 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Sim-to-Real Reinforcement Learning for Robot VLAs with Generative 3D Worlds
Mar 19, 2026The strong performance of large vision-language models (VLMs) trained with reinforcement learning (RL) has motivated similar approaches for fine-tuning vision-language-action (VLA) models in robotics. Many recent works fine-tune VLAs directly in the real world to avoid addressing the sim-to-real gap. While real-world RL circumvents sim-to-real issues, it inherently limits the generality of the resulting VLA, as scaling scene and object diversity in the physical world is prohibitively difficult. This leads to the paradoxical outcome of transforming a broadly pretrained model into an overfitted, scene-specific policy. Training in simulation can instead provide access to diverse scenes, but designing those scenes is also costly. In this work, we show that VLAs can be RL fine-tuned without sacrificing generality and with reduced labor by leveraging 3D world generative models. Using these models together with a language-driven scene designer, we generate hundreds of diverse interactive scenes containing unique objects and backgrounds, enabling scalable and highly parallel policy learning. Starting from a pretrained imitation baseline, our approach increases simulation success from 9.7% to 79.8% while achieving a 1.25$\times$ speedup in task completion time. We further demonstrate successful sim-to-real transfer enabled by the quality of the generated digital twins together with domain randomization, improving real-world success from 21.7% to 75% and achieving a 1.13$\times$ speedup. Finally, we further highlight the benefits of leveraging the effectively unlimited data from 3D world generative models through an ablation study showing that increasing scene diversity directly improves zero-shot generalization.
Rapidly Learning Soft Robot Control via Implicit Time-Stepping
Nov 10, 2025



With the explosive growth of rigid-body simulators, policy learning in simulation has become the de facto standard for most rigid morphologies. In contrast, soft robotic simulation frameworks remain scarce and are seldom adopted by the soft robotics community. This gap stems partly from the lack of easy-to-use, general-purpose frameworks and partly from the high computational cost of accurately simulating continuum mechanics, which often renders policy learning infeasible. In this work, we demonstrate that rapid soft robot policy learning is indeed achievable via implicit time-stepping. Our simulator of choice, DisMech, is a general-purpose, fully implicit soft-body simulator capable of handling both soft dynamics and frictional contact. We further introduce delta natural curvature control, a method analogous to delta joint position control in rigid manipulators, providing an intuitive and effective means of enacting control for soft robot learning. To highlight the benefits of implicit time-stepping and delta curvature control, we conduct extensive comparisons across four diverse soft manipulator tasks against one of the most widely used soft-body frameworks, Elastica. With implicit time-stepping, parallel stepping of 500 environments achieves up to 6x faster speeds for non-contact cases and up to 40x faster for contact-rich scenarios. Finally, a comprehensive sim-to-sim gap evaluation--training policies in one simulator and evaluating them in another--demonstrates that implicit time-stepping provides a rare free lunch: dramatic speedups achieved without sacrificing accuracy.
Learning Multi-Stage Pick-and-Place with a Legged Mobile Manipulator
Sep 04, 2025Quadruped-based mobile manipulation presents significant challenges in robotics due to the diversity of required skills, the extended task horizon, and partial observability. After presenting a multi-stage pick-and-place task as a succinct yet sufficiently rich setup that captures key desiderata for quadruped-based mobile manipulation, we propose an approach that can train a visuo-motor policy entirely in simulation, and achieve nearly 80\% success in the real world. The policy efficiently performs search, approach, grasp, transport, and drop into actions, with emerged behaviors such as re-grasping and task chaining. We conduct an extensive set of real-world experiments with ablation studies highlighting key techniques for efficient training and effective sim-to-real transfer. Additional experiments demonstrate deployment across a variety of indoor and outdoor environments. Demo videos and additional resources are available on the project page: https://horizonrobotics.github.io/gail/SLIM.
