 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECKBench: Benchmarking Multi-Agent Frameworks for Academic Slide Generation and Editing
Feb 10, 2026Automatically generating and iteratively editing academic slide decks requires more than document summarization. It demands faithful content selection, coherent slide organization, layout-aware rendering, and robust multi-turn instruction following. However, existing benchmarks and evaluation protocols do not adequately measure these challenges. To address this gap, we introduce the Deck Edits and Compliance Kit Benchmark (DECKBench), an evaluation framework for multi-agent slide generation and editing. DECKBench is built on a curated dataset of paper to slide pairs augmented with realistic, simulated editing instructions. Our evaluation protocol systematically assesses slide-level and deck-level fidelity, coherence, layout quality, and multi-turn instruction following. We further implement a modular multi-agent baseline system that decomposes the slide generation and editing task into paper parsing and summarization, slide planning, HTML creation, and iterative editing. Experimental results demonstrate that the proposed benchmark highlights strengths, exposes failure modes, and provides actionable insights for improving multi-agent slide generation and editing systems. Overall, this work establishes a standardized foundation for reproducible and comparable evaluation of academic presentation generation and editing. Code and data are publicly available at https://github.com/morgan-heisler/DeckBench .
Enhancing Learned Knowledge in LoRA Adapters Through Efficient Contrastive Decoding on Ascend NPUs
May 20, 2025Huawei Cloud users leverage LoRA (Low-Rank Adaptation) as an efficient and scalable method to fine-tune and customize large language models (LLMs) for application-specific needs. However, tasks that require complex reasoning or deep contextual understanding are often hindered by biases or interference from the base model when using typical decoding methods like greedy or beam search. These biases can lead to generic or task-agnostic responses from the base model instead of leveraging the LoRA-specific adaptations. In this paper, we introduce Contrastive LoRA Decoding (CoLD), a novel decoding framework designed to maximize the use of task-specific knowledge in LoRA-adapted models, resulting in better downstream performance. CoLD uses contrastive decoding by scoring candidate tokens based on the divergence between the probability distributions of a LoRA-adapted expert model and the corresponding base model. This approach prioritizes tokens that better align with the LoRA's learned representations, enhancing performance for specialized tasks. While effective, a naive implementation of CoLD is computationally expensive because each decoding step requires evaluating multiple token candidates across both models. To address this, we developed an optimized kernel for Huawei's Ascend NPU. CoLD achieves up to a 5.54% increase in task accuracy while reducing end-to-end latency by 28% compared to greedy decoding. This work provides practical and efficient decoding strategies for fine-tuned LLMs in resource-constrained environments and has broad implications for applied data science in both cloud and on-premises settings.
Artificial Intelligence for Operations Research: Revolutionizing the Operations Research Process
Jan 06, 2024
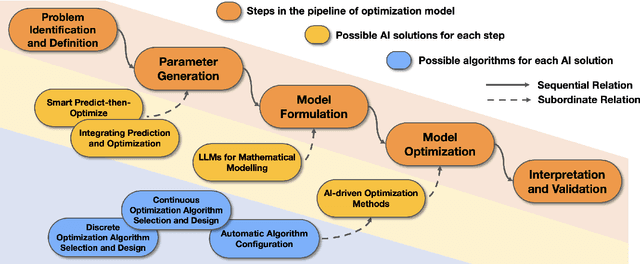
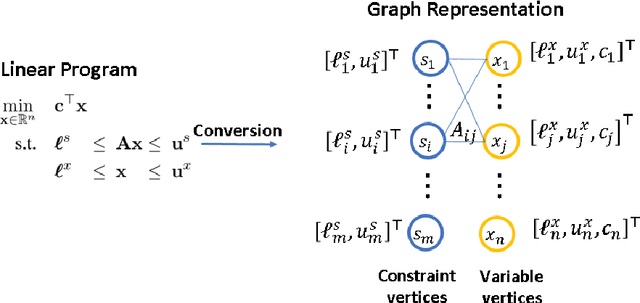
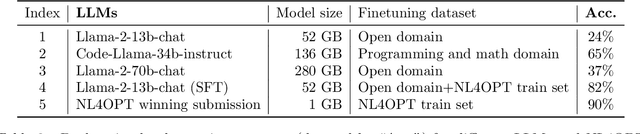
The rapid advancement of artificial intelligence (AI) techniques has opened up new opportunities to revolutionize various fields, including operations research (OR). This survey paper explores the integration of AI within the OR process (AI4OR) to enhance its effectiveness and efficiency across multiple stages, such as parameter generation, model formulation, and model optimization. By providing a comprehensive overview of the state-of-the-art and examining the potential of AI to transform OR, this paper aims to inspire further research and innovation in the development of AI-enhanced OR methods and tools. The synergy between AI and OR is poised to drive significant advancements and novel solutions in a multitude of domains, ultimately leading to more effective and efficient decision-making.
