 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver++: Generative Video Compositing for Layer Interaction Effects
Dec 22, 2025In professional video compositing workflows, artists must manually create environmental interactions-such as shadows, reflections, dust, and splashes-between foreground subjects and background layers. Existing video generative models struggle to preserve the input video while adding such effects, and current video inpainting methods either require costly per-frame masks or yield implausible results. We introduce augmented compositing, a new task that synthesizes realistic, semi-transparent environmental effects conditioned on text prompts and input video layers, while preserving the original scene. To address this task, we present Over++, a video effect generation framework that makes no assumptions about camera pose, scene stationarity, or depth supervision. We construct a paired effect dataset tailored for this task and introduce an unpaired augmentation strategy that preserves text-driven editability. Our method also supports optional mask control and keyframe guidance without requiring dense annotations. Despite training on limited data, Over++ produces diverse and realistic environmental effects and outperforms existing baselines in both effect generation and scene preservation.
Inpaint3D: 3D Scene Content Generation using 2D Inpainting Diffusion
Dec 06, 2023



This paper presents a novel approach to inpainting 3D regions of a scene, given masked multi-view images, by distilling a 2D diffusion model into a learned 3D scene representation (e.g. a NeRF). Unlike 3D generative methods that explicitly condition the diffusion model on camera pose or multi-view information, our diffusion model is conditioned only on a single masked 2D image. Nevertheless, we show that this 2D diffusion model can still serve as a generative prior in a 3D multi-view reconstruction problem where we optimize a NeRF using a combination of score distillation sampling and NeRF reconstruction losses. Predicted depth is used as additional supervision to encourage accurate geometry. We compare our approach to 3D inpainting methods that focus on object removal. Because our method can generate content to fill any 3D masked region, we additionally demonstrate 3D object completion, 3D object replacement, and 3D scene completion.
Readout Guidance: Learning Control from Diffusion Features
Dec 04, 2023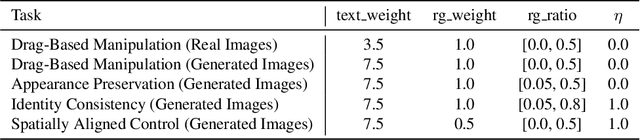

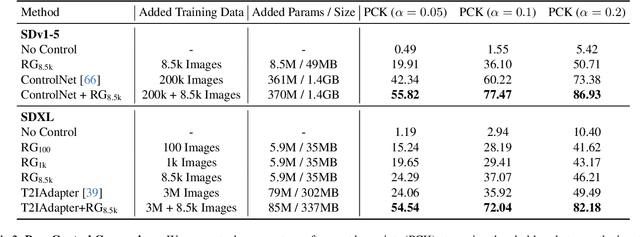
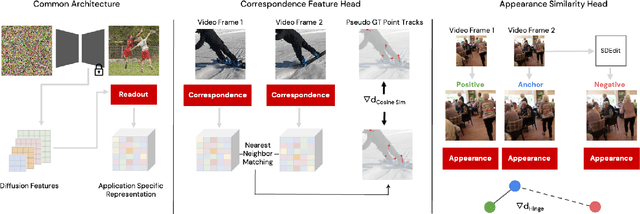
We present Readout Guidance, a method for controlling text-to-image diffusion models with learned signals. Readout Guidance uses readout heads, lightweight networks trained to extract signals from the features of a pre-trained, frozen diffusion model at every timestep. These readouts can encode single-image properties, such as pose, depth, and edges; or higher-order properties that relate multiple images, such as correspondence and appearance similarity. Furthermore, by comparing the readout estimates to a user-defined target, and back-propagating the gradient through the readout head, these estimates can be used to guide the sampling process. Compared to prior methods for conditional generation, Readout Guidance requires significantly fewer added parameters and training samples, and offers a convenient and simple recipe for reproducing different forms of conditional control under a single framework, with a single architecture and sampling procedure. We showcase these benefits in the applications of drag-based manipulation, identity-consistent generation, and spatially aligned control. Project page: https://readout-guidance.github.io.
HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields
Jun 24, 2021
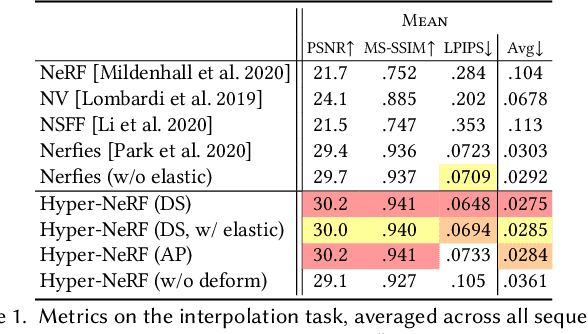
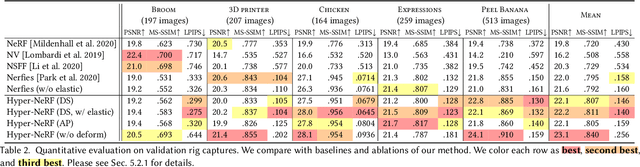
Neural Radiance Fields (NeRF) are able to reconstruct scenes with unprecedented fidelity, and various recent works have extended NeRF to handle dynamic scenes. A common approach to reconstruct such non-rigid scenes is through the use of a learned deformation field mapping from coordinates in each input image into a canonical template coordinate space. However, these deformation-based approaches struggle to model changes in topology, as topological changes require a discontinuity in the deformation field, but these deformation fields are necessarily continuous. We address this limitation by lifting NeRFs into a higher dimensional space, and by representing the 5D radiance field corresponding to each individual input image as a slice through this "hyper-space". Our method is inspired by level set methods, which model the evolution of surfaces as slices through a higher dimensional surface. We evaluate our method on two tasks: (i) interpolating smoothly between "moments", i.e., configurations of the scene, seen in the input images while maintaining visual plausibility, and (ii) novel-view synthesis at fixed moments. We show that our method, which we dub HyperNeRF, outperforms existing methods on both tasks by significant margins. Compared to Nerfies, HyperNeRF reduces average error rates by 8.6% for interpolation and 8.8% for novel-view synthesis, as measured by LPIPS.
Neural RGB-D Surface Reconstruction
Apr 09, 2021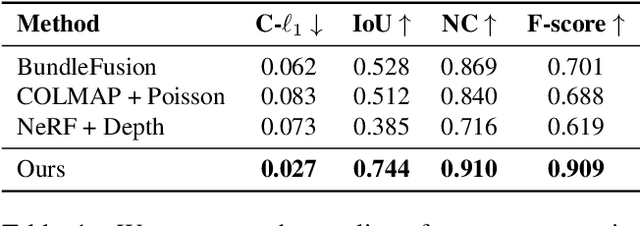
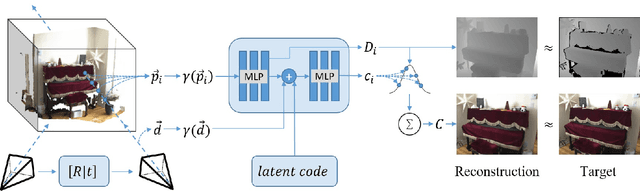
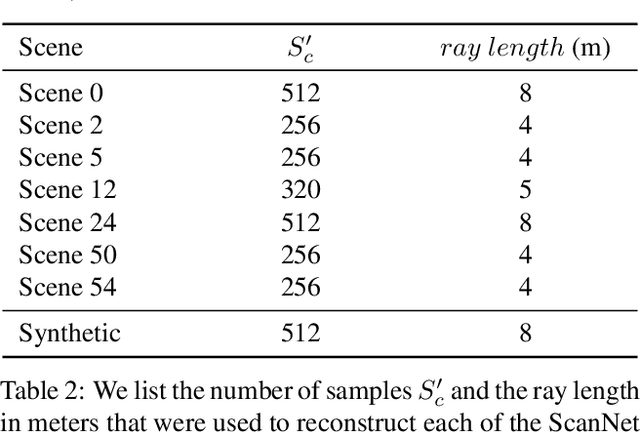
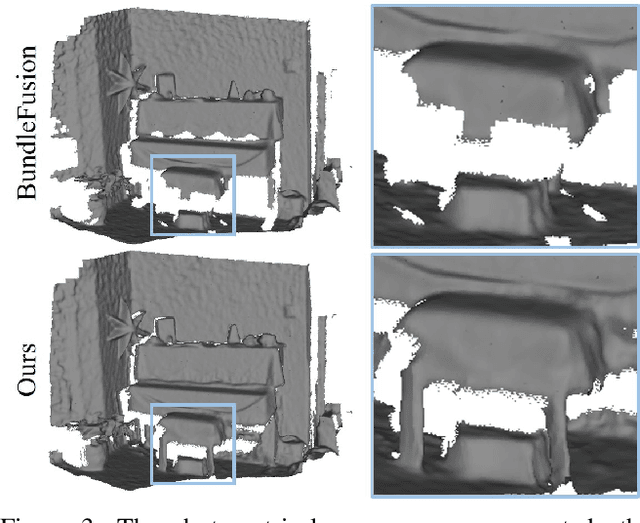
In this work, we explore how to leverage the success of implicit novel view synthesis methods for surface reconstruction. Methods which learn a neural radiance field have shown amazing image synthesis results, but the underlying geometry representation is only a coarse approximation of the real geometry. We demonstrate how depth measurements can be incorporated into the radiance field formulation to produce more detailed