 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePISA Experiments: Exploring Physics Post-Training for Video Diffusion Models by Watching Stuff Drop
Mar 12, 2025
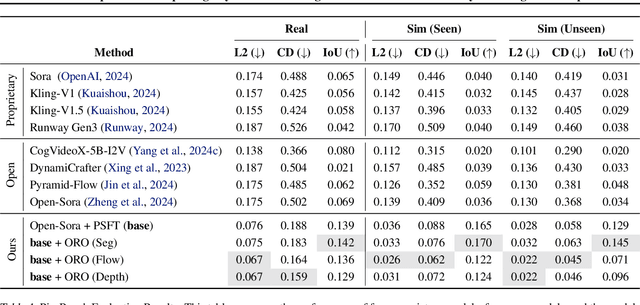
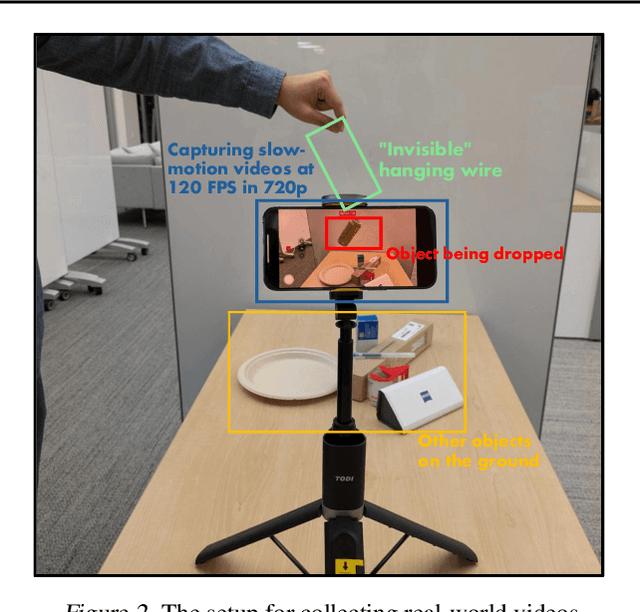

Large-scale pre-trained video generation models excel in content creation but are not reliable as physically accurate world simulators out of the box. This work studies the process of post-training these models for accurate world modeling through the lens of the simple, yet fundamental, physics task of modeling object freefall. We show state-of-the-art video generation models struggle with this basic task, despite their visually impressive outputs. To remedy this problem, we find that fine-tuning on a relatively small amount of simulated videos is effective in inducing the dropping behavior in the model, and we can further improve results through a novel reward modeling procedure we introduce. Our study also reveals key limitations of post-training in generalization and distribution modeling. Additionally, we release a benchmark for this task that may serve as a useful diagnostic tool for tracking physical accuracy in large-scale video generative model development.
