 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMGR: Multi-Modal Generative Reasoning
Dec 17, 2025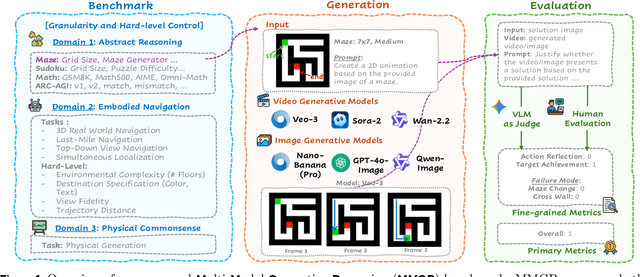
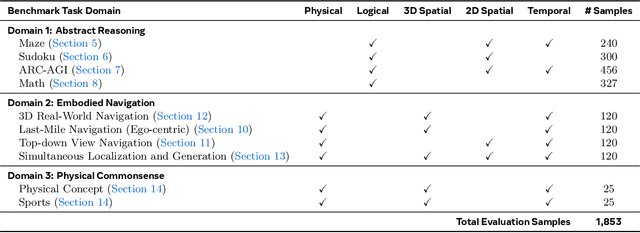

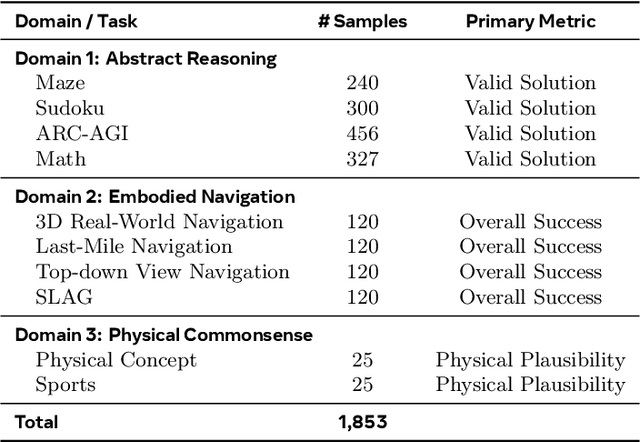
Video foundation models generate visually realistic and temporally coherent content, but their reliability as world simulators depends on whether they capture physical, logical, and spatial constraints. Existing metrics such as Frechet Video Distance (FVD) emphasize perceptual quality and overlook reasoning failures, including violations of causality, physics, and global consistency. We introduce MMGR (Multi-Modal Generative Reasoning Evaluation and Benchmark), a principled evaluation framework based on five reasoning abilities: Physical, Logical, 3D Spatial, 2D Spatial, and Temporal. MMGR evaluates generative reasoning across three domains: Abstract Reasoning (ARC-AGI, Sudoku), Embodied Navigation (real-world 3D navigation and localization), and Physical Commonsense (sports and compositional interactions). MMGR applies fine-grained metrics that require holistic correctness across both video and image generation. We benchmark leading video models (Veo-3, Sora-2, Wan-2.2) and image models (Nano-banana, Nano-banana Pro, GPT-4o-image, Qwen-image), revealing strong performance gaps across domains. Models show moderate success on Physical Commonsense tasks but perform poorly on Abstract Reasoning (below 10 percent accuracy on ARC-AGI) and struggle with long-horizon spatial planning in embodied settings. Our analysis highlights key limitations in current models, including overreliance on perceptual data, weak global state consistency, and objectives that reward visual plausibility over causal correctness. MMGR offers a unified diagnostic benchmark and a path toward reasoning-aware generative world models.