Integrating Deep Metric Learning with Coreset for Active Learning in 3D Segmentation
Nov 24, 2024



Deep learning has seen remarkable advancements in machine learning, yet it often demands extensive annotated data. Tasks like 3D semantic segmentation impose a substantial annotation burden, especially in domains like medicine, where expert annotations drive up the cost. Active learning (AL) holds great potential to alleviate this annotation burden in 3D medical segmentation. The majority of existing AL methods, however, are not tailored to the medical domain. While weakly-supervised methods have been explored to reduce annotation burden, the fusion of AL with weak supervision remains unexplored, despite its potential to significantly reduce annotation costs. Additionally, there is little focus on slice-based AL for 3D segmentation, which can also significantly reduce costs in comparison to conventional volume-based AL. This paper introduces a novel metric learning method for Coreset to perform slice-based active learning in 3D medical segmentation. By merging contrastive learning with inherent data groupings in medical imaging, we learn a metric that emphasizes the relevant differences in samples for training 3D medical segmentation models. We perform comprehensive evaluations using both weak and full annotations across four datasets (medical and non-medical). Our findings demonstrate that our approach surpasses existing active learning techniques on both weak and full annotations and obtains superior performance with low-annotation budgets which is crucial in medical imaging. Source code for this project is available in the supplementary materials and on GitHub: https://github.com/arvindmvepa/al-seg.
LatentExplainer: Explaining Latent Representations in Deep Generative Models with Multi-modal Foundation Models
Jun 24, 2024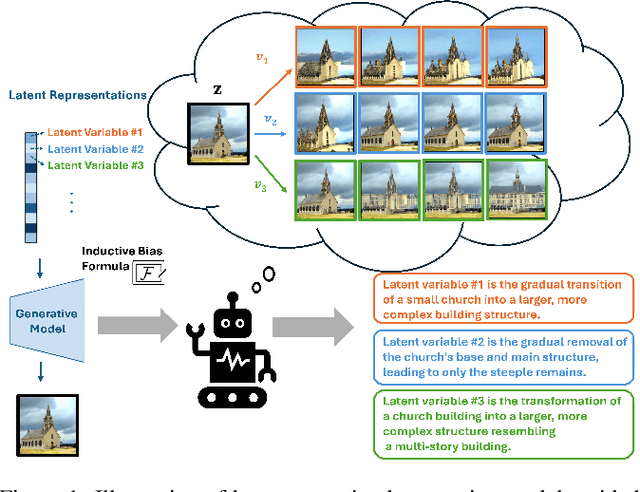



Deep generative models like VAEs and diffusion models have advanced various generation tasks by leveraging latent variables to learn data distributions and generate high-quality samples. Despite the field of explainable AI making strides in interpreting machine learning models, understanding latent variables in generative models remains challenging. This paper introduces LatentExplainer, a framework for automatically generating semantically meaningful explanations of latent variables in deep generative models. LatentExplainer tackles three main challenges: inferring the meaning of latent variables, aligning explanations with inductive biases, and handling varying degrees of explainability. By perturbing latent variables and interpreting changes in generated data, the framework provides a systematic approach to understanding and controlling the data generation process, enhancing the transparency and interpretability of deep generative models. We evaluate our proposed method on several real-world and synthetic datasets, and the results demonstrate superior performance in generating high-quality explanations of latent variables.
