 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemLayer: Semantic-aware Generative Segmentation and Layer Construction for Abstract Icons
Mar 25, 2026Graphic icons are a cornerstone of modern design workflows, yet they are often distributed as flattened single-path or compound-path graphics, where the original semantic layering is lost. This absence of semantic decomposition hinders downstream tasks such as editing, restyling, and animation. We formalize this problem as semantic layer construction for flattened vector art and introduce SemLayer, a visual generation empowered pipeline that restores editable layered structures. Given an abstract icon, SemLayer first generates a chromatically differentiated representation in which distinct semantic components become visually separable. To recover the complete geometry of each part, including occluded regions, we then perform a semantic completion step that reconstructs coherent object-level shapes. Finally, the recovered parts are assembled into a layered vector representation with inferred occlusion relationships. Extensive qualitative comparisons and quantitative evaluations demonstrate the effectiveness of SemLayer, enabling editing workflows previously inapplicable to flattened vector graphics and establishing semantic layer reconstruction as a practical and valuable task. Project page: https://xxuhaiyang.github.io/SemLayer/
ULW-SleepNet: An Ultra-Lightweight Network for Multimodal Sleep Stage Scoring
Feb 27, 2026Automatic sleep stage scoring is crucial for the diagnosis and treatment of sleep disorders. Although deep learning models have advanced the field, many existing models are computationally demanding and designed for single-channel electroencephalography (EEG), limiting their practicality for multimodal polysomnography (PSG) data. To overcome this, we propose ULW-SleepNet, an ultra-lightweight multimodal sleep stage scoring framework that efficiently integrates information from multiple physiological signals. ULW-SleepNet incorporates a novel Dual-Stream Separable Convolution (DSSC) Block, depthwise separable convolutions, channel-wise parameter sharing, and global average pooling to reduce computational overhead while maintaining competitive accuracy. Evaluated on the Sleep-EDF-20 and Sleep-EDF-78 datasets, ULW-SleepNet achieves accuracies of 86.9% and 81.4%, respectively, with only 13.3K parameters and 7.89M FLOPs. Compared to state-of-the-art methods, our model reduces parameters by up to 98.6% with only marginal performance loss, demonstrating its strong potential for real-time sleep monitoring on wearable and IoT devices. The source code for this study is publicly available at https://github.com/wzw999/ULW-SLEEPNET.
Rethinking the Text-Vision Reasoning Imbalance in MLLMs through the Lens of Training Recipes
Oct 26, 2025Multimodal large language models (MLLMs) have demonstrated strong capabilities on vision-and-language tasks. However, recent findings reveal an imbalance in their reasoning capabilities across visual and textual modalities. Specifically, current MLLMs often over-rely on textual cues while under-attending to visual content, resulting in suboptimal performance on tasks that require genuine visual reasoning. We refer to this phenomenon as the \textit{modality gap}, defined as the performance disparity between text-centric and vision-centric inputs. In this paper, we analyze the modality gap through the lens of training recipes. We first show that existing training recipes tend to amplify this gap. Then, we systematically explore strategies to bridge it from two complementary perspectives: data and loss design. Our findings provide insights into developing training recipes that mitigate the modality gap and promote more balanced multimodal reasoning. Our code is publicly available at https://github.com/UCSB-NLP-Chang/Bridging-Modality-Gap.
Interact-Custom: Customized Human Object Interaction Image Generation
Aug 28, 2025Compositional Customized Image Generation aims to customize multiple target concepts within generation content, which has gained attention for its wild application. Existing approaches mainly concentrate on the target entity's appearance preservation, while neglecting the fine-grained interaction control among target entities. To enable the model of such interaction control capability, we focus on human object interaction scenario and propose the task of Customized Human Object Interaction Image Generation(CHOI), which simultaneously requires identity preservation for target human object and the interaction semantic control between them. Two primary challenges exist for CHOI:(1)simultaneous identity preservation and interaction control demands require the model to decompose the human object into self-contained identity features and pose-oriented interaction features, while the current HOI image datasets fail to provide ideal samples for such feature-decomposed learning.(2)inappropriate spatial configuration between human and object may lead to the lack of desired interaction semantics. To tackle it, we first process a large-scale dataset, where each sample encompasses the same pair of human object involving different interactive poses. Then we design a two-stage model Interact-Custom, which firstly explicitly models the spatial configuration by generating a foreground mask depicting the interaction behavior, then under the guidance of this mask, we generate the target human object interacting while preserving their identities features. Furthermore, if the background image and the union location of where the target human object should appear are provided by users, Interact-Custom also provides the optional functionality to specify them, offering high content controllability. Extensive experiments on our tailored metrics for CHOI task demonstrate the effectiveness of our approach.