Multi-Modal Video Topic Segmentation with Dual-Contrastive Domain Adaptation
Nov 30, 2023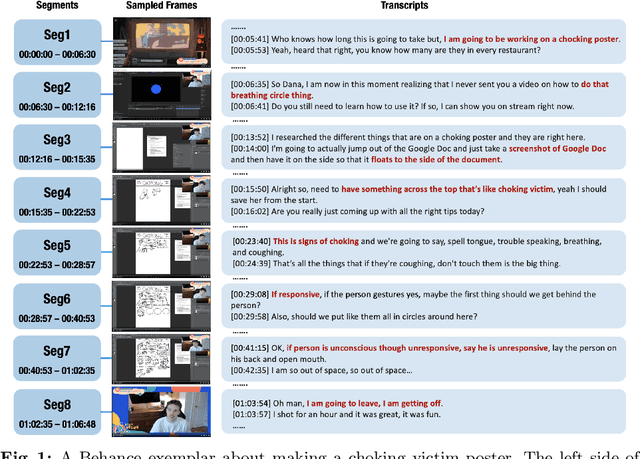
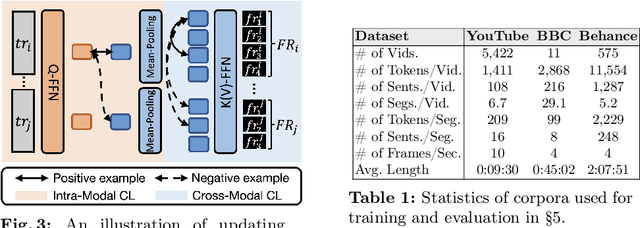
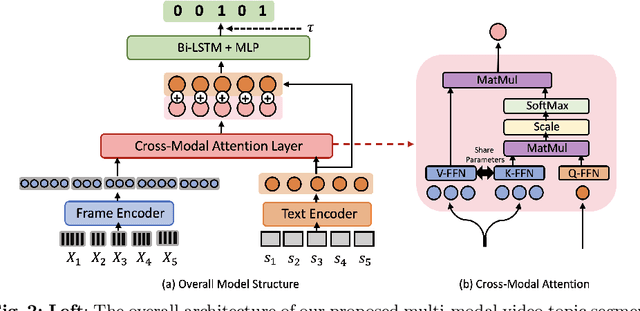
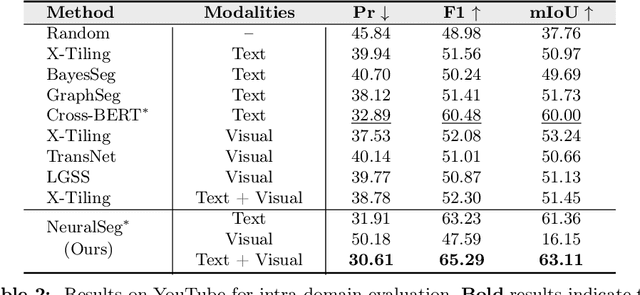
Video topic segmentation unveils the coarse-grained semantic structure underlying videos and is essential for other video understanding tasks. Given the recent surge in multi-modal, relying solely on a single modality is arguably insufficient. On the other hand, prior solutions for similar tasks like video scene/shot segmentation cater to short videos with clear visual shifts but falter for long videos with subtle changes, such as livestreams. In this paper, we introduce a multi-modal video topic segmenter that utilizes both video transcripts and frames, bolstered by a cross-modal attention mechanism. Furthermore, we propose a dual-contrastive learning framework adhering to the unsupervised domain adaptation paradigm, enhancing our model's adaptability to longer, more semantically complex videos. Experiments on short and long video corpora demonstrate that our proposed solution, significantly surpasses baseline methods in terms of both accuracy and transferability, in both intra- and cross-domain settings.
