 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonality-Aware Reinforcement Learning for Persuasive Dialogue with LLM-Driven Simulation
Jan 11, 2026Effective persuasive dialogue agents adapt their strategies to individual users, accounting for the evolution of their psychological states and intentions throughout conversations. We present a personality-aware reinforcement learning approach comprising three main modules: (1) a Strategy-Oriented Interaction Framework, which serves as an agenda-based strategy controller that selects strategy-level actions and generate responses via Maximal Marginal Relevance (MMR) retrieval to ensure contextual relevance, diversity, and scalable data generation; (2) Personality-Aware User Representation Learning, which produces an 81-dimensional mixed-type embedding predicted at each turn from recent exchanges and appended to the reinforcement learning state; and (3) a Dueling Double DQN (D3QN) model and Reward Prediction, in which the policy is conditioned on dialogue history and turn-level personality estimates and trained using a composite reward incorporating agreement intent, donation amount, and changeof-mind penalties. We use an agenda-based LLM simulation pipeline to generate diverse interactions, from which personality estimation is inferred from the generated utterances. Experiments on the PersuasionForGood (P4G) dataset augmented with simulated dialogues reveal three main findings: (i) turn-level personality conditioning improves policy adaptability and cumulative persuasion rewards; (ii) LLM-driven simulation enhances generalization to unseen user behaviors; and (iii) incorporating a change-of-mind penalty reduces post-agreement retractions while slightly improving donation outcomes. These results demonstrate that structured interaction, dynamic personality estimation, and behaviorally informed rewards together yield more effective persuasive policies.
Social Comparison without Explicit Inference of Others' Reward Values: A Constructive Approach Using a Probabilistic Generative Model
Dec 23, 2025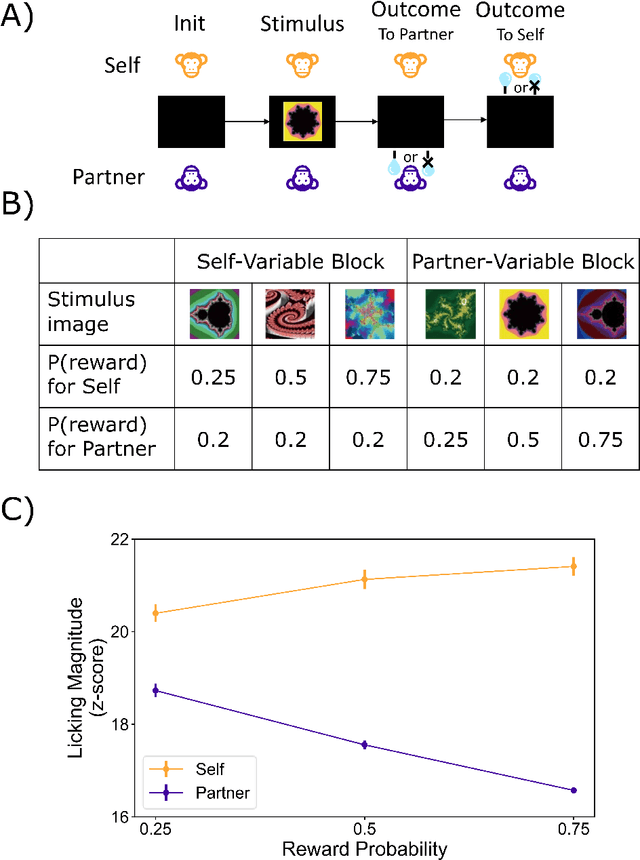

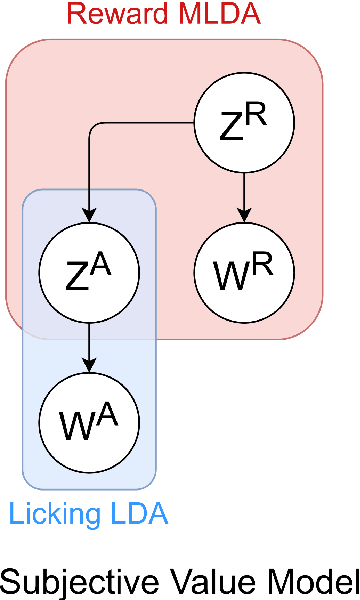
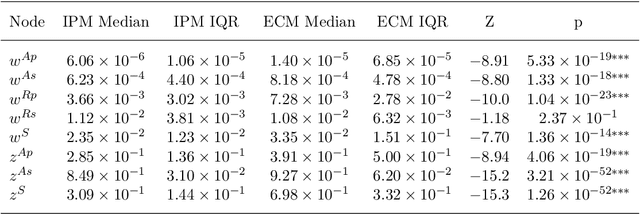
Social comparison$\unicode{x2014}$the process of evaluating one's rewards relative to others$\unicode{x2014}$plays a fundamental role in primate social cognition. However, it remains unknown from a computational perspective how information about others' rewards affects the evaluation of one's own reward. With a constructive approach, this study examines whether monkeys merely recognize objective reward differences or, instead, infer others' subjective reward valuations. We developed three computational models with varying degrees of social information processing: an Internal Prediction Model (IPM), which infers the partner's subjective values; a No Comparison Model (NCM), which disregards partner information; and an External Comparison Model (ECM), which directly incorporates the partner's objective rewards. To test model performance, we used a multi-layered, multimodal latent Dirichlet allocation. We trained the models on a dataset containing the behavior of a pair of monkeys, their rewards, and the conditioned stimuli. Then, we evaluated the models' ability to classify subjective values across pre-defined experimental conditions. The ECM achieved the highest classification score in the Rand Index (0.88 vs. 0.79 for the IPM) under our settings, suggesting that social comparison relies on objective reward differences rather than inferences about subjective states.