CCMusic: An Open and Diverse Database for Chinese Music Information Retrieval Research
Mar 24, 2025Data are crucial in various computer-related fields, including music information retrieval (MIR), an interdisciplinary area bridging computer science and music. This paper introduces CCMusic, an open and diverse database comprising multiple datasets specifically designed for tasks related to Chinese music, highlighting our focus on this culturally rich domain. The database integrates both published and unpublished datasets, with steps taken such as data cleaning, label refinement, and data structure unification to ensure data consistency and create ready-to-use versions. We conduct benchmark evaluations for all datasets using a unified evaluation framework developed specifically for this purpose. This publicly available framework supports both classification and detection tasks, ensuring standardized and reproducible results across all datasets. The database is hosted on HuggingFace and ModelScope, two open and multifunctional data and model hosting platforms, ensuring ease of accessibility and usability.
* 17 pages, 18 figures
Phase Error Sensitivity to Injection Signals in Multi-Phase Injection-Locked Ring Oscillators
Jan 03, 2025



Multi-phase injection-locked ring oscillators (MP-ILROs) are widely used for multi-phase clock generation, with their phase accuracy primarily determined by the inherent accuracy of the oscillator itself, due to the suppression of input signal errors. However, a quantitative analysis of the oscillator's sensitivity to input errors remains largely unexplored. This paper presents a phasor-based analysis of injection locking, revealing that the phase error sensitivity is influenced by factors such as injection strength and the free-running frequency of the oscillator. Simulation results align closely with theoretical calculations, validating the effectiveness of the proposed method.
Amplitude-to-Phase Conversion in Injection-Locked CMOS Ring Oscillators
Dec 28, 2024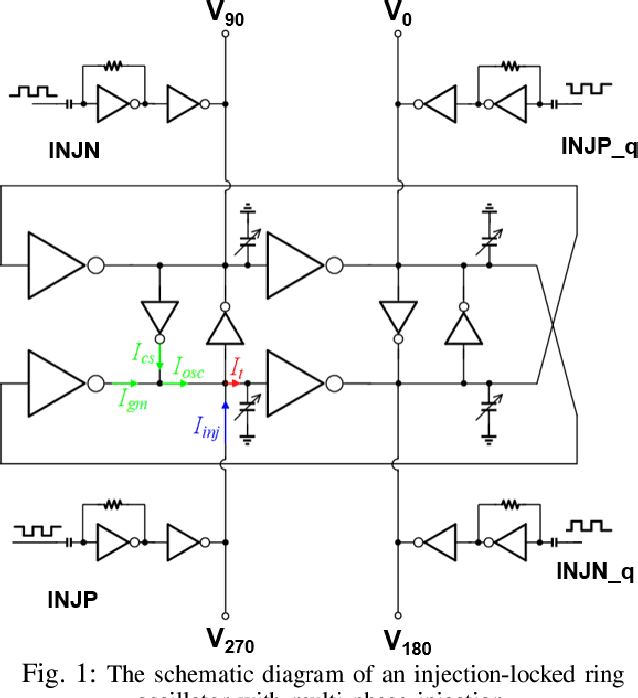
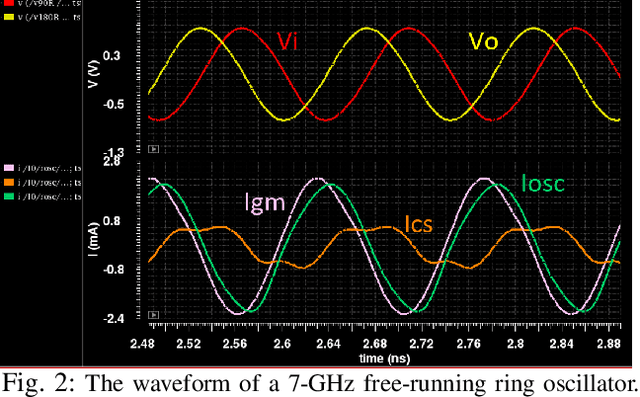
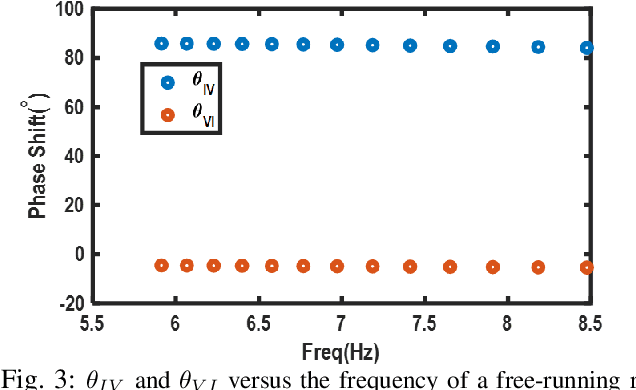
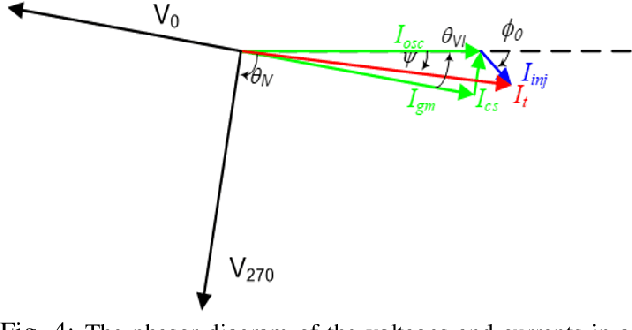
Injection-locked ring oscillators (ILROs) are extensively employed for multi-phase clock generation in wireline and optical links. However, existing injection-locking theorems primarily rely on linearized phase-domain or nonlinear time-domain models, which fail to account for amplitude-to-phase conversion effects inherent in ILROs. This paper introduces an enhanced analytical model based on an extension of Adler's equation, explicitly incorporating amplitude-to-phase conversion. Simulation results demonstrate strong alignment with the proposed analytical predictions, validating the model's accuracy in capturing the locking range and phasor relationships.