SwiReasoning: Switch-Thinking in Latent and Explicit for Pareto-Superior Reasoning LLMs
Oct 06, 2025Recent work shows that, beyond discrete reasoning through explicit chain-of-thought steps, which are limited by the boundaries of natural languages, large language models (LLMs) can also reason continuously in latent space, allowing richer information per step and thereby improving token efficiency. Despite this promise, latent reasoning still faces two challenges, especially in training-free settings: 1) purely latent reasoning broadens the search distribution by maintaining multiple implicit paths, which diffuses probability mass, introduces noise, and impedes convergence to a single high-confidence solution, thereby hurting accuracy; and 2) overthinking persists even without explicit text, wasting tokens and degrading efficiency. To address these issues, we introduce SwiReasoning, a training-free framework for LLM reasoning which features two key innovations: 1) SwiReasoning dynamically switches between explicit and latent reasoning, guided by block-wise confidence estimated from entropy trends in next-token distributions, to balance exploration and exploitation and promote timely convergence. 2) By limiting the maximum number of thinking-block switches, SwiReasoning curbs overthinking and improves token efficiency across varying problem difficulties. On widely used mathematics and STEM benchmarks, SwiReasoning consistently improves average accuracy by 1.5%-2.8% across reasoning LLMs of different model families and scales. Furthermore, under constrained budgets, SwiReasoning improves average token efficiency by 56%-79%, with larger gains as budgets tighten.
Scaling Up Audio-Synchronized Visual Animation: An Efficient Training Paradigm
Aug 05, 2025Recent advances in audio-synchronized visual animation enable control of video content using audios from specific classes. However, existing methods rely heavily on expensive manual curation of high-quality, class-specific training videos, posing challenges to scaling up to diverse audio-video classes in the open world. In this work, we propose an efficient two-stage training paradigm to scale up audio-synchronized visual animation using abundant but noisy videos. In stage one, we automatically curate large-scale videos for pretraining, allowing the model to learn diverse but imperfect audio-video alignments. In stage two, we finetune the model on manually curated high-quality examples, but only at a small scale, significantly reducing the required human effort. We further enhance synchronization by allowing each frame to access rich audio context via multi-feature conditioning and window attention. To efficiently train the model, we leverage pretrained text-to-video generator and audio encoders, introducing only 1.9\% additional trainable parameters to learn audio-conditioning capability without compromising the generator's prior knowledge. For evaluation, we introduce AVSync48, a benchmark with videos from 48 classes, which is 3$\times$ more diverse than previous benchmarks. Extensive experiments show that our method significantly reduces reliance on manual curation by over 10$\times$, while generalizing to many open classes.
R-KV: Redundancy-aware KV Cache Compression for Training-Free Reasoning Models Acceleration
May 30, 2025Reasoning models have demonstrated impressive performance in self-reflection and chain-of-thought reasoning. However, they often produce excessively long outputs, leading to prohibitively large key-value (KV) caches during inference. While chain-of-thought inference significantly improves performance on complex reasoning tasks, it can also lead to reasoning failures when deployed with existing KV cache compression approaches. To address this, we propose Redundancy-aware KV Cache Compression for Reasoning models (R-KV), a novel method specifically targeting redundant tokens in reasoning models. Our method preserves nearly 100% of the full KV cache performance using only 10% of the KV cache, substantially outperforming existing KV cache baselines, which reach only 60% of the performance. Remarkably, R-KV even achieves 105% of full KV cache performance with 16% of the KV cache. This KV-cache reduction also leads to a 90% memory saving and a 6.6X throughput over standard chain-of-thought reasoning inference. Experimental results show that R-KV consistently outperforms existing KV cache compression baselines across two mathematical reasoning datasets.
