 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMedPrompt: A New Framework for Optimizing LLM Medical Prompts Using Textual Gradients
Feb 21, 2025Large language models (LLMs) have demonstrated increasingly sophisticated performance in medical and other fields of knowledge. Traditional methods of creating specialist LLMs require extensive fine-tuning and training of models on large datasets. Recently, prompt engineering, instead of fine-tuning, has shown potential to boost the performance of general foundation models. However, prompting methods such as chain-of-thought (CoT) may not be suitable for all subspecialty, and k-shot approaches may introduce irrelevant tokens into the context space. We present AutoMedPrompt, which explores the use of textual gradients to elicit medically relevant reasoning through system prompt optimization. AutoMedPrompt leverages TextGrad's automatic differentiation via text to improve the ability of general foundation LLMs. We evaluated AutoMedPrompt on Llama 3, an open-source LLM, using several QA benchmarks, including MedQA, PubMedQA, and the nephrology subspecialty-specific NephSAP. Our results show that prompting with textual gradients outperforms previous methods on open-source LLMs and surpasses proprietary models such as GPT-4, Claude 3 Opus, and Med-PaLM 2. AutoMedPrompt sets a new state-of-the-art (SOTA) performance on PubMedQA with an accuracy of 82.6$\%$, while also outperforming previous prompting strategies on open-sourced models for MedQA (77.7$\%$) and NephSAP (63.8$\%$).
Integrating Deep Metric Learning with Coreset for Active Learning in 3D Segmentation
Nov 24, 2024



Deep learning has seen remarkable advancements in machine learning, yet it often demands extensive annotated data. Tasks like 3D semantic segmentation impose a substantial annotation burden, especially in domains like medicine, where expert annotations drive up the cost. Active learning (AL) holds great potential to alleviate this annotation burden in 3D medical segmentation. The majority of existing AL methods, however, are not tailored to the medical domain. While weakly-supervised methods have been explored to reduce annotation burden, the fusion of AL with weak supervision remains unexplored, despite its potential to significantly reduce annotation costs. Additionally, there is little focus on slice-based AL for 3D segmentation, which can also significantly reduce costs in comparison to conventional volume-based AL. This paper introduces a novel metric learning method for Coreset to perform slice-based active learning in 3D medical segmentation. By merging contrastive learning with inherent data groupings in medical imaging, we learn a metric that emphasizes the relevant differences in samples for training 3D medical segmentation models. We perform comprehensive evaluations using both weak and full annotations across four datasets (medical and non-medical). Our findings demonstrate that our approach surpasses existing active learning techniques on both weak and full annotations and obtains superior performance with low-annotation budgets which is crucial in medical imaging. Source code for this project is available in the supplementary materials and on GitHub: https://github.com/arvindmvepa/al-seg.
Self-supervised denoising of visual field data improves detection of glaucoma progression
Nov 19, 2024Perimetric measurements provide insight into a patient's peripheral vision and day-to-day functioning and are the main outcome measure for identifying progression of visual damage from glaucoma. However, visual field data can be noisy, exhibiting high variance, especially with increasing damage. In this study, we demonstrate the utility of self-supervised deep learning in denoising visual field data from over 4000 patients to enhance its signal-to-noise ratio and its ability to detect true glaucoma progression. We deployed both a variational autoencoder (VAE) and a masked autoencoder to determine which self-supervised model best smooths the visual field data while reconstructing salient features that are less noisy and more predictive of worsening disease. Our results indicate that including a categorical p-value at every visual field location improves the smoothing of visual field data. Masked autoencoders led to cleaner denoised data than previous methods, such as variational autoencoders. A 4.7% increase in detection of progressing eyes with pointwise linear regression (PLR) was observed. The masked and variational autoencoders' smoothed data predicted glaucoma progression 2.3 months earlier when p-values were included compared to when they were not. The faster prediction of time to progression (TTP) and the higher percentage progression detected support our hypothesis that masking out visual field elements during training while including p-values at each location would improve the task of detection of visual field progression. Our study has clinically relevant implications regarding masking when training neural networks to denoise visual field data, resulting in earlier and more accurate detection of glaucoma progression. This denoising model can be integrated into future models for visual field analysis to enhance detection of glaucoma progression.
