 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchon: A Unified Multimodal Model for Holistic Digital Human Generation
May 28, 2026Digital humans are fundamental to immersive interaction, yet creating a unified model for holistic modalities, including text, audio, motion, and visual content, remains an open challenge. In this paper, we present Archon, a fully pretrained, human-centric unified multimodal model for holistic avatar generation. Archon unifies seven modalities with modality-specific tokenizers, and a native autoregressive unified multimodal model pretrained on synchronized modalities and 72 diverse tasks to model holistic joint distributions. To address the token explosion challenge in high-fidelity talking videos, we introduce a memory-efficient semantic video reparameterization, achieving 4x token reduction while preserving fine-grained dynamics, coupled with a semantic-driven video diffusion decoder. We further propose a "Thinking in Modality" that decomposes ambiguous cross-modal tasks into stepwise thinking in an alternative chain of modality, progressively enhancing fidelity and controllability. Extensive experiments demonstrate that Archon achieves superior or comparable performance across diverse digital human generation tasks, validating the effectiveness of our unified framework. Project page: https://zju3dv.github.io/archon/.
S^2VG: 3D Stereoscopic and Spatial Video Generation via Denoising Frame Matrix
Aug 11, 2025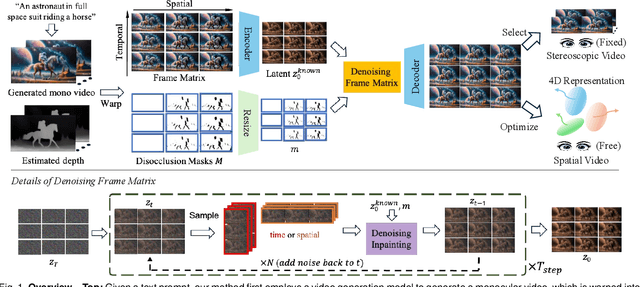

