500 for the human evaluation with human-bot chat strategy, which is close to the maximum score of 2.000 and suggests the high-quality dialogue generation capability of PLATO-2 in Japanese. Furthermore, our proposed topic-switch algorithm achieves an average score of 1.767 and outperforms PLATO-JDS by 0.267, indicating its effectiveness in improving the user experience of our system.
Complete Cross-triplet Loss in Label Space for Audio-visual Cross-modal Retrieval
Nov 07, 2022The heterogeneity gap problem is the main challenge in cross-modal retrieval. Because cross-modal data (e.g. audiovisual) have different distributions and representations that cannot be directly compared. To bridge the gap between audiovisual modalities, we learn a common subspace for them by utilizing the intrinsic correlation in the natural synchronization of audio-visual data with the aid of annotated labels. TNN-CCCA is the best audio-visual cross-modal retrieval (AV-CMR) model so far, but the model training is sensitive to hard negative samples when learning common subspace by applying triplet loss to predict the relative distance between inputs. In this paper, to reduce the interference of hard negative samples in representation learning, we propose a new AV-CMR model to optimize semantic features by directly predicting labels and then measuring the intrinsic correlation between audio-visual data using complete cross-triple loss. In particular, our model projects audio-visual features into label space by minimizing the distance between predicted label features after feature projection and ground label representations. Moreover, we adopt complete cross-triplet loss to optimize the predicted label features by leveraging the relationship between all possible similarity and dissimilarity semantic information across modalities. The extensive experimental results on two audio-visual double-checked datasets have shown an improvement of approximately 2.1% in terms of average MAP over the current state-of-the-art method TNN-CCCA for the AV-CMR task, which indicates the effectiveness of our proposed model.
Variational Autoencoder with CCA for Audio-Visual Cross-Modal Retrieval
Dec 05, 2021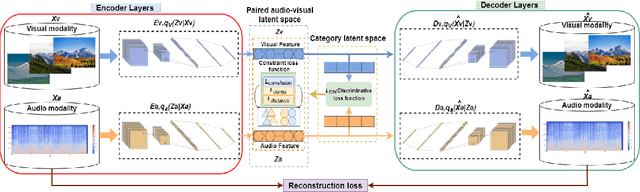


Cross-modal retrieval is to utilize one modality as a query to retrieve data from another modality, which has become a popular topic in information retrieval, machine learning, and database. How to effectively measure the similarity between different modality data is the major challenge of cross-modal retrieval. Although several reasearch works have calculated the correlation between different modality data via learning a common subspace representation, the encoder's ability to extract features from multi-modal information is not satisfactory. In this paper, we present a novel variational autoencoder (VAE) architecture for audio-visual cross-modal retrieval, by learning paired audio-visual correlation embedding and category correlation embedding as constraints to reinforce the mutuality of audio-visual information. On the one hand, audio encoder and visual encoder separately encode audio data and visual data into two different latent spaces. Further, two mutual latent spaces are respectively constructed by canonical correlation analysis (CCA). On the other hand, probabilistic modeling methods is used to deal with possible noise and missing information in the data. Additionally, in this way, the cross-modal discrepancy from intra-modal and inter-modal information are simultaneously eliminated in the joint embedding subspace. We conduct extensive experiments over two benchmark datasets. The experimental outcomes exhibit that the proposed architecture is effective in learning audio-visual correlation and is appreciably better than the existing cross-modal retrieval methods.