When AI Eats Itself: On the Caveats of Data Pollution in the Era of Generative AI
May 15, 2024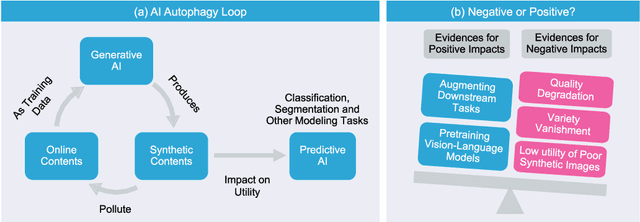
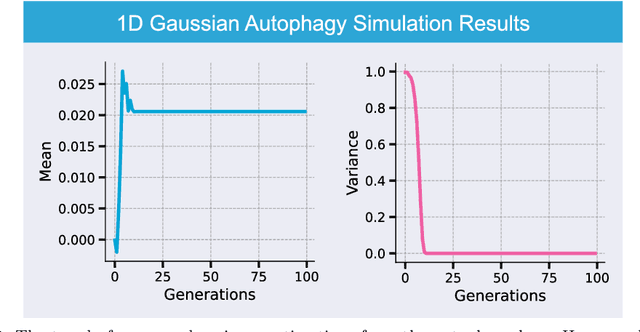
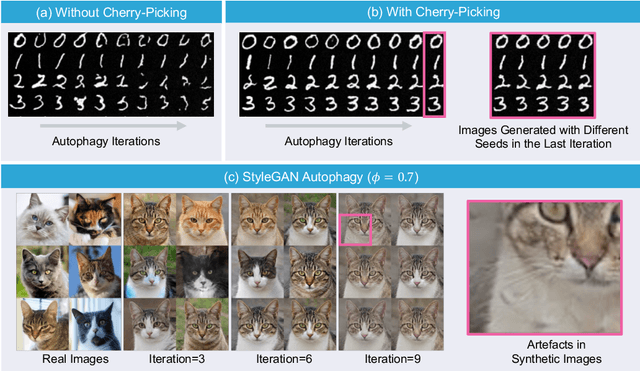

Generative artificial intelligence (AI) technologies and large models are producing realistic outputs across various domains, such as images, text, speech, and music. Creating these advanced generative models requires significant resources, particularly large and high-quality datasets. To minimize training expenses, many algorithm developers use data created by the models themselves as a cost-effective training solution. However, not all synthetic data effectively improve model performance, necessitating a strategic balance in the use of real versus synthetic data to optimize outcomes. Currently, the previously well-controlled integration of real and synthetic data is becoming uncontrollable. The widespread and unregulated dissemination of synthetic data online leads to the contamination of datasets traditionally compiled through web scraping, now mixed with unlabeled synthetic data. This trend portends a future where generative AI systems may increasingly rely blindly on consuming self-generated data, raising concerns about model performance and ethical issues. What will happen if generative AI continuously consumes itself without discernment? What measures can we take to mitigate the potential adverse effects? There is a significant gap in the scientific literature regarding the impact of synthetic data use in generative AI, particularly in terms of the fusion of multimodal information. To address this research gap, this review investigates the consequences of integrating synthetic data blindly on training generative AI on both image and text modalities and explores strategies to mitigate these effects. The goal is to offer a comprehensive view of synthetic data's role, advocating for a balanced approach to its use and exploring practices that promote the sustainable development of generative AI technologies in the era of large models.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

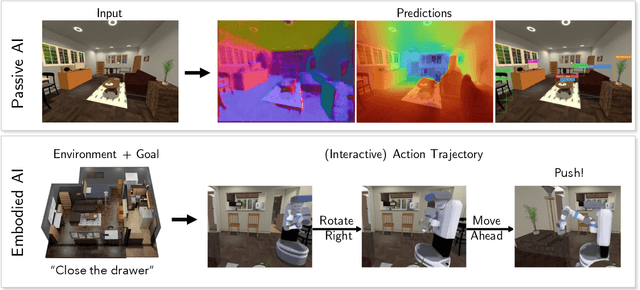
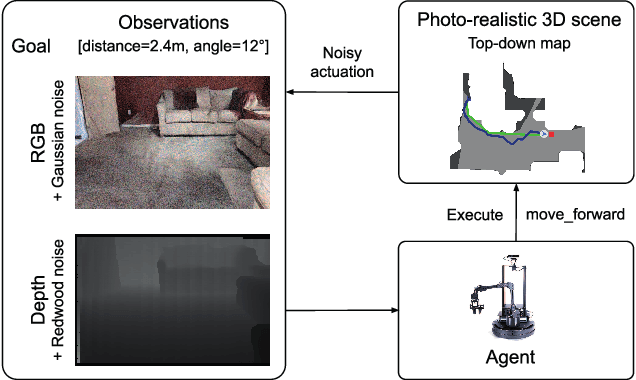
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding
Nov 10, 2020
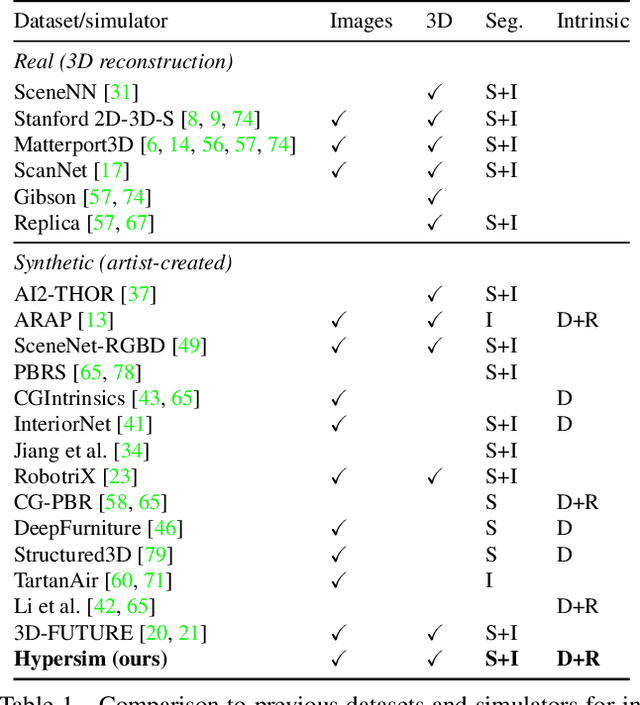