Adversarial Databases Improve Success in Retrieval-based Large Language Models
Jul 19, 2024Open-source LLMs have shown great potential as fine-tuned chatbots, and demonstrate robust abilities in reasoning and surpass many existing benchmarks. Retrieval-Augmented Generation (RAG) is a technique for improving the performance of LLMs on tasks that the models weren't explicitly trained on, by leveraging external knowledge databases. Numerous studies have demonstrated the effectiveness of RAG to more successfully accomplish downstream tasks when using vector datasets that consist of relevant background information. It has been implicitly assumed by those in the field that if adversarial background information is utilized in this context, that the success of using a RAG-based approach would be nonexistent or even negatively impact the results. To address this assumption, we tested several open-source LLMs on the ability of RAG to improve their success in answering multiple-choice questions (MCQ) in the medical subspecialty field of Nephrology. Unlike previous studies, we examined the effect of RAG in utilizing both relevant and adversarial background databases. We set up several open-source LLMs, including Llama 3, Phi-3, Mixtral 8x7b, Zephyr$\beta$, and Gemma 7B Instruct, in a zero-shot RAG pipeline. As adversarial sources of information, text from the Bible and a Random Words generated database were used for comparison. Our data show that most of the open-source LLMs improve their multiple-choice test-taking success as expected when incorporating relevant information vector databases. Surprisingly however, adversarial Bible text significantly improved the success of many LLMs and even random word text improved test taking ability of some of the models. In summary, our results demonstrate for the first time the countertintuitive ability of adversarial information datasets to improve the RAG-based LLM success.
Predicting Outcomes in Video Games with Long Short Term Memory Networks
Feb 24, 2024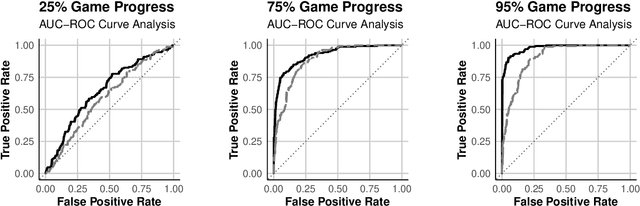
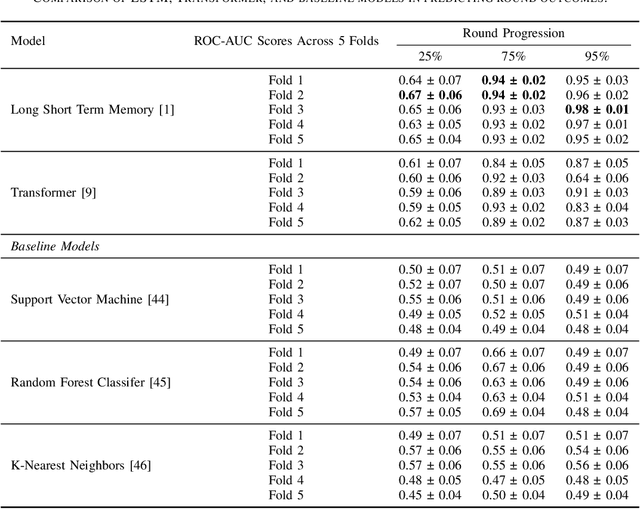
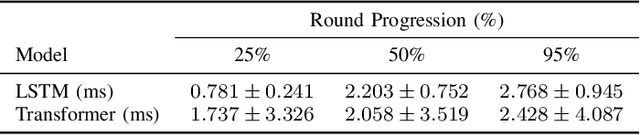
Forecasting winners in E-sports with real-time analytics has the potential to further engage audiences watching major tournament events. However, making such real-time predictions is challenging due to unpredictable variables within the game involving diverse player strategies and decision-making. Our work attempts to enhance audience engagement within video game tournaments by introducing a real-time method of predicting wins. Our Long Short Term Memory Network (LSTMs) based approach enables efficient predictions of win-lose outcomes by only using the health indicator of each player as a time series. As a proof of concept, we evaluate our model's performance within a classic, two-player arcade game, Super Street Fighter II Turbo. We also benchmark our method against state of the art methods for time series forecasting; i.e. Transformer models found in large language models (LLMs). Finally, we open-source our data set and code in hopes of furthering work in predictive analysis for arcade games.
