 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeLaTO: Generative Latent Textured Objects
Paper and Code

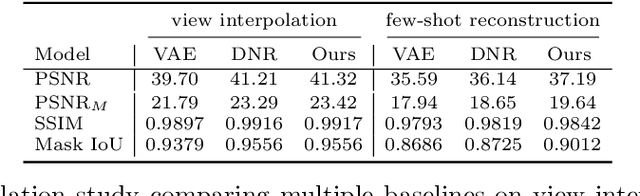

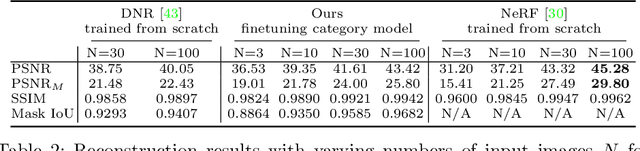
Accurate modeling of 3D objects exhibiting transparency, reflections and thin structures is an extremely challenging problem. Inspired by billboards and geometric proxies used in computer graphics, this paper proposes Generative Latent Textured Objects (GeLaTO), a compact representation that combines a set of coarse shape proxies defining low frequency geometry with learned neural textures, to encode both medium and fine scale geometry as well as view-dependent appearance. To generate the proxies' textures, we learn a joint latent space allowing category-level appearance and geometry interpolation. The proxies are independently rasterized with their corresponding neural texture and composited using a U-Net, which generates an output photorealistic image including an alpha map. We demonstrate the effectiveness of our approach by reconstructing complex objects from a sparse set of views. We show results on a dataset of real images of eyeglasses frames, which are particularly challenging to reconstruct using classical methods. We also demonstrate that these coarse proxies can be handcrafted when the underlying object geometry is easy to model, like eyeglasses, or generated using a neural network for more complex categories, such as cars.