DisMech: A Discrete Differential Geometry-based Physical Simulator for Soft Robots and Structures
Nov 29, 2023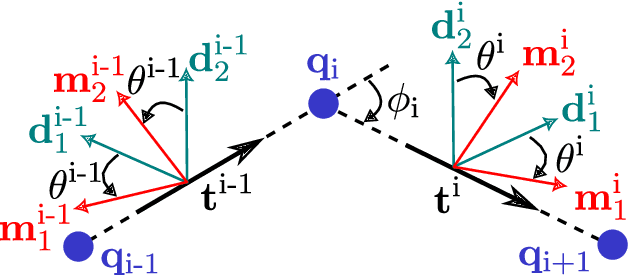

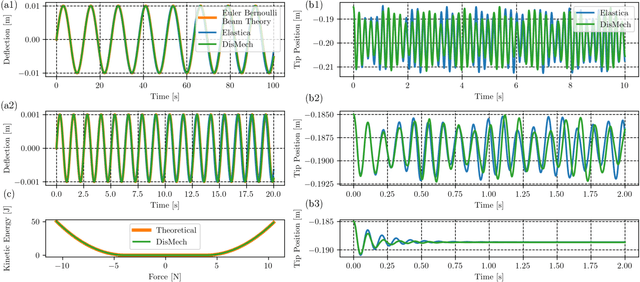
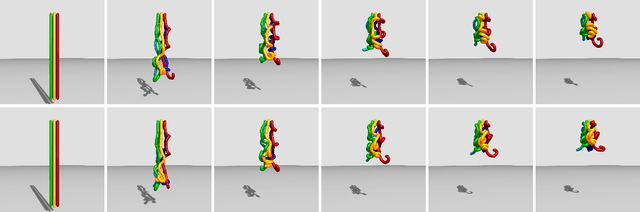
Fast, accurate, and generalizable simulations are a key enabler of modern advances in robot design and control. However, existing simulation frameworks in robotics either model rigid environments and mechanisms only, or if they include flexible or soft structures, suffer significantly in one or more of these performance areas. To close this "sim2real" gap, we introduce DisMech, a simulation environment that models highly dynamic motions of rod-like soft continuum robots and structures, quickly and accurately, with arbitrary connections between them. Our methodology combines a fully implicit discrete differential geometry-based physics solver with fast and accurate contact handling, all in an intuitive software interface. Crucially, we propose a gradient descent approach to easily map the motions of hardware robot prototypes to control inputs in DisMech. We validate DisMech through several highly-nuanced soft robot simulations while demonstrating an order of magnitude speed increase over previous state of the art. Our real2sim validation shows high physical accuracy versus hardware, even with complicated soft actuation mechanisms such as shape memory alloy wires. With its low computational cost, physical accuracy, and ease of use, DisMech can accelerate translation of sim-based control for both soft robotics and deformable object manipulation.
Sim2Real Physically Informed Neural Controllers for Robotic Deployment of Deformable Linear Objects
Mar 05, 2023Deformable linear objects, such as rods, cables, and ropes, play important roles in daily life. However, manipulation of DLOs is challenging as large geometrically nonlinear deformations may occur during the manipulation process. This problem is made even more difficult as the different deformation modes (e.g., stretching, bending, and twisting) may result in elastic instabilities during manipulation. In this paper, we formulate a physics-guided data-driven method to solve a challenging manipulation task -- accurately deploying a DLO (an elastic rod) onto a rigid substrate along various prescribed patterns. Our framework combines machine learning, scaling analysis, and physics-based simulations to develop a physically informed neural controller for deployment. We explore the complex interplay between the gravitational and elastic energies of the manipulated DLO and obtain a control method for DLO deployment that is robust against friction and material properties. Out of the numerous geometrical and material properties of the rod and substrate, we show that only three non-dimensional parameters are needed to describe the deployment process with physical analysis. Therefore, the essence of the controlling law for the manipulation task can be constructed with a low-dimensional model, drastically increasing the computation speed. The effectiveness of our optimal control scheme is shown through a comprehensive robotic case study comparing against a heuristic control method for deploying rods for a wide variety of patterns. In addition to this, we also showcase the practicality of our control scheme by having a robot accomplish challenging high-level tasks such as mimicking human handwriting and tying knots.
mBEST: Realtime Deformable Linear Object Detection Through Minimal Bending Energy Skeleton Pixel Traversals
Feb 18, 2023Robotic manipulation of deformable materials is a challenging task that often requires realtime visual feedback. This is especially true for deformable linear objects (DLOs) or "rods", whose slender and flexible structures make proper tracking and detection nontrivial. To address this challenge, we present mBEST, a robust algorithm for the realtime detection of DLOs that is capable of producing an ordered pixel sequence of each DLO's centerline along with segmentation masks. Our algorithm obtains a binary mask of the DLOs and then thins it to produce a skeleton pixel representation. After refining the skeleton to ensure topological correctness, the pixels are traversed to generate paths along each unique DLO. At the core of our algorithm, we postulate that intersections can be robustly handled by choosing the combination of paths that minimizes the cumulative bending energy of the DLO(s). We show that this simple and intuitive formulation outperforms the state-of-the-art methods for detecting DLOs with large numbers of sporadic crossings and curvatures with high variance. Furthermore, our method achieves a significant performance improvement of approximately 40 FPS compared to the 15 FPS of prior algorithms, which enables realtime applications.