Tracing Influence at Scale: A Contrastive Learning Approach to Linking Public Comments and Regulator Responses
Nov 24, 2023U.S. Federal Regulators receive over one million comment letters each year from businesses, interest groups, and members of the public, all advocating for changes to proposed regulations. These comments are believed to have wide-ranging impacts on public policy. However, measuring the impact of specific comments is challenging because regulators are required to respond to comments but they do not have to specify which comments they are addressing. In this paper, we propose a simple yet effective solution to this problem by using an iterative contrastive method to train a neural model aiming for matching text from public comments to responses written by regulators. We demonstrate that our proposal substantially outperforms a set of selected text-matching baselines on a human-annotated test set. Furthermore, it delivers performance comparable to the most advanced gigantic language model (i.e., GPT-4), and is more cost-effective when handling comments and regulator responses matching in larger scale.
Diversity-Aware Coherence Loss for Improving Neural Topic Models
May 26, 2023

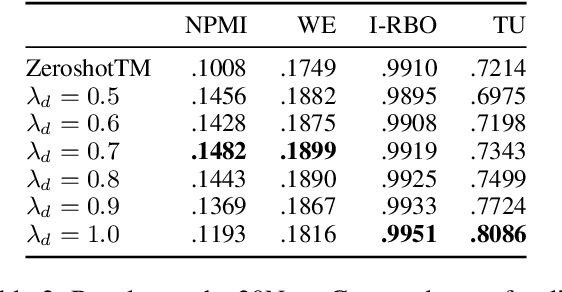

The standard approach for neural topic modeling uses a variational autoencoder (VAE) framework that jointly minimizes the KL divergence between the estimated posterior and prior, in addition to the reconstruction loss. Since neural topic models are trained by recreating individual input documents, they do not explicitly capture the coherence between topic words on the corpus level. In this work, we propose a novel diversity-aware coherence loss that encourages the model to learn corpus-level coherence scores while maintaining a high diversity between topics. Experimental results on multiple datasets show that our method significantly improves the performance of neural topic models without requiring any pretraining or additional parameters.
Improving Topic Segmentation by Injecting Discourse Dependencies
Sep 18, 2022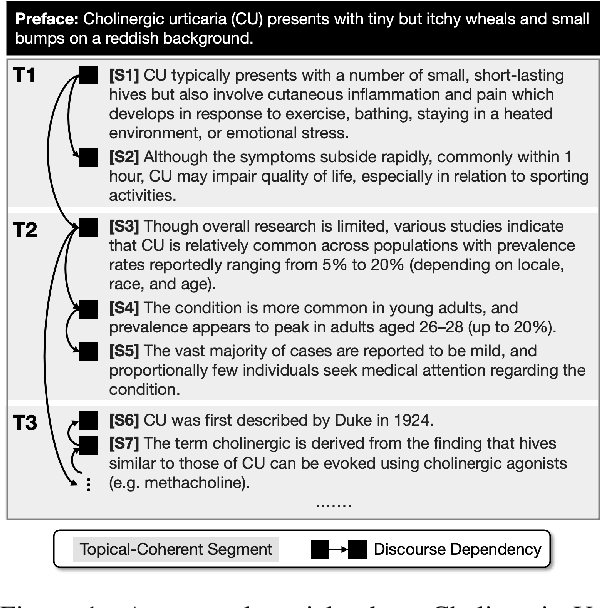
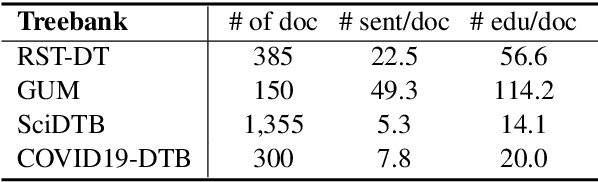
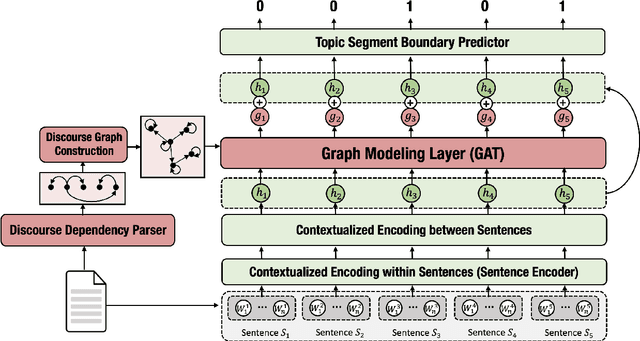
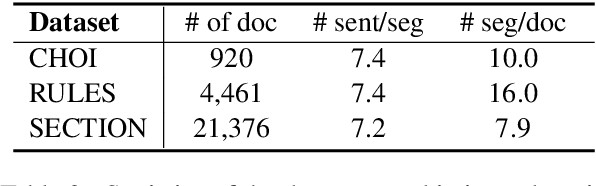
Recent neural supervised topic segmentation models achieve distinguished superior effectiveness over unsupervised methods, with the availability of large-scale training corpora sampled from Wikipedia. These models may, however, suffer from limited robustness and transferability caused by exploiting simple linguistic cues for prediction, but overlooking more important inter-sentential topical consistency. To address this issue, we present a discourse-aware neural topic segmentation model with the injection of above-sentence discourse dependency structures to encourage the model make topic boundary prediction based more on the topical consistency between sentences. Our empirical study on English evaluation datasets shows that injecting above-sentence discourse structures to a neural topic segmenter with our proposed strategy can substantially improve its performances on intra-domain and out-of-domain data, with little increase of model's complexity.
