 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-Range Gaussians: Non-Grid-Aligned Generative 3D Gaussian Reconstruction
Apr 06, 2026We present Free-Range Gaussians, a multi-view reconstruction method that predicts non-pixel, non-voxel-aligned 3D Gaussians from as few as four images. This is done through flow matching over Gaussian parameters. Our generative formulation of reconstruction allows the model to be supervised with non-grid-aligned 3D data, and enables it to synthesize plausible content in unobserved regions. Thus, it improves on prior methods that produce highly redundant grid-aligned Gaussians, and suffer from holes or blurry conditional means in unobserved regions. To handle the number of Gaussians needed for high-quality results, we introduce a hierarchical patching scheme to group spatially related Gaussians into joint transformer tokens, halving the sequence length while preserving structure. We further propose a timestep-weighted rendering loss during training, and photometric gradient guidance and classifier-free guidance at inference to improve fidelity. Experiments on Objaverse and Google Scanned Objects show consistent improvements over pixel and voxel-aligned methods while using significantly fewer Gaussians, with large gains when input views leave parts of the object unobserved.
Fus3D: Decoding Consolidated 3D Geometry from Feed-forward Geometry Transformer Latents
Mar 26, 2026We propose a feed-forward method for dense Signed Distance Field (SDF) regression from unstructured image collections in less than three seconds, without camera calibration or post-hoc fusion. Our key insight is that the intermediate feature space of pretrained multi-view feed-forward geometry transformers already encodes a powerful joint world representation; yet, existing pipelines discard it, routing features through per-view prediction heads before assembling 3D geometry post-hoc, which discards valuable completeness information and accumulates inaccuracies. We instead perform 3D extraction directly from geometry transformer features via learned volumetric extraction: voxelized canonical embeddings that progressively absorb multi-view geometry information through interleaved cross- and self-attention into a structured volumetric latent grid. A simple convolutional decoder then maps this grid to a dense SDF. We additionally propose a scalable, validity-aware supervision scheme directly using SDFs derived from depth maps or 3D assets, tackling practical issues like non-watertight meshes. Our approach yields complete and well-defined distance values across sparse- and dense-view settings and demonstrates geometrically plausible completions. Code and further material can be found at https://lorafib.github.io/fus3d.
4-LEGS: 4D Language Embedded Gaussian Splatting
Oct 15, 2024