and complete reconstruction results than using methods based on either color or depth data alone. In contrast to a density field as the underlying geometry representation, we propose to learn a deep neural network which stores a truncated signed distance field. Using this representation, we show that one can still leverage differentiable volume rendering to estimate color values of the observed images during training to compute a reconstruction loss. This is beneficial for learning the signed distance field in regions with missing depth measurements. Furthermore, we correct misalignment errors of the camera, improving the overall reconstruction quality. In several experiments, we showcase our method and compare to existing works on classical RGB-D fusion and learned representations.
Deformable Neural Radiance Fields
Nov 26, 2020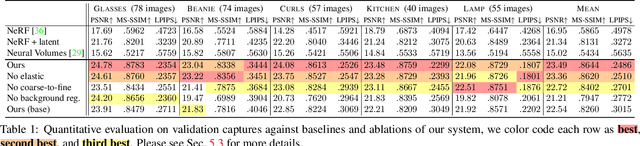

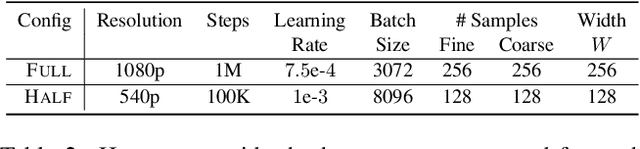

We present the first method capable of photorealistically reconstructing a non-rigidly deforming scene using photos/videos captured casually from mobile phones. Our approach -- D-NeRF -- augments neural radiance fields (NeRF) by optimizing an additional continuous volumetric deformation field that warps each observed point into a canonical 5D NeRF. We observe that these NeRF-like deformation fields are prone to local minima, and propose a coarse-to-fine optimization method for coordinate-based models that allows for more robust optimization. By adapting principles from geometry processing and physical simulation to NeRF-like models, we propose an elastic regularization of the deformation field that further improves robustness. We show that D-NeRF can turn casually captured selfie photos/videos into deformable NeRF models that allow for photorealistic renderings of the subject from arbitrary viewpoints, which we dub "nerfies." We evaluate our method by collecting data using a rig with two mobile phones that take time-synchronized photos, yielding train/validation images of the same pose at different viewpoints. We show that our method faithfully reconstructs non-rigidly deforming scenes and reproduces unseen views with high fidelity.
