 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGround: Universal 3D Visual Grounding via Training-Free Scene Parsing
Mar 09, 2026Understanding and localizing objects in complex 3D environments from natural language descriptions, known as 3D Visual Grounding (3DVG), is a foundational challenge in embodied AI, with broad implications for robotics, augmented reality, and human-machine interaction. Large-scale pre-trained foundation models have driven significant progress on this front, enabling open-vocabulary 3DVG that allows systems to locate arbitrary objects in a given scene. However, their reliance on pre-trained models constrains 3D perception and reasoning within the inherited knowledge boundaries, resulting in limited generalization to unseen spatial relationships and poor robustness to out-of-distribution scenes. In this paper, we replace this constrained perception with training-free visual and geometric reasoning, thereby unlocking open-world 3DVG that enables the localization of any object in any scene beyond the training data. Specifically, the proposed UniGround operates in two stages: a Global Candidate Filtering stage that constructs scene candidates through training-free 3D topology and multi-view semantic encoding, and a Local Precision Grounding stage that leverages multi-scale visual prompting and structured reasoning to precisely identify the target object. Experiments on ScanRefer and EmbodiedScan show that UniGround achieves 46.1\%/34.1\% Acc@0.25/0.5 on ScanRefer and 28.7\% Acc@0.25 on EmbodiedScan, establishing a new state-of-the-art among zero-shot methods on EmbodiedScan without any 3D supervision. We further evaluate UniGround in real-world environments under uncontrolled reconstruction conditions and substantial domain shift, showing training-free reasoning generalizes robustly beyond curated benchmarks.
ModalImmune: Immunity Driven Unlearning via Self Destructive Training
Feb 18, 2026Multimodal systems are vulnerable to partial or complete loss of input channels at deployment, which undermines reliability in real-world settings. This paper presents ModalImmune, a training framework that enforces modality immunity by intentionally and controllably collapsing selected modality information during training so the model learns joint representations that are robust to destructive modality influence. The framework combines a spectrum-adaptive collapse regularizer, an information-gain guided controller for targeted interventions, curvature-aware gradient masking to stabilize destructive updates, and a certified Neumann-truncated hyper-gradient procedure for automatic meta-parameter adaptation. Empirical evaluation on standard multimodal benchmarks demonstrates that ModalImmune improves resilience to modality removal and corruption while retaining convergence stability and reconstruction capacity.
HERO: Hierarchical Traversable 3D Scene Graphs for Embodied Navigation Among Movable Obstacles
Dec 17, 20253D Scene Graphs (3DSGs) constitute a powerful representation of the physical world, distinguished by their abilities to explicitly model the complex spatial, semantic, and functional relationships between entities, rendering a foundational understanding that enables agents to interact intelligently with their environment and execute versatile behaviors. Embodied navigation, as a crucial component of such capabilities, leverages the compact and expressive nature of 3DSGs to enable long-horizon reasoning and planning in complex, large-scale environments. However, prior works rely on a static-world assumption, defining traversable space solely based on static spatial layouts and thereby treating interactable obstacles as non-traversable. This fundamental limitation severely undermines their effectiveness in real-world scenarios, leading to limited reachability, low efficiency, and inferior extensibility. To address these issues, we propose HERO, a novel framework for constructing Hierarchical Traversable 3DSGs, that redefines traversability by modeling operable obstacles as pathways, capturing their physical interactivity, functional semantics, and the scene's relational hierarchy. The results show that, relative to its baseline, HERO reduces PL by 35.1% in partially obstructed environments and increases SR by 79.4% in fully obstructed ones, demonstrating substantially higher efficiency and reachability.