Predicting Above-Sentence Discourse Structure using Distant Supervision from Topic Segmentation
Dec 12, 2021
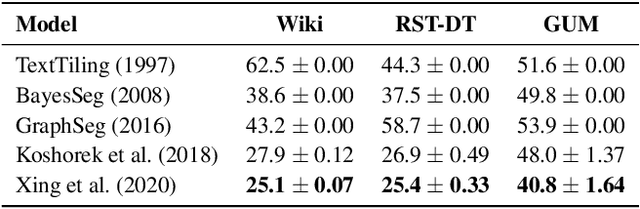
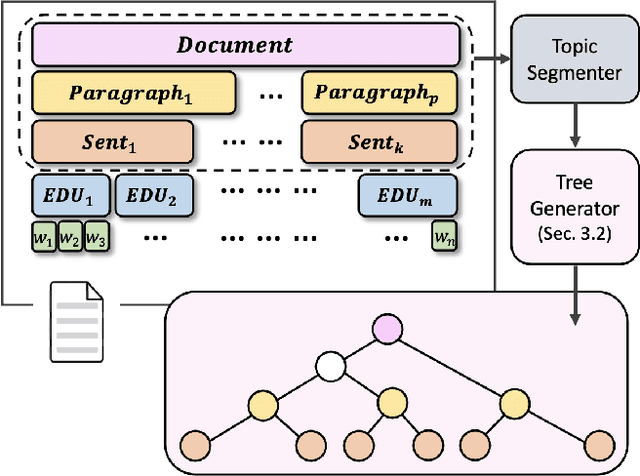
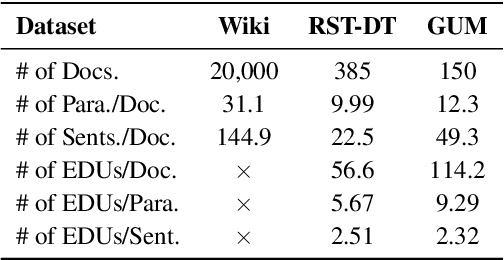
RST-style discourse parsing plays a vital role in many NLP tasks, revealing the underlying semantic/pragmatic structure of potentially complex and diverse documents. Despite its importance, one of the most prevailing limitations in modern day discourse parsing is the lack of large-scale datasets. To overcome the data sparsity issue, distantly supervised approaches from tasks like sentiment analysis and summarization have been recently proposed. Here, we extend this line of research by exploiting distant supervision from topic segmentation, which can arguably provide a strong and oftentimes complementary signal for high-level discourse structures. Experiments on two human-annotated discourse treebanks confirm that our proposal generates accurate tree structures on sentence and paragraph level, consistently outperforming previous distantly supervised models on the sentence-to-document task and occasionally reaching even higher scores on the sentence-to-paragraph level.
