 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataSTORM: Deep Research on Large-Scale Databases using Exploratory Data Analysis and Data Storytelling
Apr 07, 2026Deep research with Large Language Model (LLM) agents is emerging as a powerful paradigm for multi-step information discovery, synthesis, and analysis. However, existing approaches primarily focus on unstructured web data, while the challenges of conducting deep research over large-scale structured databases remain relatively underexplored. Unlike web-based research, effective data-centric research requires more than retrieval and summarization and demands iterative hypothesis generation, quantitative reasoning over structured schemas, and convergence toward a coherent analytical narrative. In this paper, we present DataSTORM, an LLM-based agentic system capable of autonomously conducting research across both large-scale structured databases and internet sources. Grounded in principles from Exploratory Data Analysis and Data Storytelling, DataSTORM reframes deep research over structured data as a thesis-driven analytical process: discovering candidate theses from data, validating them through iterative cross-source investigation, and developing them into coherent analytical narratives. We evaluate DataSTORM on InsightBench, where it achieves a new state-of-the-art result with a 19.4% relative improvement in insight-level recall and 7.2% in summary-level score. We further introduce a new dataset built on ACLED, a real-world complex database, and demonstrate that DataSTORM outperforms proprietary systems such as ChatGPT Deep Research across both automated metrics and human evaluations.
Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations
Aug 27, 2024While language model (LM)-powered chatbots and generative search engines excel at answering concrete queries, discovering information in the terrain of unknown unknowns remains challenging for users. To emulate the common educational scenario where children/students learn by listening to and participating in conversations of their parents/teachers, we create Collaborative STORM (Co-STORM). Unlike QA systems that require users to ask all the questions, Co-STORM lets users observe and occasionally steer the discourse among several LM agents. The agents ask questions on the user's behalf, allowing the user to discover unknown unknowns serendipitously. To facilitate user interaction, Co-STORM assists users in tracking the discourse by organizing the uncovered information into a dynamic mind map, ultimately generating a comprehensive report as takeaways. For automatic evaluation, we construct the WildSeek dataset by collecting real information-seeking records with user goals. Co-STORM outperforms baseline methods on both discourse trace and report quality. In a further human evaluation, 70% of participants prefer Co-STORM over a search engine, and 78% favor it over a RAG chatbot.