For many fundamental scene understanding tasks, it is difficult or impossible to obtain per-pixel ground truth labels from real images. We address this challenge by introducing Hypersim, a photorealistic synthetic dataset for holistic indoor scene understanding. To create our dataset, we leverage a large repository of synthetic scenes created by professional artists, and we generate 77,400 images of 461 indoor scenes with detailed per-pixel labels and corresponding ground truth geometry. Our dataset: (1) relies exclusively on publicly available 3D assets; (2) includes complete scene geometry, material information, and lighting information for every scene; (3) includes dense per-pixel semantic instance segmentations for every image; and (4) factors every image into diffuse reflectance, diffuse illumination, and a non-diffuse residual term that captures view-dependent lighting effects. Together, these features make our dataset well-suited for geometric learning problems that require direct 3D supervision, multi-task learning problems that require reasoning jointly over multiple input and output modalities, and inverse rendering problems. We analyze our dataset at the level of scenes, objects, and pixels, and we analyze costs in terms of money, annotation effort, and computation time. Remarkably, we find that it is possible to generate our entire dataset from scratch, for roughly half the cost of training a state-of-the-art natural language processing model. All the code we used to generate our dataset will be made available online.
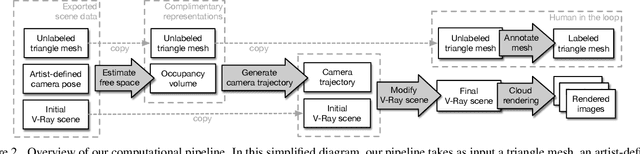
Submodular Trajectory Optimization for Aerial 3D Scanning
Aug 04, 2017
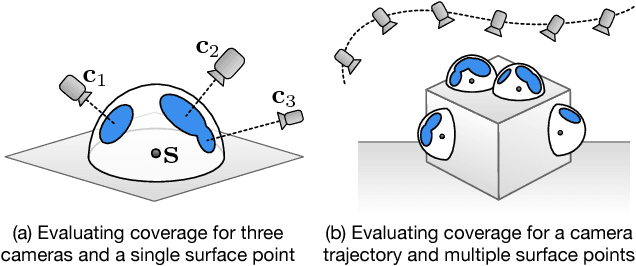
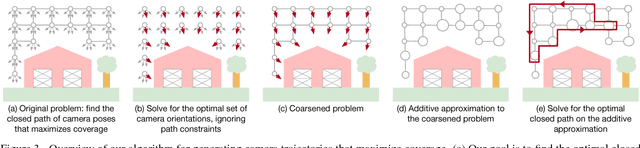

Drones equipped with cameras are emerging as a powerful tool for large-scale aerial 3D scanning, but existing automatic flight planners do not exploit all available information about the scene, and can therefore produce inaccurate and incomplete 3D models. We present an automatic method to generate drone trajectories, such that the imagery acquired during the flight will later produce a high-fidelity 3D model. Our method uses a coarse estimate of the scene geometry to plan camera trajectories that: (1) cover the scene as thoroughly as possible; (2) encourage observations of scene geometry from a diverse set of viewing angles; (3) avoid obstacles; and (4) respect a user-specified flight time budget. Our method relies on a mathematical model of scene coverage that exhibits an intuitive diminishing returns property known as submodularity. We leverage this property extensively to design a trajectory planning algorithm that reasons globally about the non-additive coverage reward obtained across a trajectory, jointly with the cost of traveling between views. We evaluate our method by using it to scan three large outdoor scenes, and we perform a quantitative evaluation using a photorealistic video game simulator.