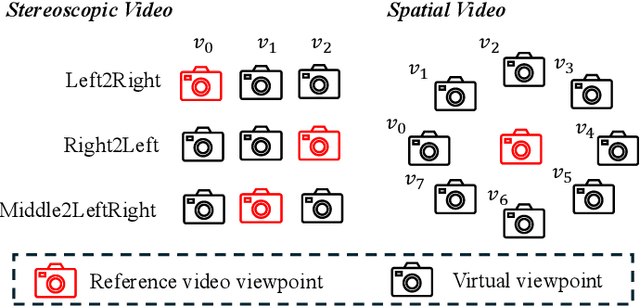

While video generation models excel at producing high-quality monocular videos, generating 3D stereoscopic and spatial videos for immersive applications remains an underexplored challenge. We present a pose-free and training-free method that leverages an off-the-shelf monocular video generation model to produce immersive 3D videos. Our approach first warps the generated monocular video into pre-defined camera viewpoints using estimated depth information, then applies a novel \textit{frame matrix} inpainting framework. This framework utilizes the original video generation model to synthesize missing content across different viewpoints and timestamps, ensuring spatial and temporal consistency without requiring additional model fine-tuning. Moreover, we develop a \dualupdate~scheme that further improves the quality of video inpainting by alleviating the negative effects propagated from disoccluded areas in the latent space. The resulting multi-view videos are then adapted into stereoscopic pairs or optimized into 4D Gaussians for spatial video synthesis. We validate the efficacy of our proposed method by conducting experiments on videos from various generative models, such as Sora, Lumiere, WALT, and Zeroscope. The experiments demonstrate that our method has a significant improvement over previous methods. Project page at: https://daipengwa.github.io/S-2VG_ProjectPage/
EVER: Exact Volumetric Ellipsoid Rendering for Real-time View Synthesis
Oct 02, 2024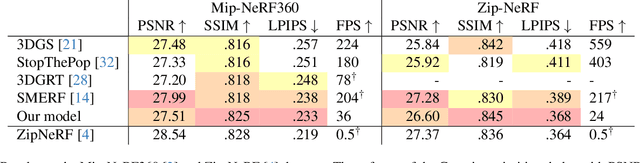
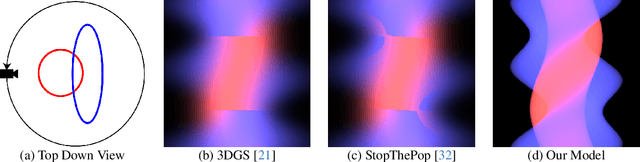
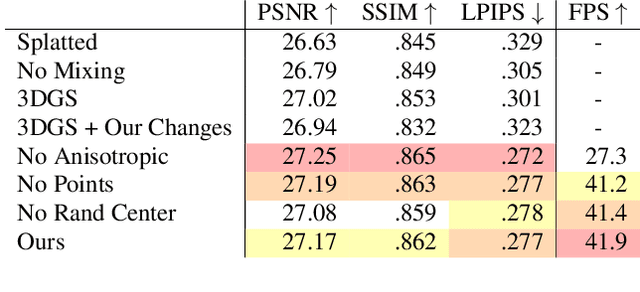
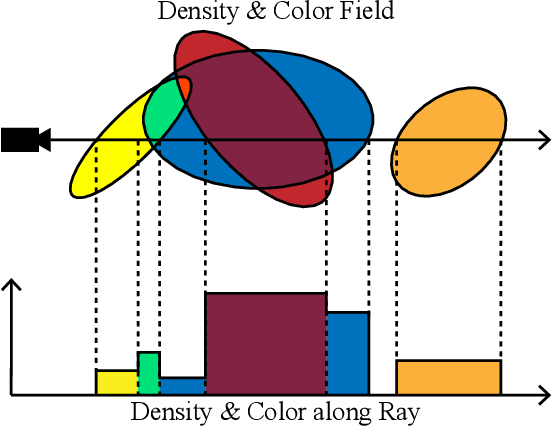
We present Exact Volumetric Ellipsoid Rendering (EVER), a method for real-time differentiable emission-only volume rendering. Unlike recent rasterization based approach by 3D Gaussian Splatting (3DGS), our primitive based representation allows for exact volume rendering, rather than alpha compositing 3D Gaussian billboards. As such, unlike 3DGS our formulation does not suffer from popping artifacts and view dependent density, but still achieves frame rates of $\sim\!30$ FPS at 720p on an NVIDIA RTX4090. Since our approach is built upon ray tracing it enables effects such as defocus blur and camera distortion (e.g. such as from fisheye cameras), which are difficult to achieve by rasterization. We show that our method is more accurate with fewer blending issues than 3DGS and follow-up work on view-consistent rendering, especially on the challenging large-scale scenes from the Zip-NeRF dataset where it achieves sharpest results among real-time techniques.
SVG: 3D Stereoscopic Video Generation via Denoising Frame Matrix
Jun 29, 2024



Video generation models have demonstrated great capabilities of producing impressive monocular videos, however, the generation of 3D stereoscopic video remains under-explored. We propose a pose-free and training-free approach for generating 3D stereoscopic videos using an off-the-shelf monocular video generation model. Our method warps a generated monocular video into camera views on stereoscopic baseline using estimated video depth, and employs a novel frame matrix video inpainting framework. The framework leverages the video generation model to inpaint frames observed from different timestamps and views. This effective approach generates consistent and semantically coherent stereoscopic videos without scene optimization or model fine-tuning. Moreover, we develop a disocclusion boundary re-injection scheme that further improves the quality of video inpainting by alleviating the negative effects propagated from disoccluded areas in the latent space. We validate the efficacy of our proposed method by conducting experiments on videos from various generative models, including Sora [4 ], Lumiere [2], WALT [8 ], and Zeroscope [ 42]. The experiments demonstrate that our method has a significant improvement over previous methods. The code will be released at \url{https://daipengwa.github.io/SVG_ProjectPage}.
Controllable Light Diffusion for Portraits
May 08, 2023