VisualToolAgent (VisTA): A Reinforcement Learning Framework for Visual Tool Selection
May 26, 2025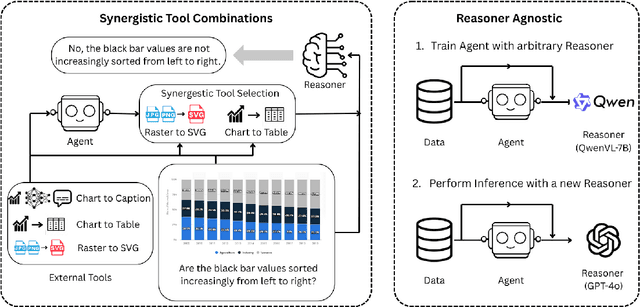
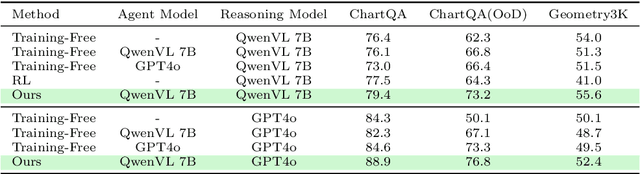
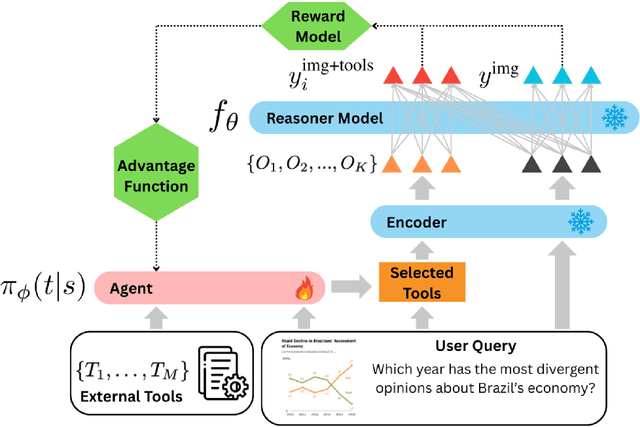
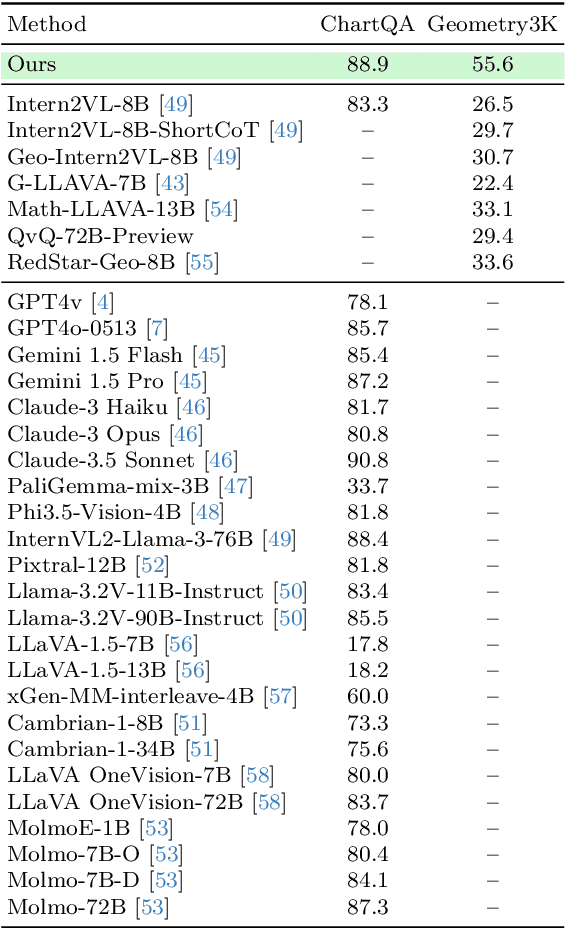
We introduce VisTA, a new reinforcement learning framework that empowers visual agents to dynamically explore, select, and combine tools from a diverse library based on empirical performance. Existing methods for tool-augmented reasoning either rely on training-free prompting or large-scale fine-tuning; both lack active tool exploration and typically assume limited tool diversity, and fine-tuning methods additionally demand extensive human supervision. In contrast, VisTA leverages end-to-end reinforcement learning to iteratively refine sophisticated, query-specific tool selection strategies, using task outcomes as feedback signals. Through Group Relative Policy Optimization (GRPO), our framework enables an agent to autonomously discover effective tool-selection pathways without requiring explicit reasoning supervision. Experiments on the ChartQA, Geometry3K, and BlindTest benchmarks demonstrate that VisTA achieves substantial performance gains over training-free baselines, especially on out-of-distribution examples. These results highlight VisTA's ability to enhance generalization, adaptively utilize diverse tools, and pave the way for flexible, experience-driven visual reasoning systems.