ReactGenie: An Object-Oriented State Abstraction for Complex Multimodal Interactions Using Large Language Models
Jun 16, 2023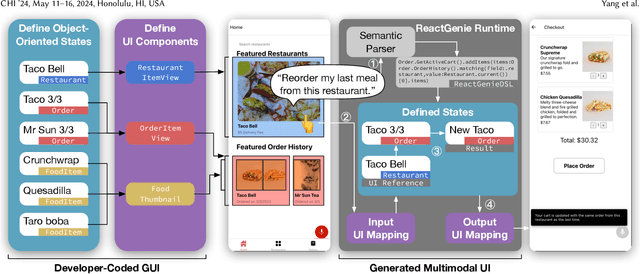



Multimodal interactions have been shown to be more flexible, efficient, and adaptable for diverse users and tasks than traditional graphical interfaces. However, existing multimodal development frameworks either do not handle the complexity and compositionality of multimodal commands well or require developers to write a substantial amount of code to support these multimodal interactions. In this paper, we present ReactGenie, a programming framework that uses a shared object-oriented state abstraction to support building complex multimodal mobile applications. Having different modalities share the same state abstraction allows developers using ReactGenie to seamlessly integrate and compose these modalities to deliver multimodal interaction. ReactGenie is a natural extension to the existing workflow of building a graphical app, like the workflow with React-Redux. Developers only have to add a few annotations and examples to indicate how natural language is mapped to the user-accessible functions in the program. ReactGenie automatically handles the complex problem of understanding natural language by generating a parser that leverages large language models. We evaluated the ReactGenie framework by using it to build three demo apps. We evaluated the accuracy of the language parser using elicited commands from crowd workers and evaluated the usability of the generated multimodal app with 16 participants. Our results show that ReactGenie can be used to build versatile multimodal applications with highly accurate language parsers, and the multimodal app can lower users' cognitive load and task completion time.
A Simple and Unified Tagging Model with Priming for Relational Structure Predictions
May 25, 2022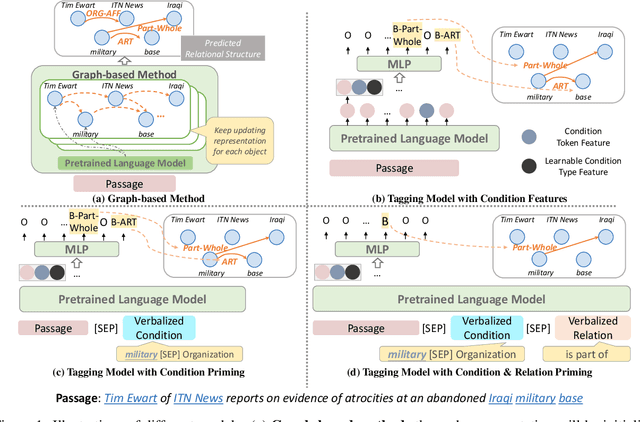
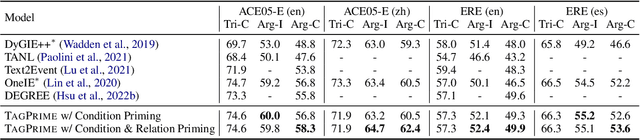
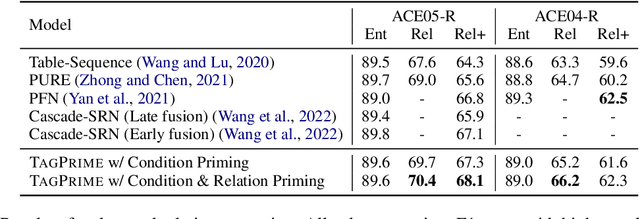
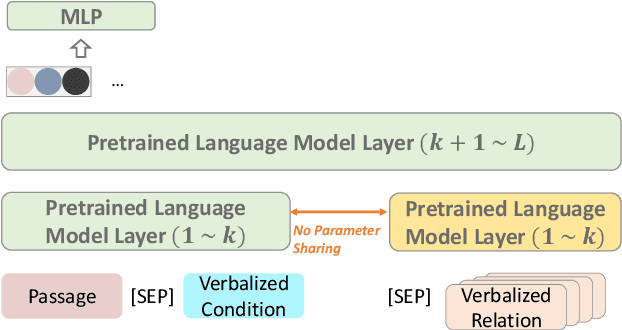
Relational structure extraction covers a wide range of tasks and plays an important role in natural language processing. Recently, many approaches tend to design sophisticated graphical models to capture the complex relations between objects that are described in a sentence. In this work, we demonstrate that simple tagging models can surprisingly achieve competitive performances with a small trick -- priming. Tagging models with priming append information about the operated objects to the input sequence of pretrained language model. Making use of the contextualized nature of pretrained language model, the priming approach help the contextualized representation of the sentence better embed the information about the operated objects, hence, becomes more suitable for addressing relational structure extraction. We conduct extensive experiments on three different tasks that span ten datasets across five different languages, and show that our model is a general and effective model, despite its simplicity. We further carry out comprehensive analysis to understand our model and propose an efficient approximation to our method, which can perform almost the same performance but with faster inference speed.