We introduce light diffusion, a novel method to improve lighting in portraits, softening harsh shadows and specular highlights while preserving overall scene illumination. Inspired by professional photographers' diffusers and scrims, our method softens lighting given only a single portrait photo. Previous portrait relighting approaches focus on changing the entire lighting environment, removing shadows (ignoring strong specular highlights), or removing shading entirely. In contrast, we propose a learning based method that allows us to control the amount of light diffusion and apply it on in-the-wild portraits. Additionally, we design a method to synthetically generate plausible external shadows with sub-surface scattering effects while conforming to the shape of the subject's face. Finally, we show how our approach can increase the robustness of higher level vision applications, such as albedo estimation, geometry estimation and semantic segmentation.
STALP: Style Transfer with Auxiliary Limited Pairing
Oct 20, 2021We present an approach to example-based stylization of images that uses a single pair of a source image and its stylized counterpart. We demonstrate how to train an image translation network that can perform real-time semantically meaningful style transfer to a set of target images with similar content as the source image. A key added value of our approach is that it considers also consistency of target images during training. Although those have no stylized counterparts, we constrain the translation to keep the statistics of neural responses compatible with those extracted from the stylized source. In contrast to concurrent techniques that use a similar input, our approach better preserves important visual characteristics of the source style and can deliver temporally stable results without the need to explicitly handle temporal consistency. We demonstrate its practical utility on various applications including video stylization, style transfer to panoramas, faces, and 3D models.
Real Image Inversion via Segments
Oct 12, 2021



In this short report, we present a simple, yet effective approach to editing real images via generative adversarial networks (GAN). Unlike previous techniques, that treat all editing tasks as an operation that affects pixel values in the entire image in our approach we cut up the image into a set of smaller segments. For those segments corresponding latent codes of a generative network can be estimated with greater accuracy due to the lower number of constraints. When codes are altered by the user the content in the image is manipulated locally while the rest of it remains unaffected. Thanks to this property the final edited image better retains the original structures and thus helps to preserve natural look.
Interactive Video Stylization Using Few-Shot Patch-Based Training
Apr 29, 2020
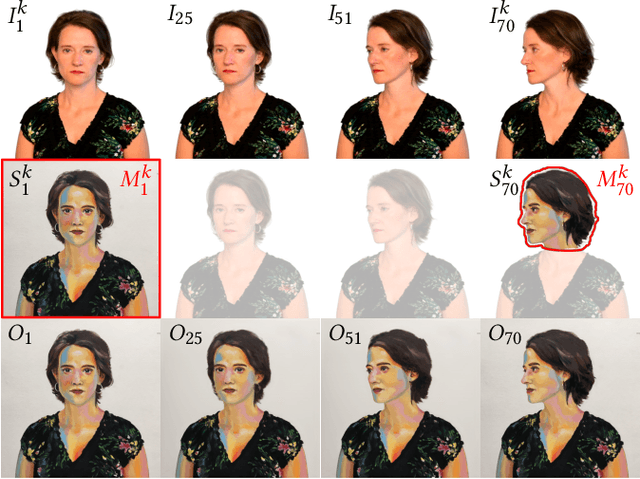

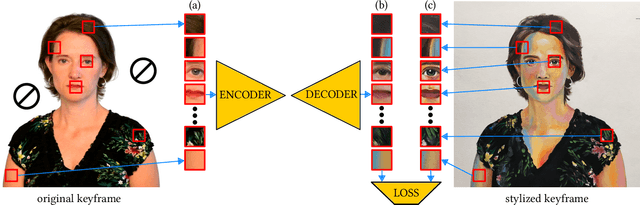
In this paper, we present a learning-based method to the keyframe-based video stylization that allows an artist to propagate the style from a few selected keyframes to the rest of the sequence. Its key advantage is that the resulting stylization is semantically meaningful, i.e., specific parts of moving objects are stylized according to the artist's intention. In contrast to previous style transfer techniques, our approach does not require any lengthy pre-training process nor a large training dataset. We demonstrate how to train an appearance translation network from scratch using only a few stylized exemplars while implicitly preserving temporal consistency. This leads to a video stylization framework that supports real-time inference, parallel processing, and random access to an arbitrary output frame. It can also merge the content from multiple keyframes without the need to perform an explicit blending operation. We demonstrate its practical utility in various interactive scenarios, where the user paints over a selected keyframe and sees her style transferred to an existing recorded sequence or a live video stream.