Improving Unsupervised Dialogue Topic Segmentation with Utterance-Pair Coherence Scoring
Jun 12, 2021
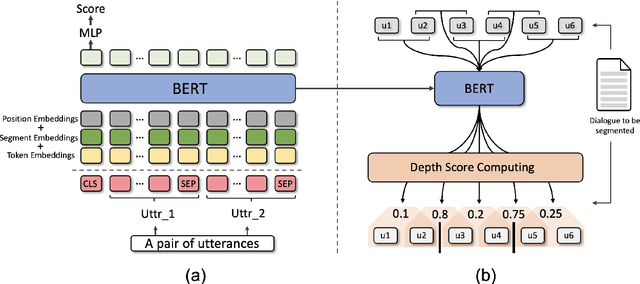
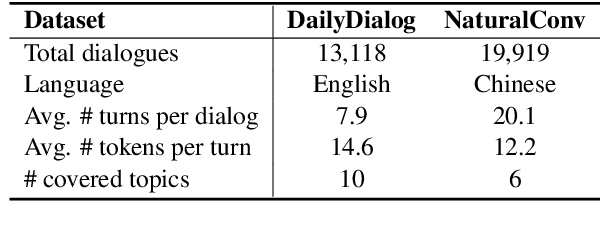
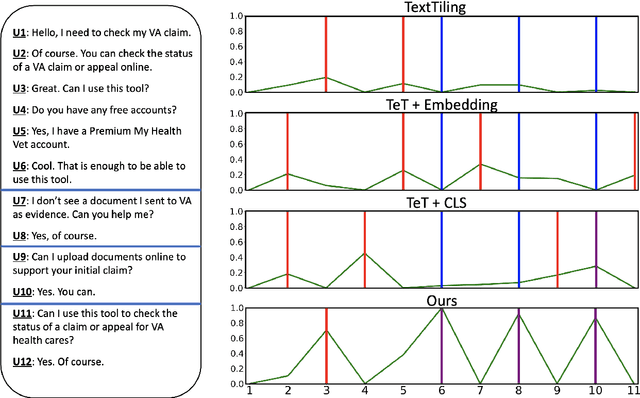
Dialogue topic segmentation is critical in several dialogue modeling problems. However, popular unsupervised approaches only exploit surface features in assessing topical coherence among utterances. In this work, we address this limitation by leveraging supervisory signals from the utterance-pair coherence scoring task. First, we present a simple yet effective strategy to generate a training corpus for utterance-pair coherence scoring. Then, we train a BERT-based neural utterance-pair coherence model with the obtained training corpus. Finally, such model is used to measure the topical relevance between utterances, acting as the basis of the segmentation inference. Experiments on three public datasets in English and Chinese demonstrate that our proposal outperforms the state-of-the-art baselines.
Demoting the Lead Bias in News Summarization via Alternating Adversarial Learning
May 29, 2021
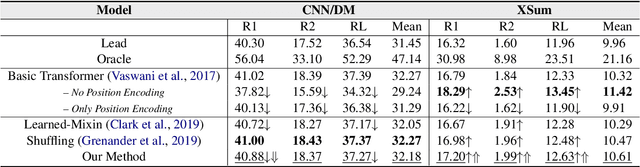
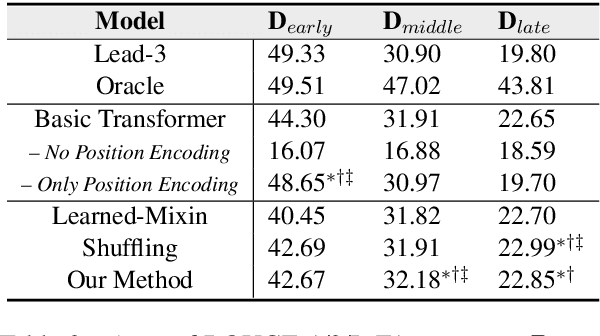
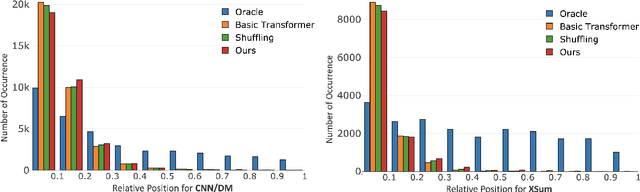
In news articles the lead bias is a common phenomenon that usually dominates the learning signals for neural extractive summarizers, severely limiting their performance on data with different or even no bias. In this paper, we introduce a novel technique to demote lead bias and make the summarizer focus more on the content semantics. Experiments on two news corpora with different degrees of lead bias show that our method can effectively demote the model's learned lead bias and improve its generality on out-of-distribution data, with little to no performance loss on in-distribution data.