GeLaTO: Generative Latent Textured Objects
Aug 11, 2020
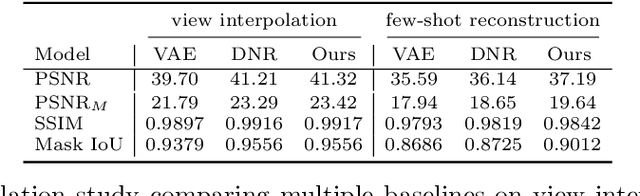

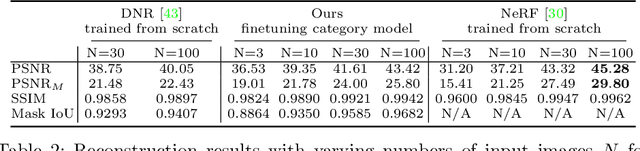
Accurate modeling of 3D objects exhibiting transparency, reflections and thin structures is an extremely challenging problem. Inspired by billboards and geometric proxies used in computer graphics, this paper proposes Generative Latent Textured Objects (GeLaTO), a compact representation that combines a set of coarse shape proxies defining low frequency geometry with learned neural textures, to encode both medium and fine scale geometry as well as view-dependent appearance. To generate the proxies' textures, we learn a joint latent space allowing category-level appearance and geometry interpolation. The proxies are independently rasterized with their corresponding neural texture and composited using a U-Net, which generates an output photorealistic image including an alpha map. We demonstrate the effectiveness of our approach by reconstructing complex objects from a sparse set of views. We show results on a dataset of real images of eyeglasses frames, which are particularly challenging to reconstruct using classical methods. We also demonstrate that these coarse proxies can be handcrafted when the underlying object geometry is easy to model, like eyeglasses, or generated using a neural network for more complex categories, such as cars.
* ECCV 2020 Spotlight. Project website: https://gelato-paper.github.io
State of the Art on Neural Rendering
Apr 08, 2020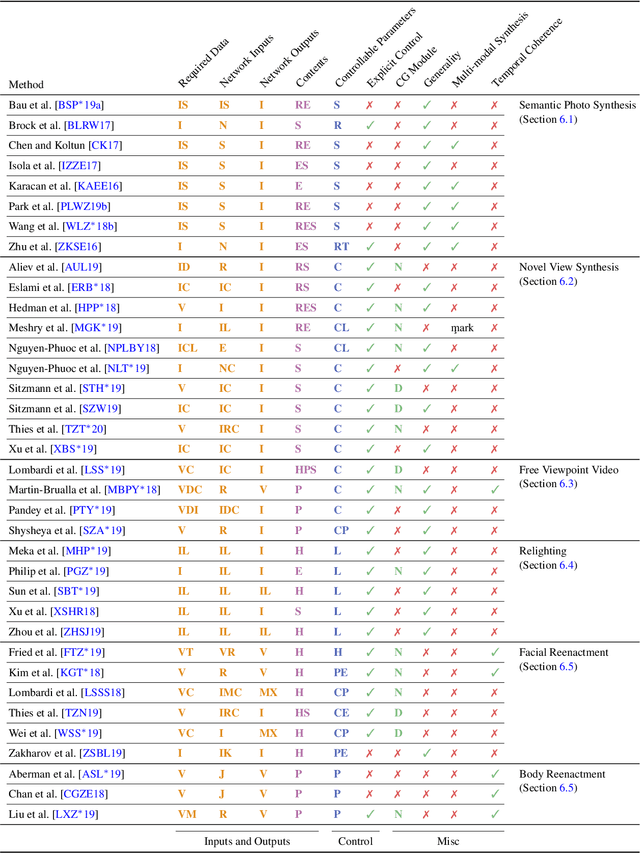



Efficient rendering of photo-realistic virtual worlds is a long standing effort of computer graphics. Modern graphics techniques have succeeded in synthesizing photo-realistic images from hand-crafted scene representations. However, the automatic generation of shape, materials, lighting, and other aspects of scenes remains a challenging problem that, if solved, would make photo-realistic computer graphics more widely accessible. Concurrently, progress in computer vision and machine learning have given rise to a new approach to image synthesis and editing, namely deep generative models. Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training. With a plethora of applications in computer graphics and vision, neural rendering is poised to become a new area in the graphics community, yet no survey of this emerging field exists. This state-of-the-art report summarizes the recent trends and applications of neural rendering. We focus on approaches that combine classic computer graphics techniques with deep generative models to obtain controllable and photo-realistic outputs. Starting with an overview of the underlying computer graphics and machine learning concepts, we discuss critical aspects of neural rendering approaches. This state-of-the-art report is focused on the many important use cases for the described algorithms such as novel view synthesis, semantic photo manipulation, facial and body reenactment, relighting, free-viewpoint video, and the creation of photo-realistic avatars for virtual and augmented reality telepresence. Finally, we conclude with a discussion of the social implications of such technology and investigate open research problems.