Towards a Drone Cinematographer: Guiding Quadrotor Cameras using Visual Composition Principles
Oct 05, 2016

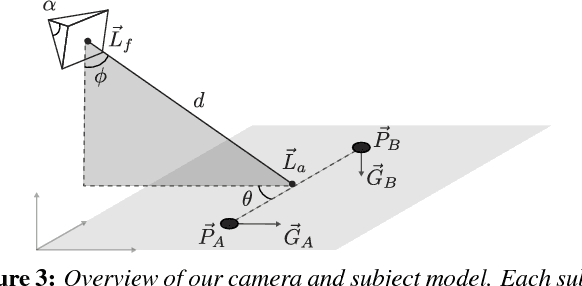
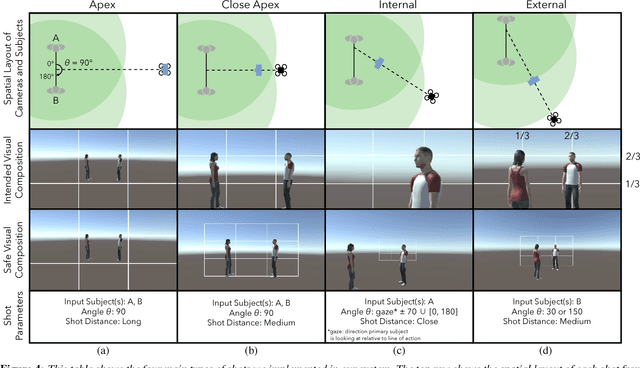
We present a system to capture video footage of human subjects in the real world. Our system leverages a quadrotor camera to automatically capture well-composed video of two subjects. Subjects are tracked in a large-scale outdoor environment using RTK GPS and IMU sensors. Then, given the tracked state of our subjects, our system automatically computes static shots based on well-established visual composition principles and canonical shots from cinematography literature. To transition between these static shots, we calculate feasible, safe, and visually pleasing transitions using a novel real-time trajectory planning algorithm. We evaluate the performance of our tracking system, and experimentally show that RTK GPS significantly outperforms conventional GPS in capturing a variety of canonical shots. Lastly, we demonstrate our system guiding a consumer quadrotor camera autonomously capturing footage of two subjects in a variety of use cases. This is the first end-to-end system that enables people to leverage the mobility of quadrotors, as well as the knowledge of expert filmmakers, to autonomously capture high-quality footage of people in the real world.