Nodule detection and generation on chest X-rays: NODE21 Challenge
Jan 04, 2024



Pulmonary nodules may be an early manifestation of lung cancer, the leading cause of cancer-related deaths among both men and women. Numerous studies have established that deep learning methods can yield high-performance levels in the detection of lung nodules in chest X-rays. However, the lack of gold-standard public datasets slows down the progression of the research and prevents benchmarking of methods for this task. To address this, we organized a public research challenge, NODE21, aimed at the detection and generation of lung nodules in chest X-rays. While the detection track assesses state-of-the-art nodule detection systems, the generation track determines the utility of nodule generation algorithms to augment training data and hence improve the performance of the detection systems. This paper summarizes the results of the NODE21 challenge and performs extensive additional experiments to examine the impact of the synthetically generated nodule training images on the detection algorithm performance.
A Comparative Study of Open-Source Large Language Models, GPT-4 and Claude 2: Multiple-Choice Test Taking in Nephrology
Aug 09, 2023In recent years, there have been significant breakthroughs in the field of natural language processing, particularly with the development of large language models (LLMs). These LLMs have showcased remarkable capabilities on various benchmarks. In the healthcare field, the exact role LLMs and other future AI models will play remains unclear. There is a potential for these models in the future to be used as part of adaptive physician training, medical co-pilot applications, and digital patient interaction scenarios. The ability of AI models to participate in medical training and patient care will depend in part on their mastery of the knowledge content of specific medical fields. This study investigated the medical knowledge capability of LLMs, specifically in the context of internal medicine subspecialty multiple-choice test-taking ability. We compared the performance of several open-source LLMs (Koala 7B, Falcon 7B, Stable-Vicuna 13B, and Orca Mini 13B), to GPT-4 and Claude 2 on multiple-choice questions in the field of Nephrology. Nephrology was chosen as an example of a particularly conceptually complex subspecialty field within internal medicine. The study was conducted to evaluate the ability of LLM models to provide correct answers to nephSAP (Nephrology Self-Assessment Program) multiple-choice questions. The overall success of open-sourced LLMs in answering the 858 nephSAP multiple-choice questions correctly was 17.1% - 25.5%. In contrast, Claude 2 answered 54.4% of the questions correctly, whereas GPT-4 achieved a score of 73.3%. We show that current widely used open-sourced LLMs do poorly in their ability for zero-shot reasoning when compared to GPT-4 and Claude 2. The findings of this study potentially have significant implications for the future of subspecialty medical training and patient care.