Towards Unsupervised Causal Representation Learning via Latent Additive Noise Model Causal Autoencoders
Dec 15, 2025Unsupervised representation learning seeks to recover latent generative factors, yet standard methods relying on statistical independence often fail to capture causal dependencies. A central challenge is identifiability: as established in disentangled representation learning and nonlinear ICA literature, disentangling causal variables from observational data is impossible without supervision, auxiliary signals, or strong inductive biases. In this work, we propose the Latent Additive Noise Model Causal Autoencoder (LANCA) to operationalize the Additive Noise Model (ANM) as a strong inductive bias for unsupervised discovery. Theoretically, we prove that while the ANM constraint does not guarantee unique identifiability in the general mixing case, it resolves component-wise indeterminacy by restricting the admissible transformations from arbitrary diffeomorphisms to the affine class. Methodologically, arguing that the stochastic encoding inherent to VAEs obscures the structural residuals required for latent causal discovery, LANCA employs a deterministic Wasserstein Auto-Encoder (WAE) coupled with a differentiable ANM Layer. This architecture transforms residual independence from a passive assumption into an explicit optimization objective. Empirically, LANCA outperforms state-of-the-art baselines on synthetic physics benchmarks (Pendulum, Flow), and on photorealistic environments (CANDLE), where it demonstrates superior robustness to spurious correlations arising from complex background scenes.
Causal Discovery and Counterfactual Reasoning to Optimize Persuasive Dialogue Policies
Mar 19, 2025Tailoring persuasive conversations to users leads to more effective persuasion. However, existing dialogue systems often struggle to adapt to dynamically evolving user states. This paper presents a novel method that leverages causal discovery and counterfactual reasoning for optimizing system persuasion capability and outcomes. We employ the Greedy Relaxation of the Sparsest Permutation (GRaSP) algorithm to identify causal relationships between user and system utterance strategies, treating user strategies as states and system strategies as actions. GRaSP identifies user strategies as causal factors influencing system responses, which inform Bidirectional Conditional Generative Adversarial Networks (BiCoGAN) in generating counterfactual utterances for the system. Subsequently, we use the Dueling Double Deep Q-Network (D3QN) model to utilize counterfactual data to determine the best policy for selecting system utterances. Our experiments with the PersuasionForGood dataset show measurable improvements in persuasion outcomes using our approach over baseline methods. The observed increase in cumulative rewards and Q-values highlights the effectiveness of causal discovery in enhancing counterfactual reasoning and optimizing reinforcement learning policies for online dialogue systems.