Large-Scale Automatic Reconstruction of Neuronal Processes from Electron Microscopy Images
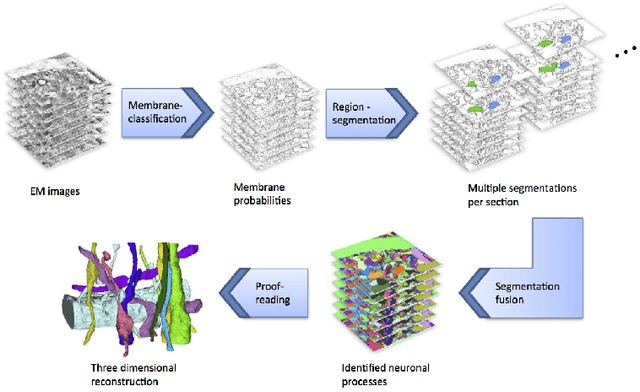
Mar 28, 2013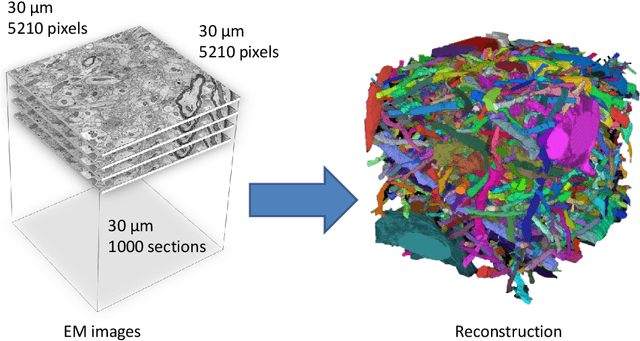
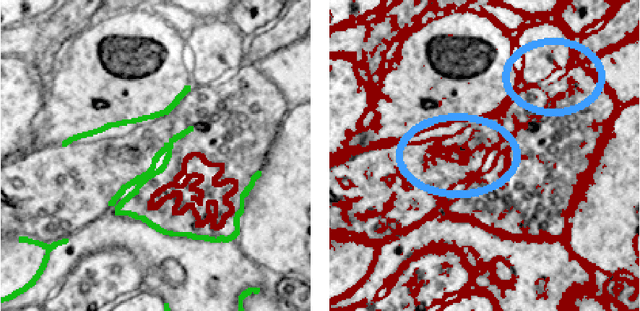
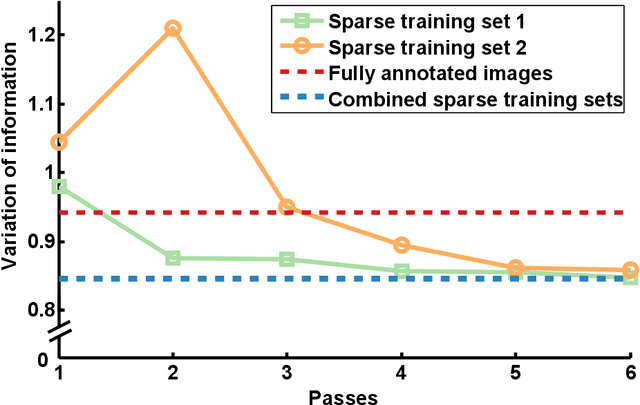
Automated sample preparation and electron microscopy enables acquisition of very large image data sets. These technical advances are of special importance to the field of neuroanatomy, as 3D reconstructions of neuronal processes at the nm scale can provide new insight into the fine grained structure of the brain. Segmentation of large-scale electron microscopy data is the main bottleneck in the analysis of these data sets. In this paper we present a pipeline that provides state-of-the art reconstruction performance while scaling to data sets in the GB-TB range. First, we train a random forest classifier on interactive sparse user annotations. The classifier output is combined with an anisotropic smoothing prior in a Conditional Random Field framework to generate multiple segmentation hypotheses per image. These segmentations are then combined into geometrically consistent 3D objects by segmentation fusion. We provide qualitative and quantitative evaluation of the automatic segmentation and demonstrate large-scale 3D reconstructions of neuronal processes from a $\mathbf{27,000}$ $\mathbf{\mu m^3}$ volume of brain tissue over a cube of $\mathbf{30 \; \mu m}$ in each dimension corresponding to 1000 consecutive image sections. We also introduce Mojo, a proofreading tool including semi-automated correction of merge errors based on sparse user scribbles.