 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncPatch Diffusion: spatially-flexible image generation
Jun 05, 2026Standard diffusion models corrupt an entire sample with a single shared noise level, forcing all spatial regions to follow the same denoising trajectory. We introduce AsyncPatch Diffusion, a joint-diffusion framework that assigns distinct noise levels to different input dimensions, such as image pixels, or latent tokens. We show how this asynchronous corruption defines a valid generative process while supporting a richer family of spatially heterogeneous denoising trajectories, and prove the first valid ELBO for this process. We show that a single pretrained model can perform spatially adaptive generation, where different regions are denoised on different schedules. A key challenge is training: naive independent noise-level sampling overemphasizes highly heterogeneous configurations and underrepresents homogeneous noise levels, that are crucial during sampling. We address this with a controlled noise-level sampler that regulates both the average corruption level and its spatial variability. AsyncPatch achieves generation quality comparable to conventional diffusion on ImageNet 256 and LSUN, while being natively suited for inpainting without task-specific fine-tuning. We further introduce input guidance, which uses clean or partially corrupted regions to guide the generation of unknown regions, improving local consistency and texture matching. Finally, we demonstrate adaptive generation strategies including uncertainty-guided acceleration and autoregressive sampling.
Controllable Light Diffusion for Portraits
May 08, 2023



We introduce light diffusion, a novel method to improve lighting in portraits, softening harsh shadows and specular highlights while preserving overall scene illumination. Inspired by professional photographers' diffusers and scrims, our method softens lighting given only a single portrait photo. Previous portrait relighting approaches focus on changing the entire lighting environment, removing shadows (ignoring strong specular highlights), or removing shading entirely. In contrast, we propose a learning based method that allows us to control the amount of light diffusion and apply it on in-the-wild portraits. Additionally, we design a method to synthetically generate plausible external shadows with sub-surface scattering effects while conforming to the shape of the subject's face. Finally, we show how our approach can increase the robustness of higher level vision applications, such as albedo estimation, geometry estimation and semantic segmentation.
STALP: Style Transfer with Auxiliary Limited Pairing
Oct 20, 2021We present an approach to example-based stylization of images that uses a single pair of a source image and its stylized counterpart. We demonstrate how to train an image translation network that can perform real-time semantically meaningful style transfer to a set of target images with similar content as the source image. A key added value of our approach is that it considers also consistency of target images during training. Although those have no stylized counterparts, we constrain the translation to keep the statistics of neural responses compatible with those extracted from the stylized source. In contrast to concurrent techniques that use a similar input, our approach better preserves important visual characteristics of the source style and can deliver temporally stable results without the need to explicitly handle temporal consistency. We demonstrate its practical utility on various applications including video stylization, style transfer to panoramas, faces, and 3D models.
Real Image Inversion via Segments
Oct 12, 2021



In this short report, we present a simple, yet effective approach to editing real images via generative adversarial networks (GAN). Unlike previous techniques, that treat all editing tasks as an operation that affects pixel values in the entire image in our approach we cut up the image into a set of smaller segments. For those segments corresponding latent codes of a generative network can be estimated with greater accuracy due to the lower number of constraints. When codes are altered by the user the content in the image is manipulated locally while the rest of it remains unaffected. Thanks to this property the final edited image better retains the original structures and thus helps to preserve natural look.
Interactive Video Stylization Using Few-Shot Patch-Based Training
Apr 29, 2020
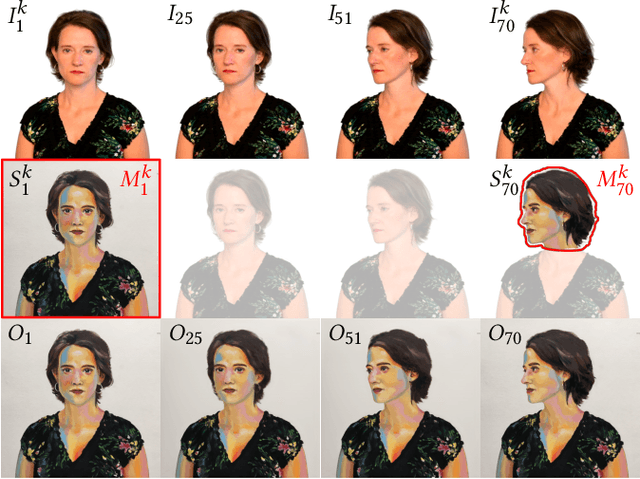

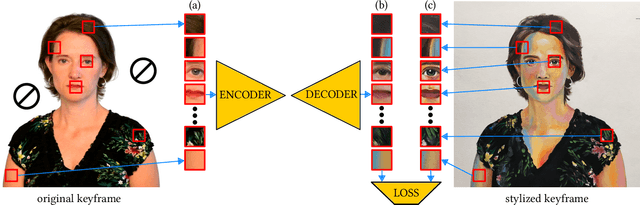
In this paper, we present a learning-based method to the keyframe-based video stylization that allows an artist to propagate the style from a few selected keyframes to the rest of the sequence. Its key advantage is that the resulting stylization is semantically meaningful, i.e., specific parts of moving objects are stylized according to the artist's intention. In contrast to previous style transfer techniques, our approach does not require any lengthy pre-training process nor a large training dataset. We demonstrate how to train an appearance translation network from scratch using only a few stylized exemplars while implicitly preserving temporal consistency. This leads to a video stylization framework that supports real-time inference, parallel processing, and random access to an arbitrary output frame. It can also merge the content from multiple keyframes without the need to perform an explicit blending operation. We demonstrate its practical utility in various interactive scenarios, where the user paints over a selected keyframe and sees her style transferred to an existing recorded sequence or a live video stream.