BERTHop: An Effective Vision-and-Language Model for Chest X-ray Disease Diagnosis
Aug 10, 2021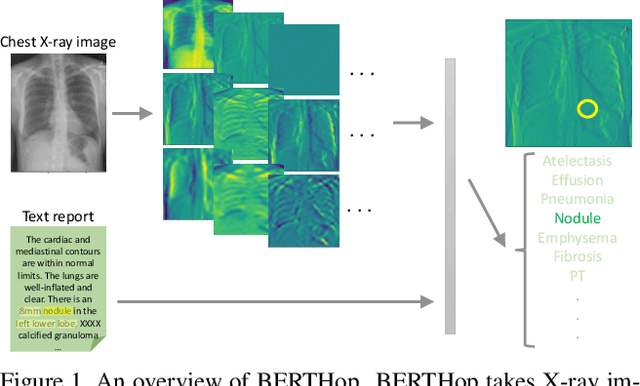
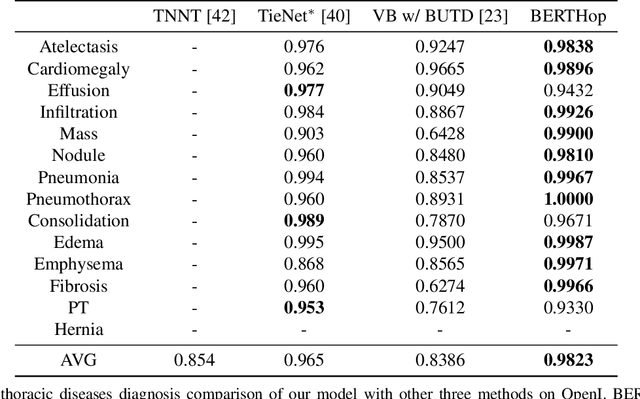
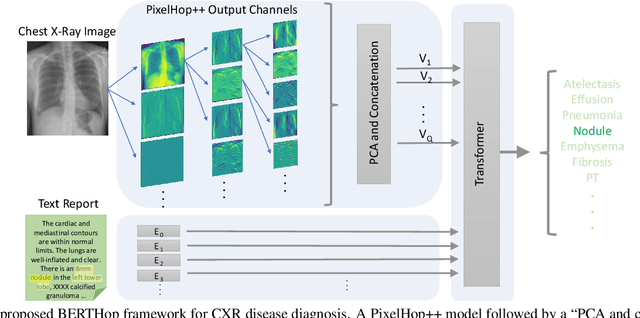
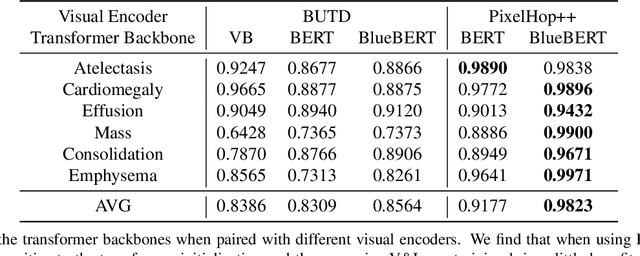
Vision-and-language(V&L) models take image and text as input and learn to capture the associations between them. Prior studies show that pre-trained V&L models can significantly improve the model performance for downstream tasks such as Visual Question Answering (VQA). However, V&L models are less effective when applied in the medical domain (e.g., on X-ray images and clinical notes) due to the domain gap. In this paper, we investigate the challenges of applying pre-trained V&L models in medical applications. In particular, we identify that the visual representation in general V&L models is not suitable for processing medical data. To overcome this limitation, we propose BERTHop, a transformer-based model based on PixelHop++ and VisualBERT, for better capturing the associations between the two modalities. Experiments on the OpenI dataset, a commonly used thoracic disease diagnosis benchmark, show that BERTHop achieves an average Area Under the Curve (AUC) of 98.12% which is 1.62% higher than state-of-the-art (SOTA) while it is trained on a 9 times smaller dataset.