Metric Learning with Progressive Self-Distillation for Audio-Visual Embedding Learning
Jan 16, 2025Metric learning projects samples into an embedded space, where similarities and dissimilarities are quantified based on their learned representations. However, existing methods often rely on label-guided representation learning, where representations of different modalities, such as audio and visual data, are aligned based on annotated labels. This approach tends to underutilize latent complex features and potential relationships inherent in the distributions of audio and visual data that are not directly tied to the labels, resulting in suboptimal performance in audio-visual embedding learning. To address this issue, we propose a novel architecture that integrates cross-modal triplet loss with progressive self-distillation. Our method enhances representation learning by leveraging inherent distributions and dynamically refining soft audio-visual alignments -- probabilistic alignments between audio and visual data that capture the inherent relationships beyond explicit labels. Specifically, the model distills audio-visual distribution-based knowledge from annotated labels in a subset of each batch. This self-distilled knowledge is used t
Zero-shot Persuasive Chatbots with LLM-Generated Strategies and Information Retrieval
Jul 04, 2024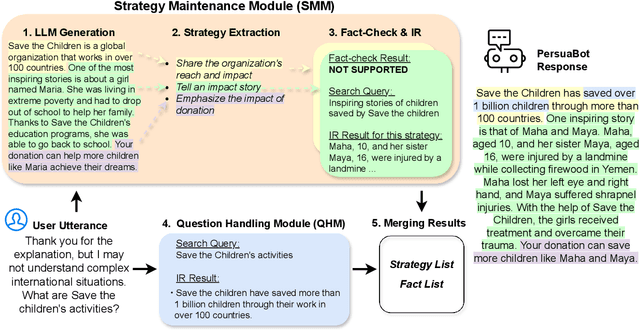
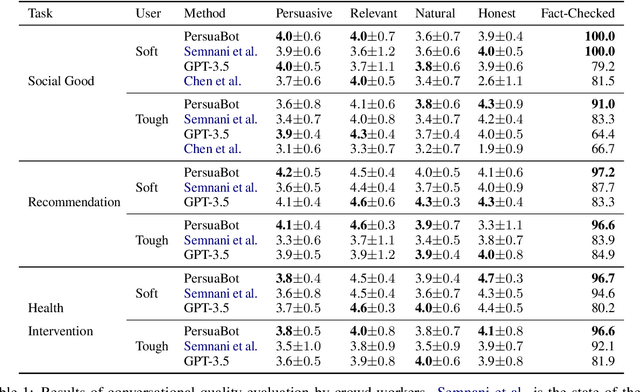
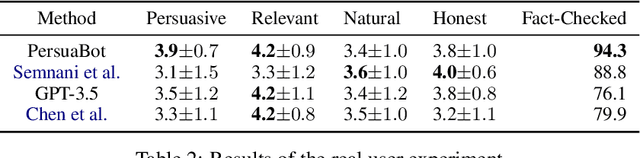
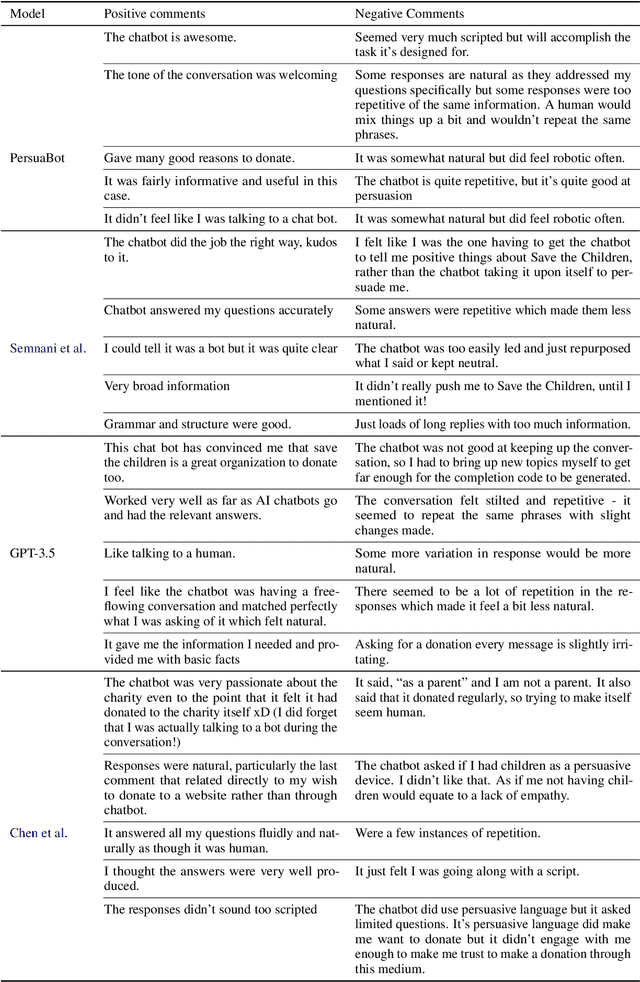
Persuasion plays a pivotal role in a wide range of applications from health intervention to the promotion of social good. Persuasive chatbots can accelerate the positive effects of persuasion in such applications. Existing methods rely on fine-tuning persuasive chatbots with task-specific training data which is costly, if not infeasible, to collect. To address this issue, we propose a method to leverage the generalizability and inherent persuasive abilities of large language models (LLMs) in creating effective and truthful persuasive chatbot for any given domain in a zero-shot manner. Unlike previous studies which used pre-defined persuasion strategies, our method first uses an LLM to generate responses, then extracts the strategies used on the fly, and replaces any