WAS: Dataset and Methods for Artistic Text Segmentation
Jul 31, 2024
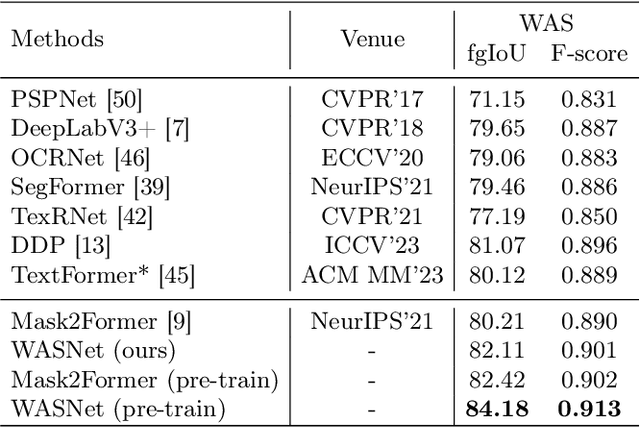
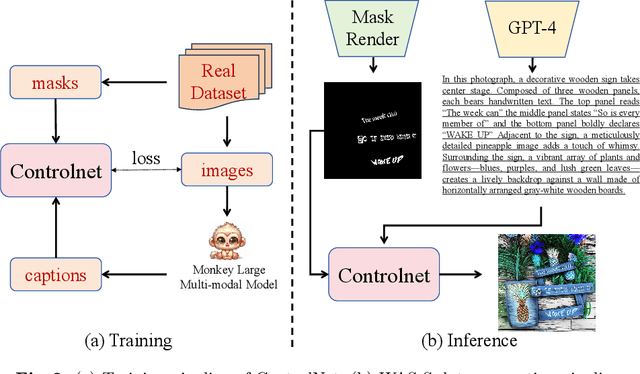
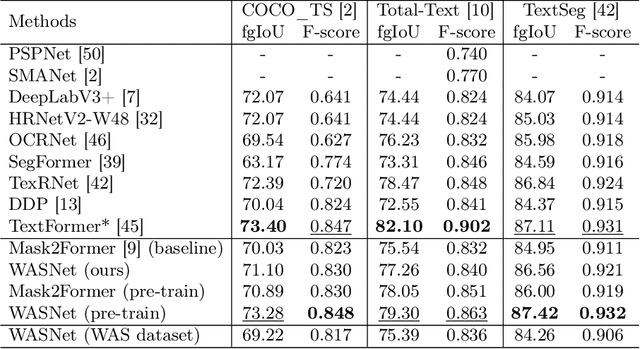
Accurate text segmentation results are crucial for text-related generative tasks, such as text image generation, text editing, text removal, and text style transfer. Recently, some scene text segmentation methods have made significant progress in segmenting regular text. However, these methods perform poorly in scenarios containing artistic text. Therefore, this paper focuses on the more challenging task of artistic text segmentation and constructs a real artistic text segmentation dataset. One challenge of the task is that the local stroke shapes of artistic text are changeable with diversity and complexity. We propose a decoder with the layer-wise momentum query to prevent the model from ignoring stroke regions of special shapes. Another challenge is the complexity of the global topological structure. We further design a skeleton-assisted head to guide the model to focus on the global structure. Additionally, to enhance the generalization performance of the text segmentation model, we propose a strategy for training data synthesis, based on the large multi-modal model and the diffusion model. Experimental results show that our proposed method and synthetic dataset can significantly enhance the performance of artistic text segmentation and achieve state-of-the-art results on other public datasets.