Intra-Domain Task-Adaptive Transfer Learning to Determine Acute Ischemic Stroke Onset Time
Nov 05, 2020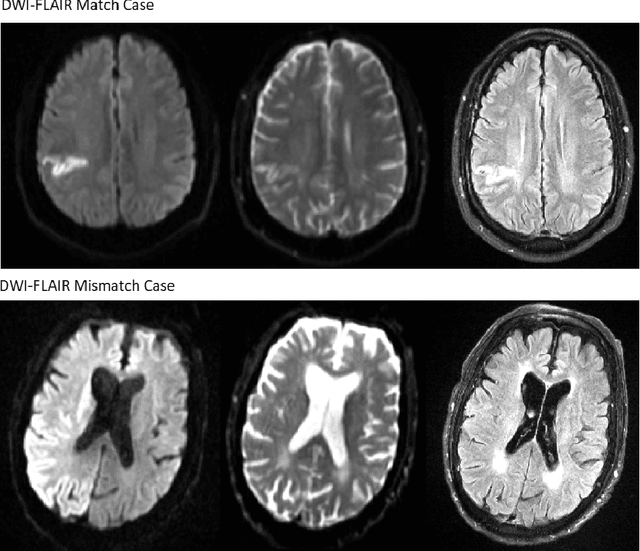
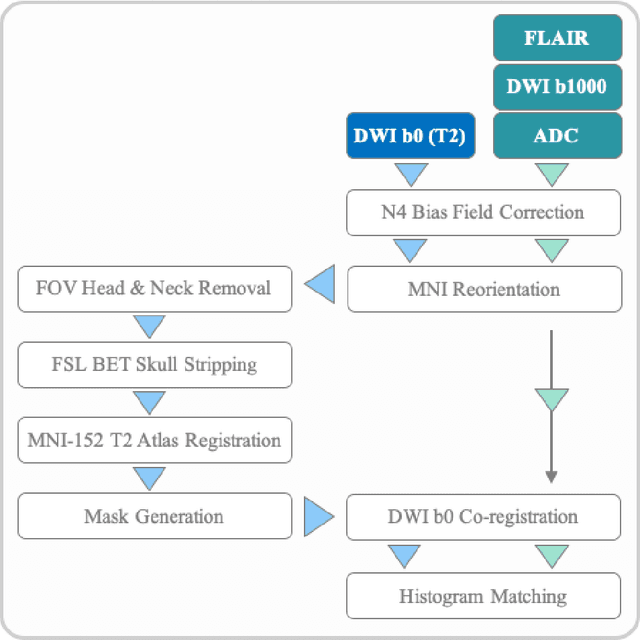
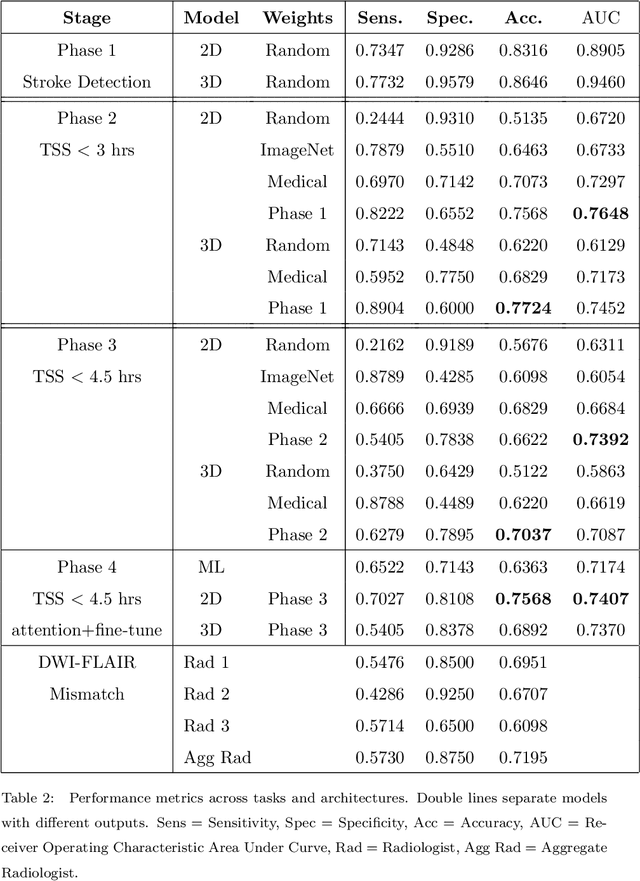
Treatment of acute ischemic strokes (AIS) is largely contingent upon the time since stroke onset (TSS). However, TSS may not be readily available in up to 25% of patients with unwitnessed AIS. Current clinical guidelines for patients with unknown TSS recommend the use of MRI to determine eligibility for thrombolysis, but radiology assessments have high inter-reader variability. In this work, we present deep learning models that leverage MRI diffusion series to classify TSS based on clinically validated thresholds. We propose an intra-domain task-adaptive transfer learning method, which involves training a model on an easier clinical task (stroke detection) and then refining the model with different binary thresholds of TSS. We apply this approach to both 2D and 3D CNN architectures with our top model achieving an ROC-AUC value of 0.74, with a sensitivity of 0.70 and a specificity of 0.81 for classifying TSS < 4.5 hours. Our pretrained models achieve better classification metrics than the models trained from scratch, and these metrics exceed those of previously published models applied to our dataset. Furthermore, our pipeline accommodates a more inclusive patient cohort than previous work, as we did not exclude imaging studies based on