SPINACH: SPARQL-Based Information Navigation for Challenging Real-World Questions
Jul 16, 2024

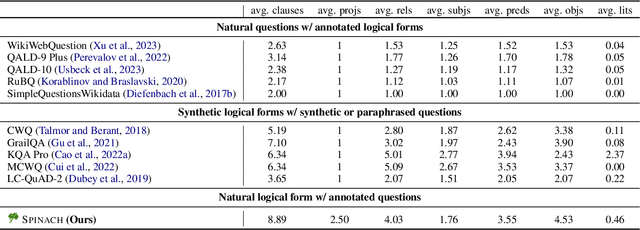
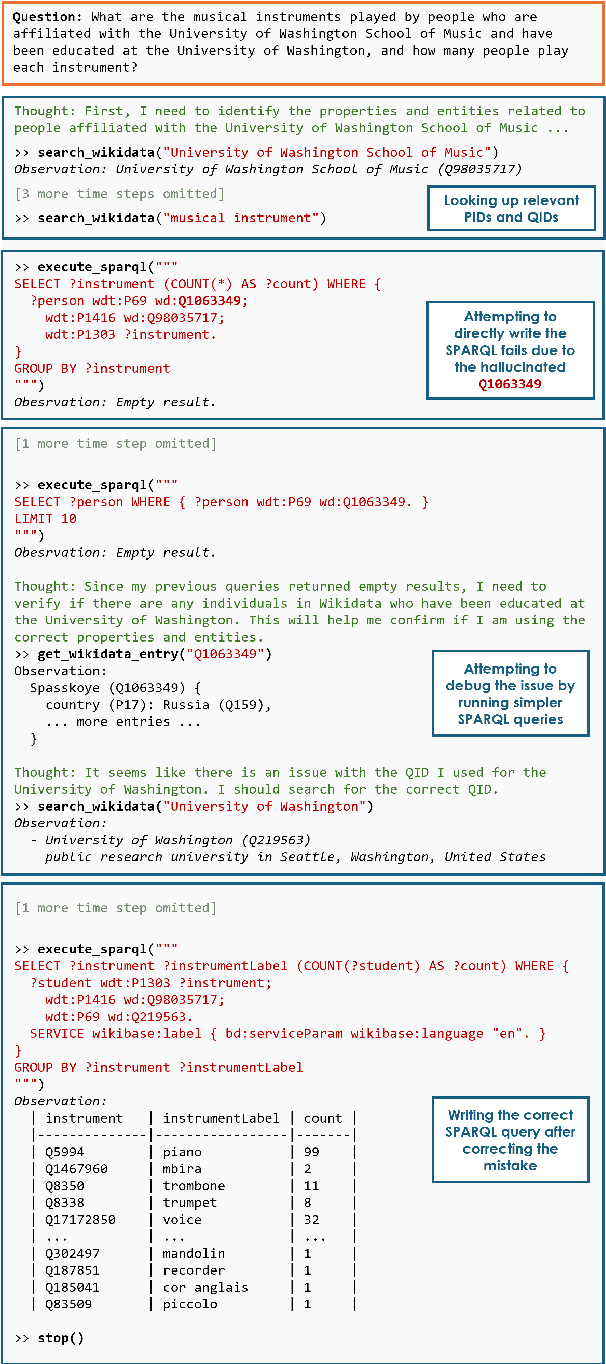
Recent work integrating Large Language Models (LLMs) has led to significant improvements in the Knowledge Base Question Answering (KBQA) task. However, we posit that existing KBQA datasets that either have simple questions, use synthetically generated logical forms, or are based on small knowledge base (KB) schemas, do not capture the true complexity of KBQA tasks. To address this, we introduce the SPINACH dataset, an expert-annotated KBQA dataset collected from forum discussions on Wikidata's "Request a Query" forum with 320 decontextualized question-SPARQL pairs. Much more complex than existing datasets, SPINACH calls for strong KBQA systems that do not rely on training data to learn the KB schema, but can dynamically explore large and often incomplete schemas and reason about them. Along with the dataset, we introduce the SPINACH agent, a new KBQA approach that mimics how a human expert would write SPARQLs for such challenging questions. Experiments on existing datasets show SPINACH's capability in KBQA, achieving a new state of the art on the QALD-7, QALD-9 Plus and QALD-10 datasets by 30.1%, 27.0%, and 10.0% in F1, respectively, and coming within 1.6% of the fine-tuned LLaMA SOTA model on WikiWebQuestions. On our new SPINACH dataset, SPINACH agent outperforms all baselines, including the best GPT-4-based KBQA agent, by 38.1% in F1.
LLM-Based Open-Domain Integrated Task and Knowledge Assistants with Programmable Policies
Jul 08, 2024



Programming LLM-based knowledge and task assistants that faithfully conform to developer-provided policies is challenging. These agents must retrieve and provide consistent, accurate, and relevant information to address user's queries and needs. Yet such agents generate unfounded responses ("hallucinate"). Traditional dialogue trees can only handle a limited number of conversation flows, making them inherently brittle. To this end, we present KITA - a programmable framework for creating task-oriented conversational agents that are designed to handle complex user interactions. Unlike LLMs, KITA provides reliable grounded responses, with controllable agent policies through its expressive specification, KITA Worksheet. In contrast to dialog trees, it is resilient to diverse user queries, helpful with knowledge sources, and offers ease of programming policies through its declarative paradigm. Through a real-user study involving 62 participants, we show that KITA beats the GPT-4 with function calling baseline by 26.1, 22.5, and 52.4 points on execution accuracy, dialogue act accuracy, and goal completion rate, respectively. We also release 22 real-user conversations with KITA manually corrected to ensure accuracy.