The emergence of neural representations has revolutionized our means for digitally viewing a wide range of 3D scenes, enabling the synthesis of photorealistic images rendered from novel views. Recently, several techniques have been proposed for connecting these low-level representations with the high-level semantics understanding embodied within the scene. These methods elevate the rich semantic understanding from 2D imagery to 3D representations, distilling high-dimensional spatial features onto 3D space. In our work, we are interested in connecting language with a dynamic modeling of the world. We show how to lift spatio-temporal features to a 4D representation based on 3D Gaussian Splatting. This enables an interactive interface where the user can spatiotemporally localize events in the video from text prompts. We demonstrate our system on public 3D video datasets of people and animals performing various actions.
EVER: Exact Volumetric Ellipsoid Rendering for Real-time View Synthesis
Oct 02, 2024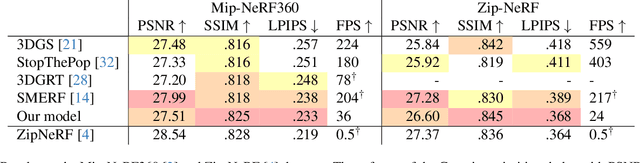
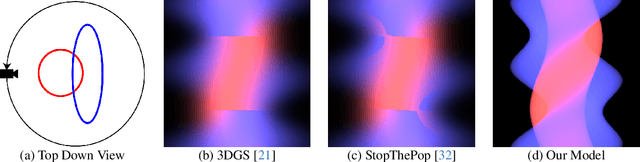
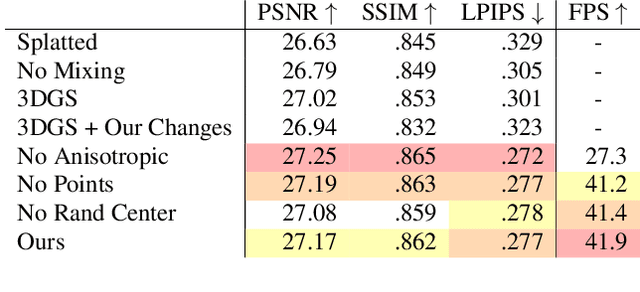
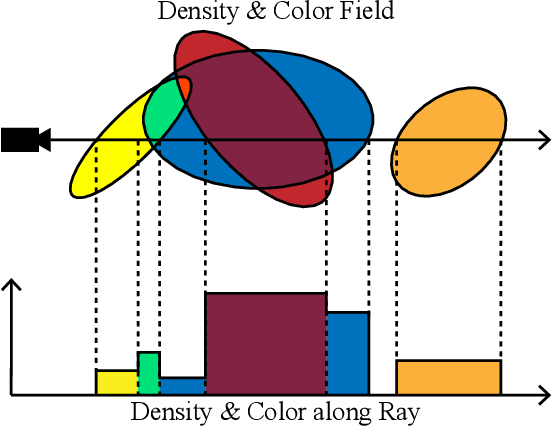
We present Exact Volumetric Ellipsoid Rendering (EVER), a method for real-time differentiable emission-only volume rendering. Unlike recent rasterization based approach by 3D Gaussian Splatting (3DGS), our primitive based representation allows for exact volume rendering, rather than alpha compositing 3D Gaussian billboards. As such, unlike 3DGS our formulation does not suffer from popping artifacts and view dependent density, but still achieves frame rates of $\sim\!30$ FPS at 720p on an NVIDIA RTX4090. Since our approach is built upon ray tracing it enables effects such as defocus blur and camera distortion (e.g. such as from fisheye cameras), which are difficult to achieve by rasterization. We show that our method is more accurate with fewer blending issues than 3DGS and follow-up work on view-consistent rendering, especially on the challenging large-scale scenes from the Zip-NeRF dataset where it achieves sharpest results among real-time techniques.
Flash Cache: Reducing Bias in Radiance Cache Based Inverse Rendering
Sep 09, 2024State-of-the-art techniques for 3D reconstruction are largely based on volumetric scene representations, which require sampling multiple points to compute the color arriving along a ray. Using these representations for more general inverse rendering -- reconstructing geometry, materials, and lighting from observed images -- is challenging because recursively path-tracing such volumetric representations is expensive. Recent works alleviate this issue through the use of radiance caches: data structures that store the steady-state, infinite-bounce radiance arriving at any point from any direction. However, these solutions rely on approximations that introduce bias into the renderings and, more importantly, into the gradients used for optimization. We present a method that avoids these approximations while remaining computationally efficient. In particular, we leverage two techniques to reduce variance for unbiased estimators of the rendering equation: (1) an occlusion-aware importance sampler for incoming illumination and (2) a fast cache architecture that can be used as a control variate for the radiance from a high-quality, but more expensive, volumetric cache. We show that by removing these biases our approach improves the generality of radiance cache based inverse rendering, as well as increasing quality in the presence of challenging light transport effects such as specular reflections.
InterNeRF: Scaling Radiance Fields via Parameter Interpolation
Jun 17, 2024Neural Radiance Fields (NeRFs) have unmatched fidelity on large, real-world scenes. A common approach for scaling NeRFs is to partition the scene into regions, each of which is assigned its own parameters. When implemented naively, such an approach is limited by poor test-time scaling and inconsistent appearance and geometry. We instead propose InterNeRF, a novel architecture for rendering a target view using a subset of the model's parameters. Our approach enables out-of-core training and rendering, increasing total model capacity with only a modest increase to training time. We demonstrate significant improvements in multi-room scenes while remaining competitive on standard benchmarks.
NeRF-Casting: Improved View-Dependent Appearance with Consistent Reflections
May 23, 2024