Scaling Up Video Summarization Pretraining with Large Language Models
Apr 04, 2024Long-form video content constitutes a significant portion of internet traffic, making automated video summarization an essential research problem. However, existing video summarization datasets are notably limited in their size, constraining the effectiveness of state-of-the-art methods for generalization. Our work aims to overcome this limitation by capitalizing on the abundance of long-form videos with dense speech-to-video alignment and the remarkable capabilities of recent large language models (LLMs) in summarizing long text. We introduce an automated and scalable pipeline for generating a large-scale video summarization dataset using LLMs as Oracle summarizers. By leveraging the generated dataset, we analyze the limitations of existing approaches and propose a new video summarization model that effectively addresses them. To facilitate further research in the field, our work also presents a new benchmark dataset that contains 1200 long videos each with high-quality summaries annotated by professionals. Extensive experiments clearly indicate that our proposed approach sets a new state-of-the-art in video summarization across several benchmarks.
Multi-Modal Video Topic Segmentation with Dual-Contrastive Domain Adaptation
Nov 30, 2023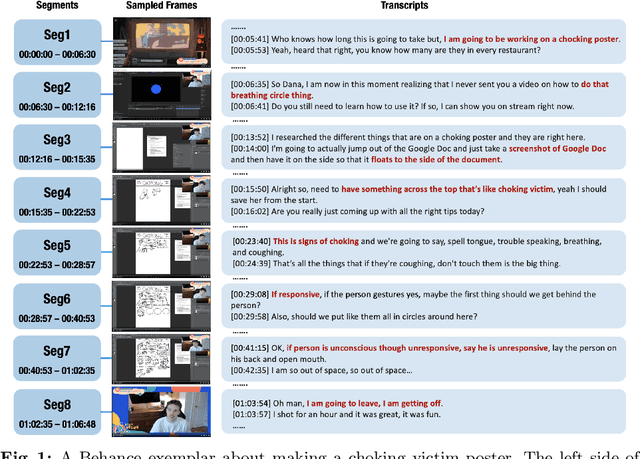
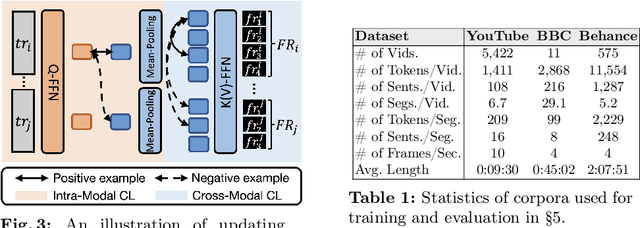
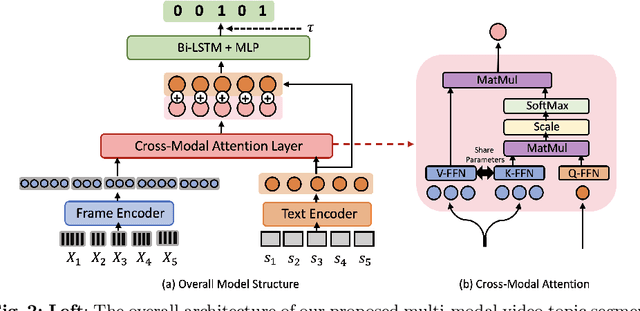
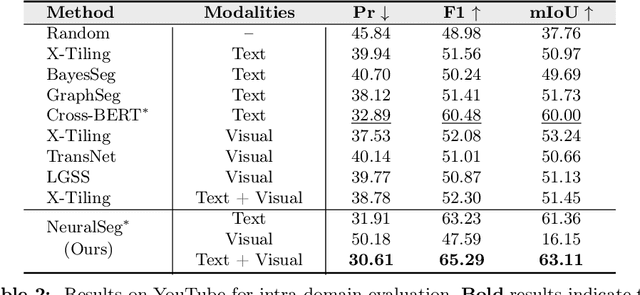
Video topic segmentation unveils the coarse-grained semantic structure underlying videos and is essential for other video understanding tasks. Given the recent surge in multi-modal, relying solely on a single modality is arguably insufficient. On the other hand, prior solutions for similar tasks like video scene/shot segmentation cater to short videos with clear visual shifts but falter for long videos with subtle changes, such as livestreams. In this paper, we introduce a multi-modal video topic segmenter that utilizes both video transcripts and frames, bolstered by a cross-modal attention mechanism. Furthermore, we propose a dual-contrastive learning framework adhering to the unsupervised domain adaptation paradigm, enhancing our model's adaptability to longer, more semantically complex videos. Experiments on short and long video corpora demonstrate that our proposed solution, significantly surpasses baseline methods in terms of both accuracy and transferability, in both intra- and cross-domain settings.