Zero-shot Persuasive Chatbots with LLM-Generated Strategies and Information Retrieval
Jul 04, 2024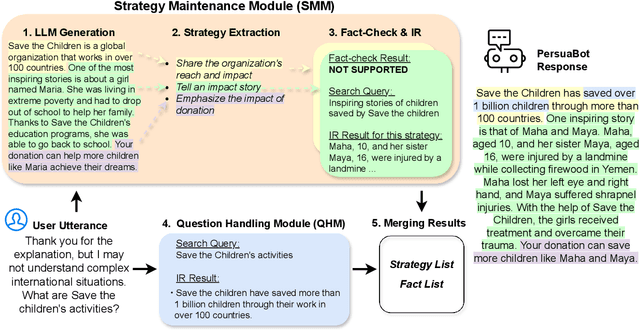
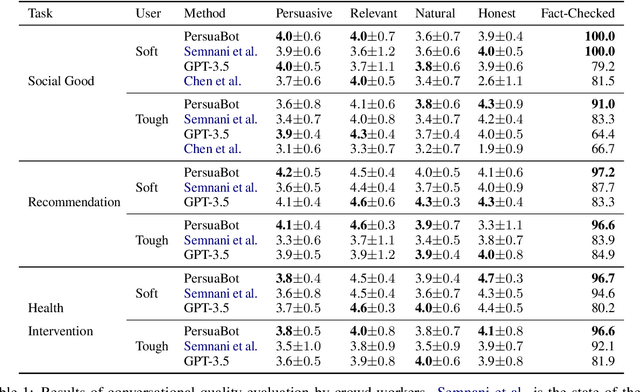
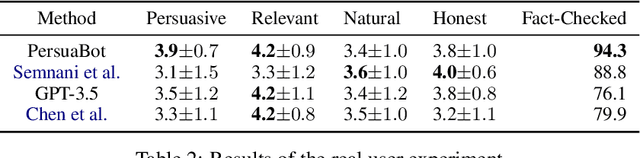
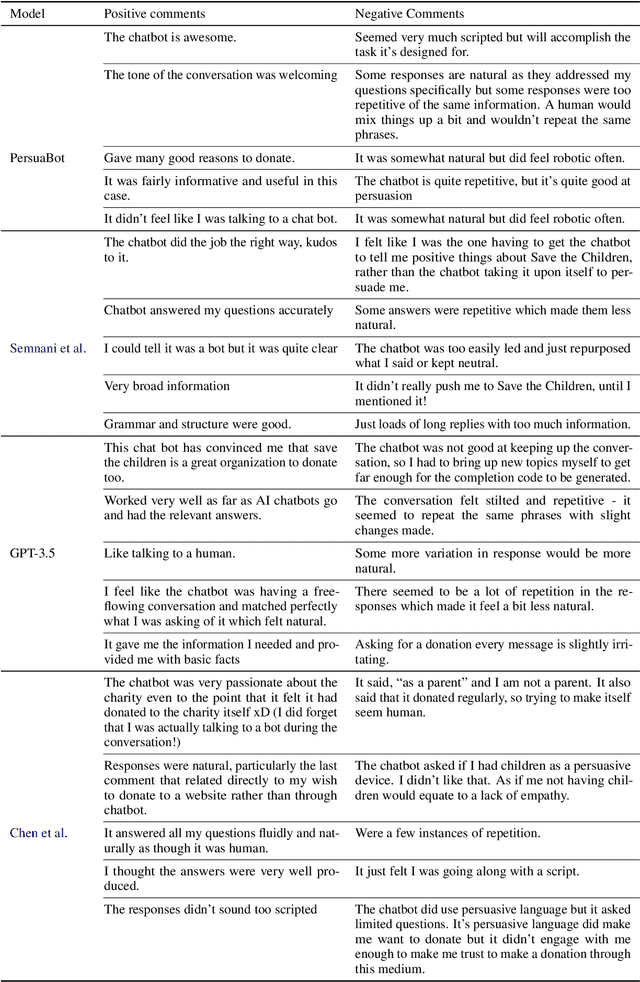
Persuasion plays a pivotal role in a wide range of applications from health intervention to the promotion of social good. Persuasive chatbots can accelerate the positive effects of persuasion in such applications. Existing methods rely on fine-tuning persuasive chatbots with task-specific training data which is costly, if not infeasible, to collect. To address this issue, we propose a method to leverage the generalizability and inherent persuasive abilities of large language models (LLMs) in creating effective and truthful persuasive chatbot for any given domain in a zero-shot manner. Unlike previous studies which used pre-defined persuasion strategies, our method first uses an LLM to generate responses, then extracts the strategies used on the fly, and replaces any unsubstantiated claims in the response with retrieved facts supporting the strategies. We applied our chatbot, PersuaBot, to three significantly different domains needing persuasion skills: donation solicitation, recommendations, and health intervention. Our experiments on simulated and human conversations show that our zero-shot approach is more persuasive than prior work, while achieving factual accuracy surpassing state-of-the-art knowledge-oriented chatbots. Our study demonstrated that when persuasive chatbots are employed responsibly for social good, it is an enabler of positive individual and social change.