Text-based Editing of Talking-head Video
Jun 04, 2019
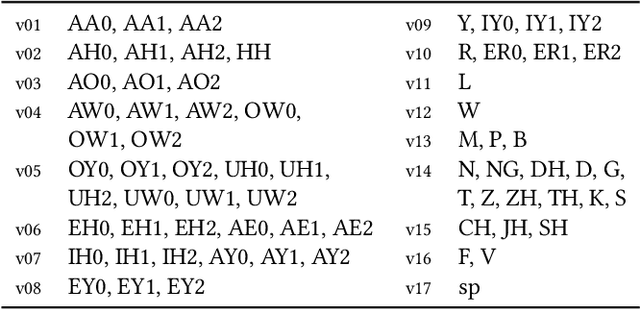
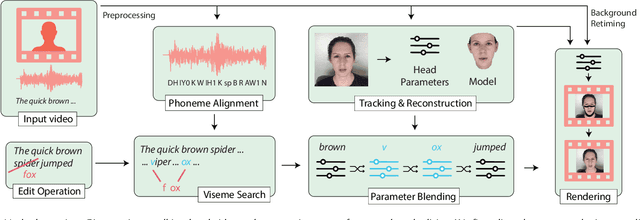
Editing talking-head video to change the speech content or to remove filler words is challenging. We propose a novel method to edit talking-head video based on its transcript to produce a realistic output video in which the dialogue of the speaker has been modified, while maintaining a seamless audio-visual flow (i.e. no jump cuts). Our method automatically annotates an input talking-head video with phonemes, visemes, 3D face pose and geometry, reflectance, expression and scene illumination per frame. To edit a video, the user has to only edit the transcript, and an optimization strategy then chooses segments of the input corpus as base material. The annotated parameters corresponding to the selected segments are seamlessly stitched together and used to produce an intermediate video representation in which the lower half of the face is rendered with a parametric face model. Finally, a recurrent video generation network transforms this representation to a photorealistic video that matches the edited transcript. We demonstrate a large variety of edits, such as the addition, removal, and alteration of words, as well as convincing language translation and full sentence synthesis.
Neural Rerendering in the Wild
Apr 08, 2019
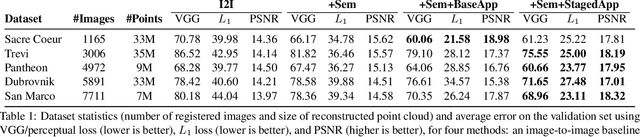

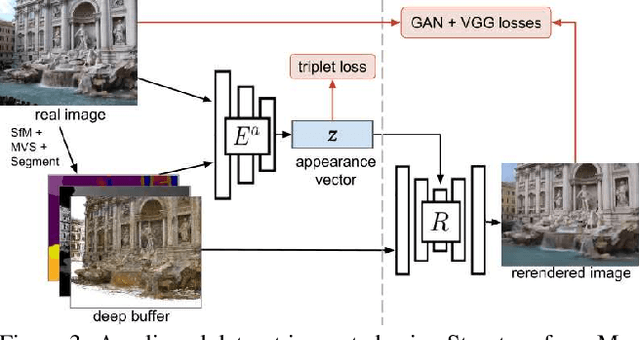
We explore total scene capture -- recording, modeling, and rerendering a scene under varying appearance such as season and time of day. Starting from internet photos of a tourist landmark, we apply traditional 3D reconstruction to register the photos and approximate the scene as a point cloud. For each photo, we render the scene points into a deep framebuffer, and train a neural network to learn the mapping of these initial renderings to the actual photos. This rerendering network also takes as input a latent appearance vector and a semantic mask indicating the location of transient objects like pedestrians. The model is evaluated on several datasets of publicly available images spanning a broad range of illumination conditions. We create short videos demonstrating realistic manipulation of the image viewpoint, appearance, and semantic labeling. We also compare results with prior work on scene reconstruction from internet photos.