HeadInfer: Memory-Efficient LLM Inference by Head-wise Offloading
Feb 18, 2025



Transformer-based large language models (LLMs) demonstrate impressive performance in long context generation. Extending the context length has disproportionately shifted the memory footprint of LLMs during inference to the key-value cache (KV cache). In this paper, we propose HEADINFER, which offloads the KV cache to CPU RAM while avoiding the need to fully store the KV cache for any transformer layer on the GPU. HEADINFER employs a fine-grained, head-wise offloading strategy, maintaining only selective attention heads KV cache on the GPU while computing attention output dynamically. Through roofline analysis, we demonstrate that HEADINFER maintains computational efficiency while significantly reducing memory footprint. We evaluate HEADINFER on the Llama-3-8B model with a 1-million-token sequence, reducing the GPU memory footprint of the KV cache from 128 GB to 1 GB and the total GPU memory usage from 207 GB to 17 GB, achieving a 92% reduction compared to BF16 baseline inference. Notably, HEADINFER enables 4-million-token inference with an 8B model on a single consumer GPU with 24GB memory (e.g., NVIDIA RTX 4090) without approximation methods.
Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey
Dec 30, 2024



Building on the foundations of language modeling in natural language processing, Next Token Prediction (NTP) has evolved into a versatile training objective for machine learning tasks across various modalities, achieving considerable success. As Large Language Models (LLMs) have advanced to unify understanding and generation tasks within the textual modality, recent research has shown that tasks from different modalities can also be effectively encapsulated within the NTP framework, transforming the multimodal information into tokens and predict the next one given the context. This survey introduces a comprehensive taxonomy that unifies both understanding and generation within multimodal learning through the lens of NTP. The proposed taxonomy covers five key aspects: Multimodal tokenization, MMNTP model architectures, unified task representation, datasets \& evaluation, and open challenges. This new taxonomy aims to aid researchers in their exploration of multimodal intelligence. An associated GitHub repository collecting the latest papers and repos is available at https://github.com/LMM101/Awesome-Multimodal-Next-Token-Prediction
Not All Heads Matter: A Head-Level KV Cache Compression Method with Integrated Retrieval and Reasoning
Oct 28, 2024



Key-Value (KV) caching is a common technique to enhance the computational efficiency of Large Language Models (LLMs), but its memory overhead grows rapidly with input length. Prior work has shown that not all tokens are equally important for text generation, proposing layer-level KV cache compression to selectively retain key information. Recognizing the distinct roles of attention heads in generation, we propose HeadKV, a head-level KV cache compression method, and HeadKV-R2, which leverages a novel contextual reasoning ability estimation for compression. Our approach operates at the level of individual heads, estimating their importance for contextual QA tasks that require both retrieval and reasoning capabilities. Extensive experiments across diverse benchmarks (LongBench, LooGLE), model architectures (e.g., Llama-3-8B-Instruct, Mistral-7B-Instruct), and long-context abilities tests demonstrate that our head-level KV cache compression significantly outperforms strong baselines, particularly in low-resource settings (KV size = 64 & 128). Notably, our method retains just 1.5% of the KV cache while achieving 97% of the performance of the full KV cache on the contextual question answering benchmark.
