 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-object event graph representation learning for Video Question Answering
Sep 12, 2024Video question answering (VideoQA) is a task to predict the correct answer to questions posed about a given video. The system must comprehend spatial and temporal relationships among objects extracted from videos to perform causal and temporal reasoning. While prior works have focused on modeling individual object movements using transformer-based methods, they falter when capturing complex scenarios involving multiple objects (e.g., "a boy is throwing a ball in a hoop"). We propose a contrastive language event graph representation learning method called CLanG to address this limitation. Aiming to capture event representations associated with multiple objects, our method employs a multi-layer GNN-cluster module for adversarial graph representation learning, enabling contrastive learning between the question text and its relevant multi-object event graph. Our method outperforms a strong baseline, achieving up to 2.2% higher accuracy on two challenging VideoQA datasets, NExT-QA and TGIF-QA-R. In particular, it is 2.8% better than baselines in handling causal and temporal questions, highlighting its strength in reasoning multiple object-based events.
Top-down Activity Representation Learning for Video Question Answering
Sep 12, 2024Capturing complex hierarchical human activities, from atomic actions (e.g., picking up one present, moving to the sofa, unwrapping the present) to contextual events (e.g., celebrating Christmas) is crucial for achieving high-performance video question answering (VideoQA). Recent works have expanded multimodal models (e.g., CLIP, LLaVA) to process continuous video sequences, enhancing the model's temporal reasoning capabilities. However, these approaches often fail to capture contextual events that can be decomposed into multiple atomic actions non-continuously distributed over relatively long-term sequences. In this paper, to leverage the spatial visual context representation capability of the CLIP model for obtaining non-continuous visual representations in terms of contextual events in videos, we convert long-term video sequences into a spatial image domain and finetune the multimodal model LLaVA for the VideoQA task. Our approach achieves competitive performance on the STAR task, in particular, with a 78.4% accuracy score, exceeding the current state-of-the-art score by 2.8 points on the NExTQA task.
Zero-shot Persuasive Chatbots with LLM-Generated Strategies and Information Retrieval
Jul 04, 2024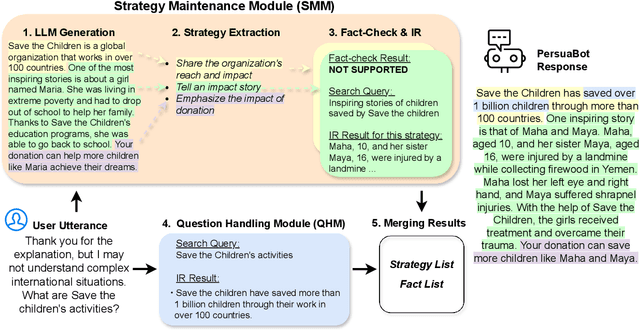
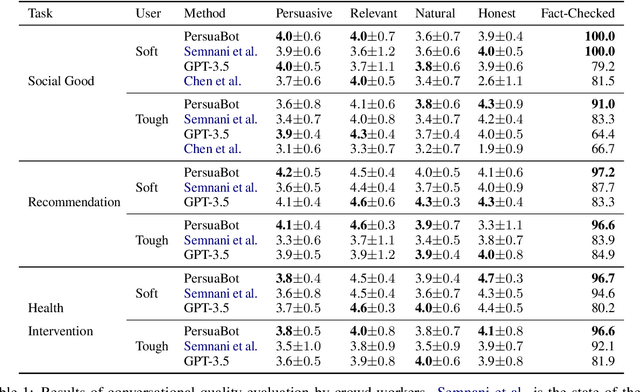
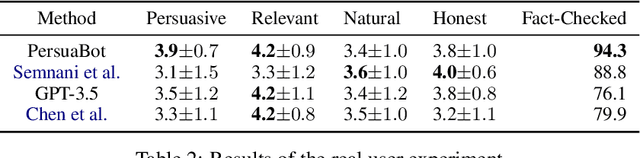
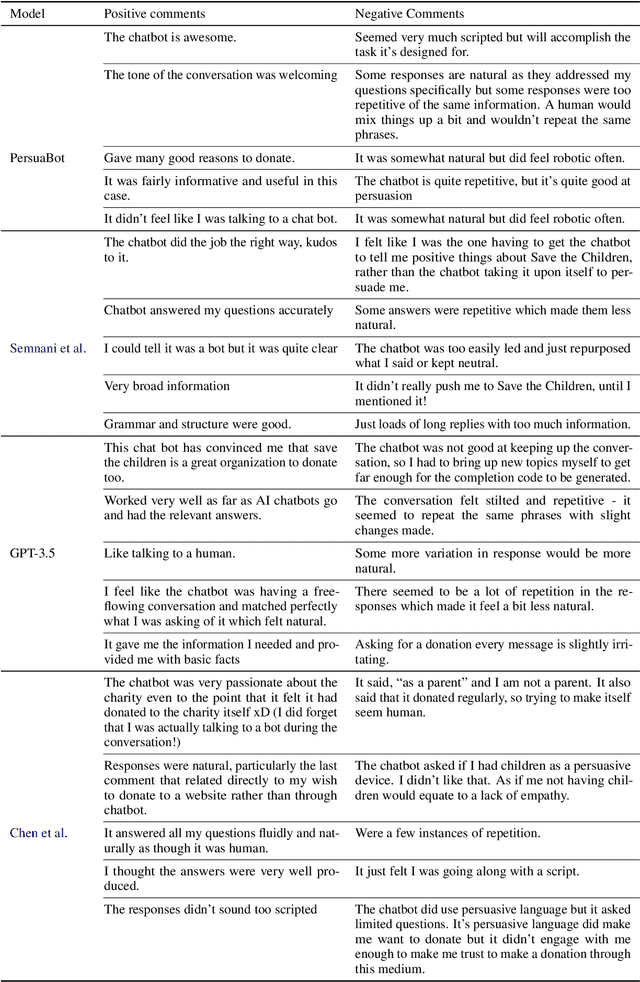
Persuasion plays a pivotal role in a wide range of applications from health intervention to the promotion of social good. Persuasive chatbots can accelerate the positive effects of persuasion in such applications. Existing methods rely on fine-tuning persuasive chatbots with task-specific training data which is costly, if not infeasible, to collect. To address this issue, we propose a method to leverage the generalizability and inherent persuasive abilities of large language models (LLMs) in creating effective and truthful persuasive chatbot for any given domain in a zero-shot manner. Unlike previous studies which used pre-defined persuasion strategies, our method first uses an LLM to generate responses, then extracts the strategies used on the fly, and replaces any unsubstantiated claims in the response with retrieved facts supporting the strategies. We applied our chatbot, PersuaBot, to three significantly different domains needing persuasion skills: donation solicitation, recommendations, and health intervention. Our experiments on simulated and human conversations show that our zero-shot approach is more persuasive than prior work, while achieving factual accuracy surpassing state-of-the-art knowledge-oriented chatbots. Our study demonstrated that when persuasive chatbots are employed responsibly for social good, it is an enabler of positive individual and social change.