clinical, demographic, or image processing criteria. When applied to this broad spectrum of patients, our deep learning model achieves an overall accuracy of 75.78% when classifying TSS < 4.5 hours, carrying potential therapeutic implications for patients with unknown TSS.
Conditional GAN for Prediction of Glaucoma Progression with Macular Optical Coherence Tomography
Sep 28, 2020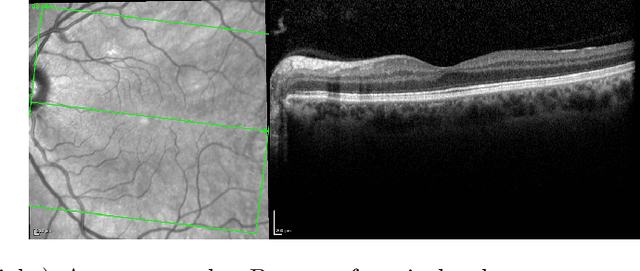
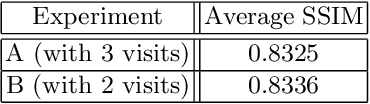
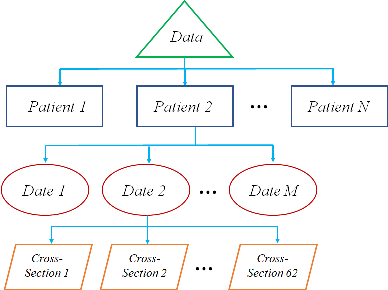
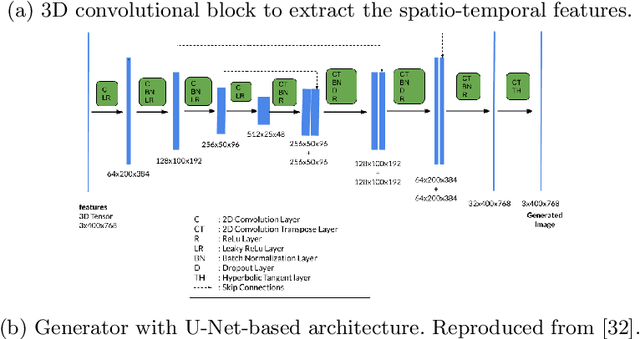
The estimation of glaucoma progression is a challenging task as the rate of disease progression varies among individuals in addition to other factors such as measurement variability and the lack of standardization in defining progression. Structural tests, such as thickness measurements of the retinal nerve fiber layer or the macula with optical coherence tomography (OCT), are able to detect anatomical changes in glaucomatous eyes. Such changes may be observed before any functional damage. In this work, we built a generative deep learning model using the conditional GAN architecture to predict glaucoma progression over time. The patient's OCT scan is predicted from three or two prior measurements. The predicted images demonstrate high similarity with the ground truth images. In addition, our results suggest that OCT scans obtained from only two prior visits may actually be sufficient to predict the next OCT scan of the patient after six months.