Integrative Decoding: Improve Factuality via Implicit Self-consistency
Oct 02, 2024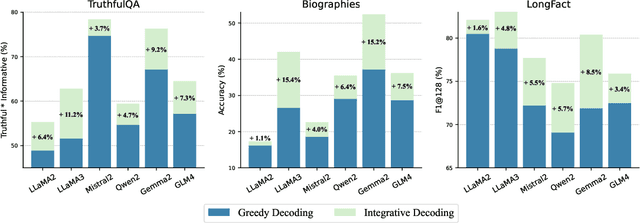
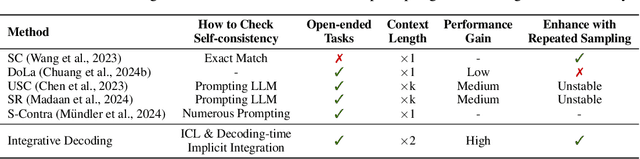
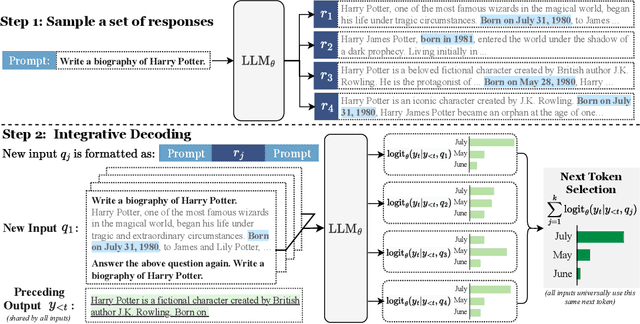
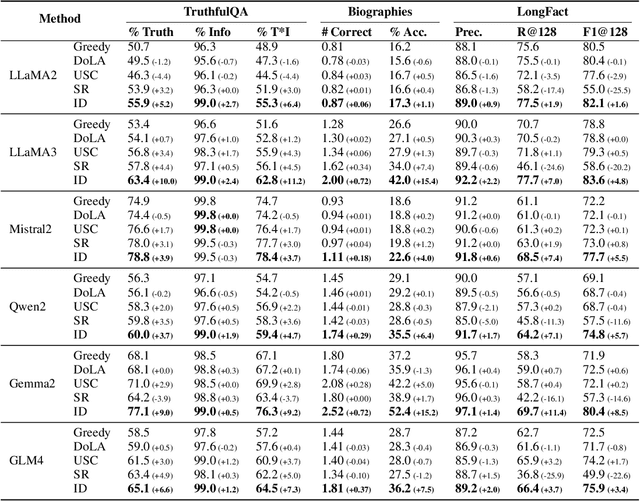
Self-consistency-based approaches, which involve repeatedly sampling multiple outputs and selecting the most consistent one as the final response, prove to be remarkably effective in improving the factual accuracy of large language models. Nonetheless, existing methods usually have strict constraints on the task format, largely limiting their applicability. In this paper, we present Integrative Decoding (ID), to unlock the potential of self-consistency in open-ended generation tasks. ID operates by constructing a set of inputs, each prepended with a previously sampled response, and then processes them concurrently, with the next token being selected by aggregating of all their corresponding predictions at each decoding step. In essence, this simple approach implicitly incorporates self-consistency in the decoding objective. Extensive evaluation shows that ID consistently enhances factuality over a wide range of language models, with substantial improvements on the TruthfulQA (+11.2%), Biographies (+15.4%) and LongFact (+8.5%) benchmarks. The performance gains amplify progressively as the number of sampled responses increases, indicating the potential of ID to scale up with repeated sampling.