unsubstantiated claims in the response with retrieved facts supporting the strategies. We applied our chatbot, PersuaBot, to three significantly different domains needing persuasion skills: donation solicitation, recommendations, and health intervention. Our experiments on simulated and human conversations show that our zero-shot approach is more persuasive than prior work, while achieving factual accuracy surpassing state-of-the-art knowledge-oriented chatbots. Our study demonstrated that when persuasive chatbots are employed responsibly for social good, it is an enabler of positive individual and social change.
Counterfactual Reasoning Using Predicted Latent Personality Dimensions for Optimizing Persuasion Outcome
Apr 21, 2024Customizing persuasive conversations related to the outcome of interest for specific users achieves better persuasion results. However, existing persuasive conversation systems rely on persuasive strategies and encounter challenges in dynamically adjusting dialogues to suit the evolving states of individual users during interactions. This limitation restricts the system's ability to deliver flexible or dynamic conversations and achieve suboptimal persuasion outcomes. In this paper, we present a novel approach that tracks a user's latent personality dimensions (LPDs) during ongoing persuasion conversation and generates tailored counterfactual utterances based on these LPDs to optimize the overall persuasion outcome. In particular, our proposed method leverages a Bi-directional Generative Adversarial Network (BiCoGAN) in tandem with a Dialogue-based Personality Prediction Regression (DPPR) model to generate counterfactual data. This enables the system to formulate alternative persuasive utterances that are more suited to the user. Subsequently, we utilize the D3QN model to learn policies for optimized selection of system utterances on counterfactual data. Experimental results we obtained from using the PersuasionForGood dataset demonstrate the superiority of our approach over the existing method, BiCoGAN. The cumulative rewards and Q-values produced by our method surpass ground truth benchmarks, showcasing the efficacy of employing counterfactual reasoning and LPDs to optimize reinforcement learning policy in online interactions.