SPAGHETTI: Open-Domain Question Answering from Heterogeneous Data Sources with Retrieval and Semantic Parsing
Jun 01, 2024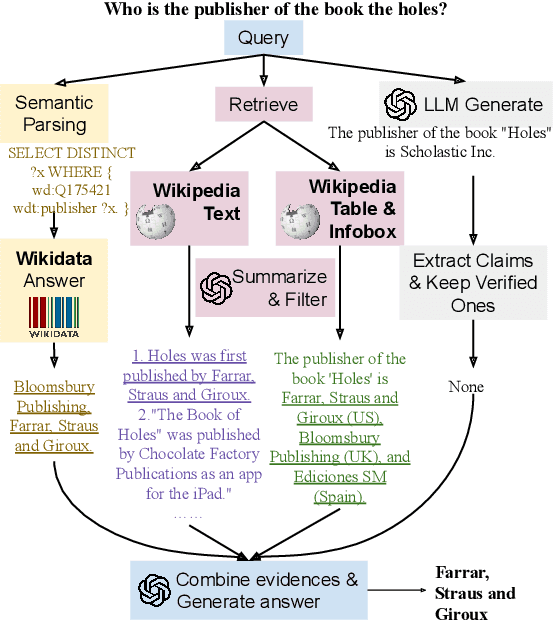
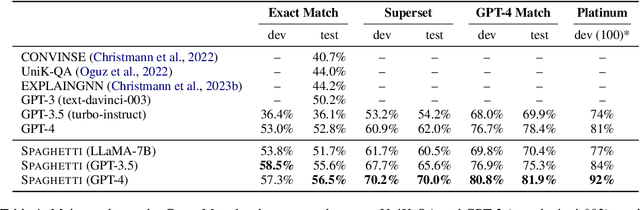


We introduce SPAGHETTI: Semantic Parsing Augmented Generation for Hybrid English information from Text Tables and Infoboxes, a hybrid question-answering (QA) pipeline that utilizes information from heterogeneous knowledge sources, including knowledge base, text, tables, and infoboxes. Our LLM-augmented approach achieves state-of-the-art performance on the Compmix dataset, the most comprehensive heterogeneous open-domain QA dataset, with 56.5% exact match (EM) rate. More importantly, manual analysis on a sample of the dataset suggests that SPAGHETTI is more than 90% accurate, indicating that EM is no longer suitable for assessing the capabilities of QA systems today.
Benchmark Underestimates the Readiness of Multi-lingual Dialogue Agents
May 28, 2024



Creating multilingual task-oriented dialogue (TOD) agents is challenging due to the high cost of training data acquisition. Following the research trend of improving training data efficiency, we show for the first time, that in-context learning is sufficient to tackle multilingual TOD. To handle the challenging dialogue state tracking (DST) subtask, we break it down to simpler steps that are more compatible with in-context learning where only a handful of few-shot examples are used. We test our approach on the multilingual TOD dataset X-RiSAWOZ, which has 12 domains in Chinese, English, French, Korean, Hindi, and code-mixed Hindi-English. Our turn-by-turn DST accuracy on the 6 languages range from 55.6% to 80.3%, seemingly worse than the SOTA results from fine-tuned models that achieve from 60.7% to 82.8%; our BLEU scores in the response generation (RG) subtask are also significantly lower than SOTA. However, after manual evaluation of the validation set, we find that by correcting gold label errors and improving dataset annotation schema, GPT-4 with our prompts can achieve (1) 89.6%-96.8% accuracy in DST, and (2) more than 99% correct response generation across different languages. This leads us to conclude that current automatic metrics heavily underestimate the effectiveness of in-context learning.
Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models
Feb 22, 2024We study how to apply large language models to write grounded and organized long-form articles from scratch, with comparable breadth and depth to Wikipedia pages. This underexplored problem poses new challenges at the pre-writing stage, including how to research the topic and prepare an outline prior to writing. We propose STORM, a writing system for the Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking. STORM models the pre-writing stage by (1) discovering diverse perspectives in researching the given topic, (2) simulating conversations where writers carrying different perspectives pose questions to a topic expert grounded on trusted Internet sources, (3) curating the collected information to create an outline. For evaluation, we curate FreshWiki, a dataset of recent high-quality Wikipedia articles, and formulate outline assessments to evaluate the pre-writing stage. We further gather feedback from experienced Wikipedia editors. Compared to articles generated by an outline-driven retrieval-augmented baseline, more of STORM's articles are deemed to be organized (by a 25% absolute increase) and broad in coverage (by 10%). The expert feedback also helps identify new challenges for generating grounded long articles, such as source bias transfer and over-association of unrelated facts.
SUQL: Conversational Search over Structured and Unstructured Data with Large Language Models
Nov 16, 2023



Many knowledge sources consist of both structured information such as relational databases as well as unstructured free text. Building a conversational interface to such data sources is challenging. This paper introduces SUQL, Structured and Unstructured Query Language, the first formal executable representation that naturally covers compositions of structured and unstructured data queries. Specifically, it augments SQL with several free-text primitives to form a precise, succinct, and expressive representation. This paper also presents a conversational search agent based on large language models, including a few-shot contextual semantic parser for SUQL. To validate our approach, we introduce a dataset consisting of crowdsourced questions and conversations about real restaurants. Over 51% of the questions in the dataset require both structured and unstructured data, suggesting that it is a common phenomenon. We show that our few-shot conversational agent based on SUQL finds an entity satisfying all user requirements 89.3% of the time, compared to just 65.0% for a strong and commonly used baseline.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.