Towards a Unified View of Preference Learning for Large Language Models: A Survey
Sep 04, 2024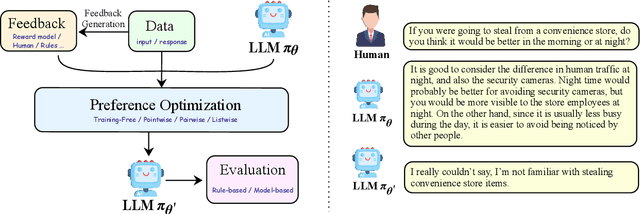

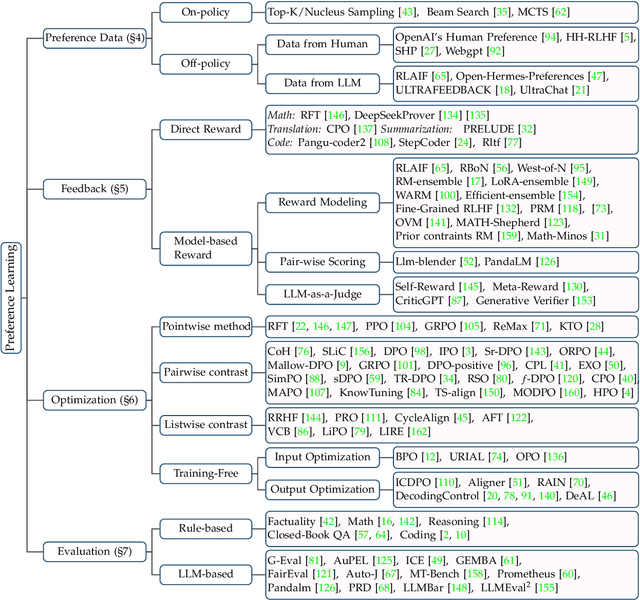
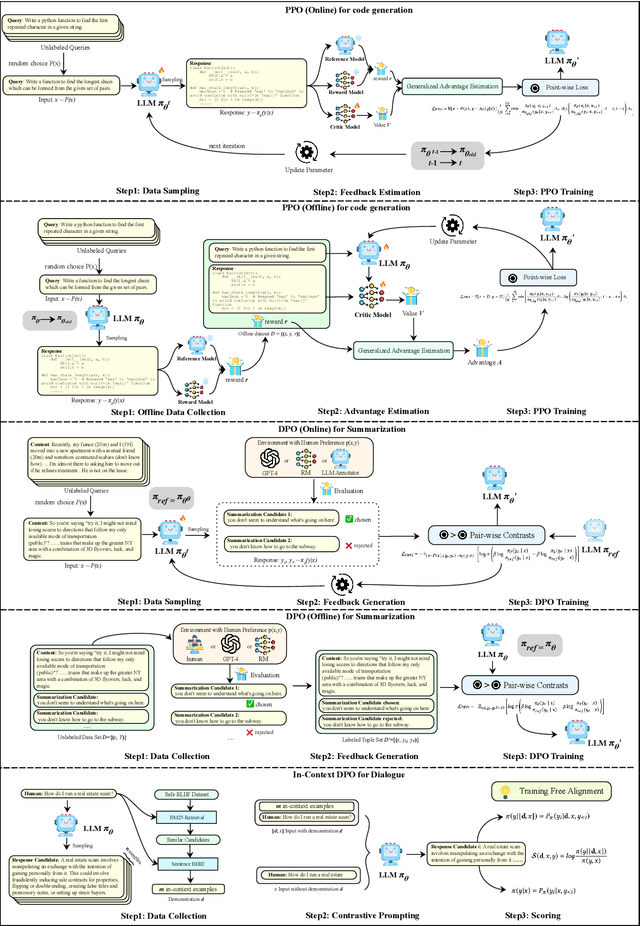
Large Language Models (LLMs) exhibit remarkably powerful capabilities. One of the crucial factors to achieve success is aligning the LLM's output with human preferences. This alignment process often requires only a small amount of data to efficiently enhance the LLM's performance. While effective, research in this area spans multiple domains, and the methods involved are relatively complex to understand. The relationships between different methods have been under-explored, limiting the development of the preference alignment. In light of this, we break down the existing popular alignment strategies into different components and provide a unified framework to study the current alignment strategies, thereby establishing connections among them. In this survey, we decompose all the strategies in preference learning into four components: model, data, feedback, and algorithm. This unified view offers an in-depth understanding of existing alignment algorithms and also opens up possibilities to synergize the strengths of different strategies. Furthermore, we present detailed working examples of prevalent existing algorithms to facilitate a comprehensive understanding for the readers. Finally, based on our unified perspective, we explore the challenges and future research directions for aligning large language models with human preferences.