 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Task Defense: Instruction-Tuning LLMs for Content Safety
May 24, 2024



Recent studies reveal that Large Language Models (LLMs) face challenges in balancing safety with utility, particularly when processing long texts for NLP tasks like summarization and translation. Despite defenses against malicious short questions, the ability of LLMs to safely handle dangerous long content, such as manuals teaching illicit activities, remains unclear. Our work aims to develop robust defenses for LLMs in processing malicious documents alongside benign NLP task queries. We introduce a defense dataset comprised of safety-related examples and propose single-task and mixed-task losses for instruction tuning. Our empirical results demonstrate that LLMs can significantly enhance their capacity to safely manage dangerous content with appropriate instruction tuning. Additionally, strengthening the defenses of tasks most susceptible to misuse is effective in protecting LLMs against processing harmful information. We also observe that trade-offs between utility and safety exist in defense strategies, where Llama2, utilizing our proposed approach, displays a significantly better balance compared to Llama1.
Medical Vision-Language Pre-Training for Brain Abnormalities
Apr 27, 2024Vision-language models have become increasingly powerful for tasks that require an understanding of both visual and linguistic elements, bridging the gap between these modalities. In the context of multimodal clinical AI, there is a growing need for models that possess domain-specific knowledge, as existing models often lack the expertise required for medical applications. In this paper, we take brain abnormalities as an example to demonstrate how to automatically collect medical image-text aligned data for pretraining from public resources such as PubMed. In particular, we present a pipeline that streamlines the pre-training process by initially collecting a large brain image-text dataset from case reports and published journals and subsequently constructing a high-performance vision-language model tailored to specific medical tasks. We also investigate the unique challenge of mapping subfigures to subcaptions in the medical domain. We evaluated the resulting model with quantitative and qualitative intrinsic evaluations. The resulting dataset and our code can be found here https://github.com/masoud-monajati/MedVL_pretraining_pipeline
BERTHop: An Effective Vision-and-Language Model for Chest X-ray Disease Diagnosis
Aug 10, 2021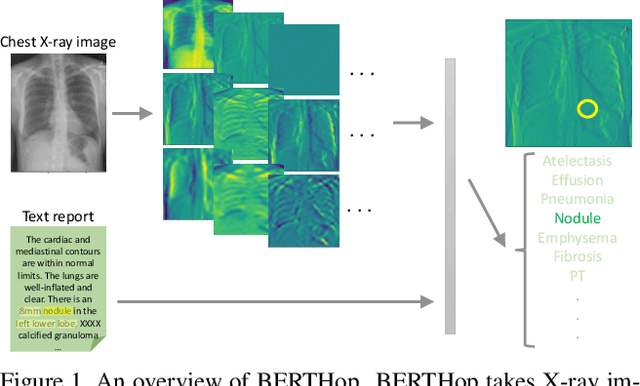
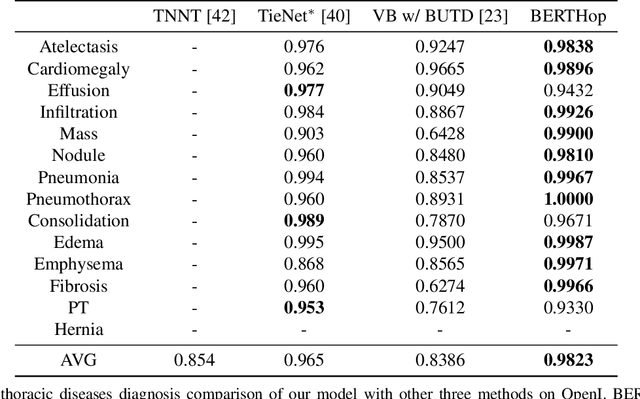
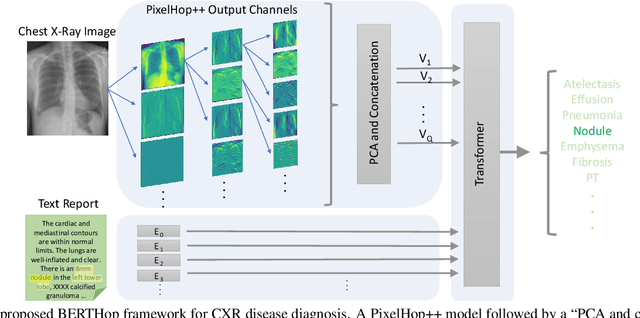
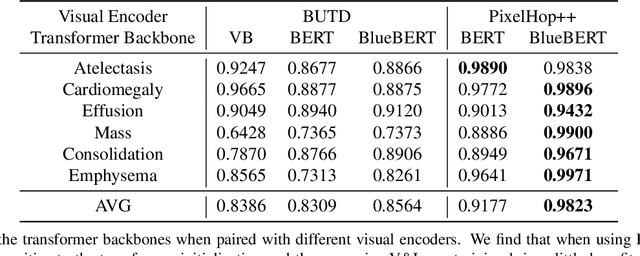
Vision-and-language(V&L) models take image and text as input and learn to capture the associations between them. Prior studies show that pre-trained V&L models can significantly improve the model performance for downstream tasks such as Visual Question Answering (VQA). However, V&L models are less effective when applied in the medical domain (e.g., on X-ray images and clinical notes) due to the domain gap. In this paper, we investigate the challenges of applying pre-trained V&L models in medical applications. In particular, we identify that the visual representation in general V&L models is not suitable for processing medical data. To overcome this limitation, we propose BERTHop, a transformer-based model based on PixelHop++ and VisualBERT, for better capturing the associations between the two modalities. Experiments on the OpenI dataset, a commonly used thoracic disease diagnosis benchmark, show that BERTHop achieves an average Area Under the Curve (AUC) of 98.12% which is 1.62% higher than state-of-the-art (SOTA) while it is trained on a 9 times smaller dataset.