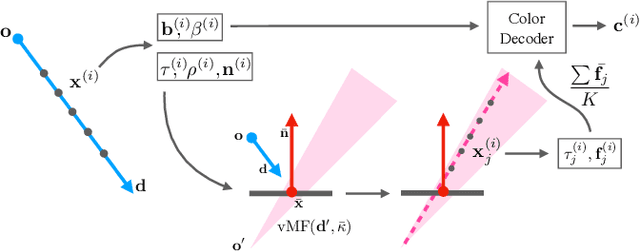

Neural Radiance Fields (NeRFs) typically struggle to reconstruct and render highly specular objects, whose appearance varies quickly with changes in viewpoint. Recent works have improved NeRF's ability to render detailed specular appearance of distant environment illumination, but are unable to synthesize consistent reflections of closer content. Moreover, these techniques rely on large computationally-expensive neural networks to model outgoing radiance, which severely limits optimization and rendering speed. We address these issues with an approach based on ray tracing: instead of querying an expensive neural network for the outgoing view-dependent radiance at points along each camera ray, our model casts reflection rays from these points and traces them through the NeRF representation to render feature vectors which are decoded into color using a small inexpensive network. We demonstrate that our model outperforms prior methods for view synthesis of scenes containing shiny objects, and that it is the only existing NeRF method that can synthesize photorealistic specular appearance and reflections in real-world scenes, while requiring comparable optimization time to current state-of-the-art view synthesis models.
Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis
Feb 19, 2024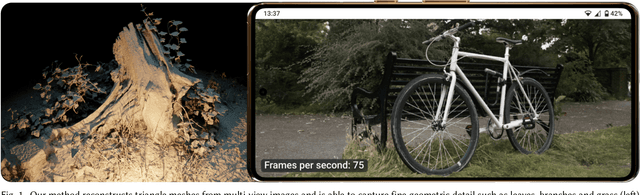



While surface-based view synthesis algorithms are appealing due to their low computational requirements, they often struggle to reproduce thin structures. In contrast, more expensive methods that model the scene's geometry as a volumetric density field (e.g. NeRF) excel at reconstructing fine geometric detail. However, density fields often represent geometry in a "fuzzy" manner, which hinders exact localization of the surface. In this work, we modify density fields to encourage them to converge towards surfaces, without compromising their ability to reconstruct thin structures. First, we employ a discrete opacity grid representation instead of a continuous density field, which allows opacity values to discontinuously transition from zero to one at the surface. Second, we anti-alias by casting multiple rays per pixel, which allows occlusion boundaries and subpixel structures to be modelled without using semi-transparent voxels. Third, we minimize the binary entropy of the opacity values, which facilitates the extraction of surface geometry by encouraging opacity values to binarize towards the end of training. Lastly, we develop a fusion-based meshing strategy followed by mesh simplification and appearance model fitting. The compact meshes produced by our model can be rendered in real-time on mobile devices and achieve significantly higher view synthesis quality compared to existing mesh-based approaches.
SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
Dec 12, 2023



Recent techniques for real-time view synthesis have rapidly advanced in fidelity and speed, and modern methods are capable of rendering near-photorealistic scenes at interactive frame rates. At the same time, a tension has arisen between explicit scene representations amenable to rasterization and neural fields built on ray marching, with state-of-the-art instances of the latter surpassing the former in quality while being prohibitively expensive for real-time applications. In this work, we introduce SMERF, a view synthesis approach that achieves state-of-the-art accuracy among real-time methods on large scenes with footprints up to 300 m$^2$ at a volumetric resolution of 3.5 mm$^3$. Our method is built upon two primary contributions: a hierarchical model partitioning scheme, which increases model capacity while constraining compute and memory consumption, and a distillation training strategy that simultaneously yields high fidelity and internal consistency. Our approach enables full six degrees of freedom (6DOF) navigation within a web browser and renders in real-time on commodity smartphones and laptops. Extensive experiments show that our method exceeds the current state-of-the-art in real-time novel view synthesis by 0.78 dB on standard benchmarks and 1.78 dB on large scenes, renders frames three orders of magnitude faster than state-of-the-art radiance field models, and achieves real-time performance across a wide variety of commodity devices, including smartphones. We encourage the reader to explore these models in person at our project website: https://smerf-3d.github.io.
Inpaint3D: 3D Scene Content Generation using 2D Inpainting Diffusion
Dec 06, 2023



This paper presents a novel approach to inpainting 3D regions of a scene, given masked multi-view images, by distilling a 2D diffusion model into a learned 3D scene representation (e.g. a NeRF). Unlike 3D generative methods that explicitly condition the diffusion model on camera pose or multi-view information, our diffusion model is conditioned only on a single masked 2D image. Nevertheless, we show that this 2D diffusion model can still serve as a generative prior in a 3D multi-view reconstruction problem where we optimize a NeRF using a combination of score distillation sampling and NeRF reconstruction losses. Predicted depth is used as additional supervision to encourage accurate geometry. We compare our approach to 3D inpainting methods that focus on object removal. Because our method can generate content to fill any 3D masked region, we additionally demonstrate 3D object completion, 3D object replacement, and 3D scene completion.