Deep Learning of Force Manifolds from the Simulated Physics of Robotic Paper Folding
Jan 05, 2023



Robotic manipulation of slender objects is challenging, especially when the induced deformations are large and nonlinear. Traditionally, learning-based control approaches, e.g., imitation learning, have been used to tackle deformable material manipulation. Such approaches lack generality and often suffer critical failure from a simple switch of material, geometric, and/or environmental (e.g., friction) properties. In this article, we address a fundamental but difficult step of robotic origami: forming a predefined fold in paper with only a single manipulator. A data-driven framework combining physically-accurate simulation and machine learning is used to train deep neural network models capable of predicting the external forces induced on the paper given a grasp position. We frame the problem using scaling analysis, resulting in a control framework robust against material and geometric changes. Path planning is carried out over the generated manifold to produce robot manipulation trajectories optimized to prevent sliding. Furthermore, the inference speed of the trained model enables the incorporation of real-time visual feedback to achieve closed-loop sensorimotor control. Real-world experiments demonstrate that our framework can greatly improve robotic manipulation performance compared against natural paper folding strategies, even when manipulating paper objects of various materials and shapes.
Preemptive Motion Planning for Human-to-Robot Indirect Placement Handovers
Mar 01, 2022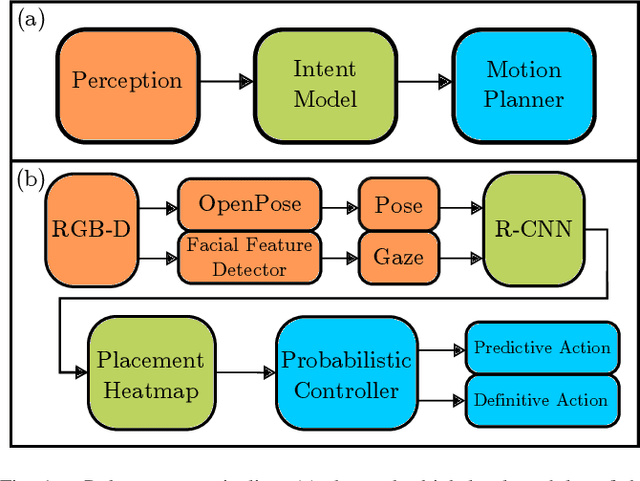
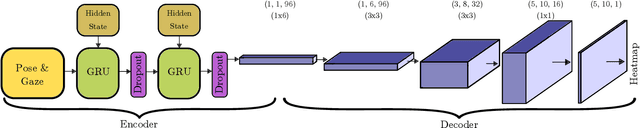
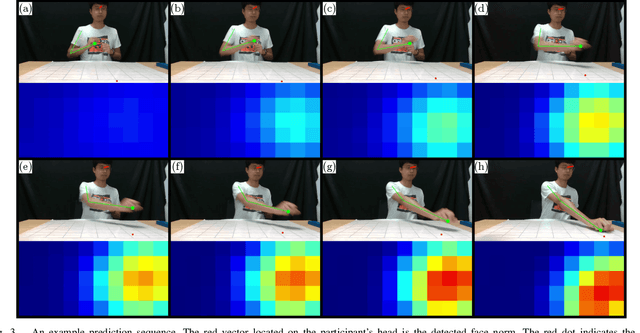

As technology advances, the need for safe, efficient, and collaborative human-robot-teams has become increasingly important. One of the most fundamental collaborative tasks in any setting is the object handover. Human-to-robot handovers can take either of two approaches: (1) direct hand-to-hand or (2) indirect hand-to-placement-to-pick-up. The latter approach ensures minimal contact between the human and robot but can also result in increased idle time due to having to wait for the object to first be placed down on a surface. To minimize such idle time, the robot must preemptively predict the human intent of where the object will be placed. Furthermore, for the robot to preemptively act in any sort of productive manner, predictions and motion planning must occur in real-time. We introduce a novel prediction-planning pipeline that allows the robot to preemptively move towards the human agent's intended placement location using gaze and gestures as model inputs. In this paper, we investigate the performance and drawbacks of our early intent predictor-planner as well as the practical benefits of using such a pipeline through a human-robot case study.