Anchor-aware Deep Metric Learning for Audio-visual Retrieval
Apr 21, 2024Metric learning minimizes the gap between similar (positive) pairs of data points and increases the separation of dissimilar (negative) pairs, aiming at capturing the underlying data structure and enhancing the performance of tasks like audio-visual cross-modal retrieval (AV-CMR). Recent works employ sampling methods to select impactful data points from the embedding space during training. However, the model training fails to fully explore the space due to the scarcity of training data points, resulting in an incomplete representation of the overall positive and negative distributions. In this paper, we propose an innovative Anchor-aware Deep Metric Learning (AADML) method to address this challenge by uncovering the underlying correlations among existing data points, which enhances the quality of the shared embedding space. Specifically, our method establishes a correlation graph-based manifold structure by considering the dependencies between each sample as the anchor and its semantically similar samples. Through dynamic weighting of the correlations within this underlying manifold structure using an attention-driven mechanism, Anchor Awareness (AA) scores are obtained for each anchor. These AA scores serve as data proxies to compute relative distances in metric learning approaches. Extensive experiments conducted on two audio-visual benchmark datasets demonstrate the effectiveness of our proposed AADML method, significantly surpassing state-of-the-art models. Furthermore, we investigate the integration of AA proxies with various metric learning methods, further highlighting the efficacy of our approach.
Two-Stage Triplet Loss Training with Curriculum Augmentation for Audio-Visual Retrieval
Oct 20, 2023The cross-modal retrieval model leverages the potential of triple loss optimization to learn robust embedding spaces. However, existing methods often train these models in a singular pass, overlooking the distinction between semi-hard and hard triples in the optimization process. The oversight of not distinguishing between semi-hard and hard triples leads to suboptimal model performance. In this paper, we introduce a novel approach rooted in curriculum learning to address this problem. We propose a two-stage training paradigm that guides the model's learning process from semi-hard to hard triplets. In the first stage, the model is trained with a set of semi-hard triplets, starting from a low-loss base. Subsequently, in the second stage, we augment the embeddings using an interpolation technique. This process identifies potential hard negatives, alleviating issues arising from high-loss functions due to a scarcity of hard triples. Our approach then applies hard triplet mining in the augmented embedding space to further optimize the model. Extensive experimental results conducted on two audio-visual datasets show a significant improvement of approximately 9.8% in terms of average Mean Average Precision (MAP) over the current state-of-the-art method, MSNSCA, for the Audio-Visual Cross-Modal Retrieval (AV-CMR) task on the AVE dataset, indicating the effectiveness of our proposed method.
Topic-switch adapted Japanese Dialogue System based on PLATO-2
Feb 22, 2023Large-scale open-domain dialogue systems such as PLATO-2 have achieved state-of-the-art scores in both English and Chinese. However, little work explores whether such dialogue systems also work well in the Japanese language. In this work, we create a large-scale Japanese dialogue dataset, Dialogue-Graph, which contains 1.656 million dialogue data in a tree structure from News, TV subtitles, and Wikipedia corpus. Then, we train PLATO-2 using Dialogue-Graph to build a large-scale Japanese dialogue system, PLATO-JDS. In addition, to improve the PLATO-JDS in the topic switch issue, we introduce a topic-switch algorithm composed of a topic discriminator to switch to a new topic when user input differs from the previous topic. We evaluate the user experience by using our model with respect to four metrics, namely, coherence, informativeness, engagingness, and humanness. As a result, our proposed PLATO-JDS achieves an average score of 1.500 for the human evaluation with human-bot chat strategy, which is close to the maximum score of 2.000 and suggests the high-quality dialogue generation capability of PLATO-2 in Japanese. Furthermore, our proposed topic-switch algorithm achieves an average score of 1.767 and outperforms PLATO-JDS by 0.267, indicating its effectiveness in improving the user experience of our system.