 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactGenie: An Object-Oriented State Abstraction for Complex Multimodal Interactions Using Large Language Models
Jun 16, 2023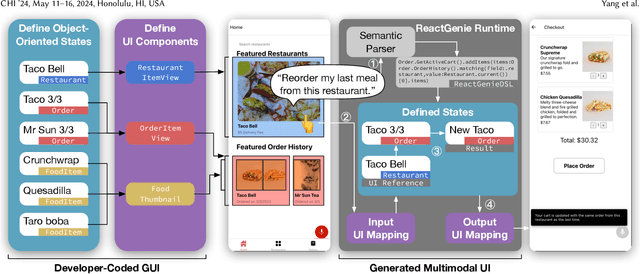



Multimodal interactions have been shown to be more flexible, efficient, and adaptable for diverse users and tasks than traditional graphical interfaces. However, existing multimodal development frameworks either do not handle the complexity and compositionality of multimodal commands well or require developers to write a substantial amount of code to support these multimodal interactions. In this paper, we present ReactGenie, a programming framework that uses a shared object-oriented state abstraction to support building complex multimodal mobile applications. Having different modalities share the same state abstraction allows developers using ReactGenie to seamlessly integrate and compose these modalities to deliver multimodal interaction. ReactGenie is a natural extension to the existing workflow of building a graphical app, like the workflow with React-Redux. Developers only have to add a few annotations and examples to indicate how natural language is mapped to the user-accessible functions in the program. ReactGenie automatically handles the complex problem of understanding natural language by generating a parser that leverages large language models. We evaluated the ReactGenie framework by using it to build three demo apps. We evaluated the accuracy of the language parser using elicited commands from crowd workers and evaluated the usability of the generated multimodal app with 16 participants. Our results show that ReactGenie can be used to build versatile multimodal applications with highly accurate language parsers, and the multimodal app can lower users' cognitive load and task completion time.
Model Sketching: Centering Concepts in Early-Stage Machine Learning Model Design
Mar 06, 2023



Machine learning practitioners often end up tunneling on low-level technical details like model architectures and performance metrics. Could early model development instead focus on high-level questions of which factors a model ought to pay attention to? Inspired by the practice of sketching in design, which distills ideas to their minimal representation, we introduce model sketching: a technical framework for iteratively and rapidly authoring functional approximations of a machine learning model's decision-making logic. Model sketching refocuses practitioner attention on composing high-level, human-understandable concepts that the model is expected to reason over (e.g., profanity, racism, or sarcasm in a content moderation task) using zero-shot concept instantiation. In an evaluation with 17 ML practitioners, model sketching reframed thinking from implementation to higher-level exploration, prompted iteration on a broader range of model designs, and helped identify gaps in the problem formulation$\unicode{x2014}$all in a fraction of the time ordinarily required to build a model.
Towards a Drone Cinematographer: Guiding Quadrotor Cameras using Visual Composition Principles
Oct 05, 2016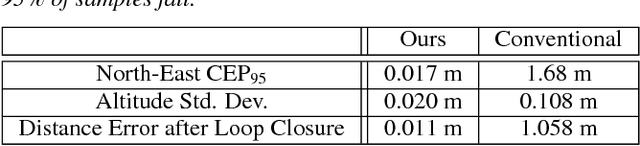

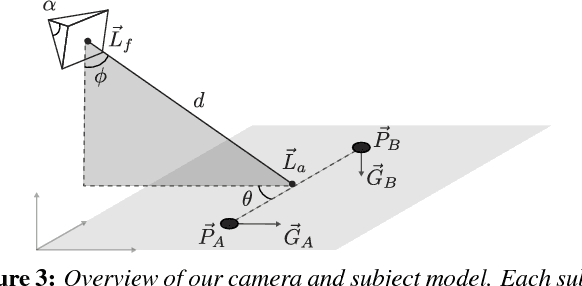
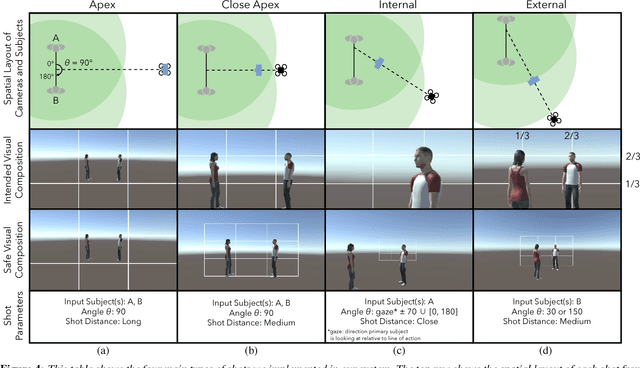
We present a system to capture video footage of human subjects in the real world. Our system leverages a quadrotor camera to automatically capture well-composed video of two subjects. Subjects are tracked in a large-scale outdoor environment using RTK GPS and IMU sensors. Then, given the tracked state of our subjects, our system automatically computes static shots based on well-established visual composition principles and canonical shots from cinematography literature. To transition between these static shots, we calculate feasible, safe, and visually pleasing transitions using a novel real-time trajectory planning algorithm. We evaluate the performance of our tracking system, and experimentally show that RTK GPS significantly outperforms conventional GPS in capturing a variety of canonical shots. Lastly, we demonstrate our system guiding a consumer quadrotor camera autonomously capturing footage of two subjects in a variety of use cases. This is the first end-to-end system that enables people to leverage the mobility of quadrotors, as well as the knowledge of expert filmmakers, to autonomously capture high-quality footage of people in the real world.