 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWonderland: Navigating 3D Scenes from a Single Image
Dec 16, 2024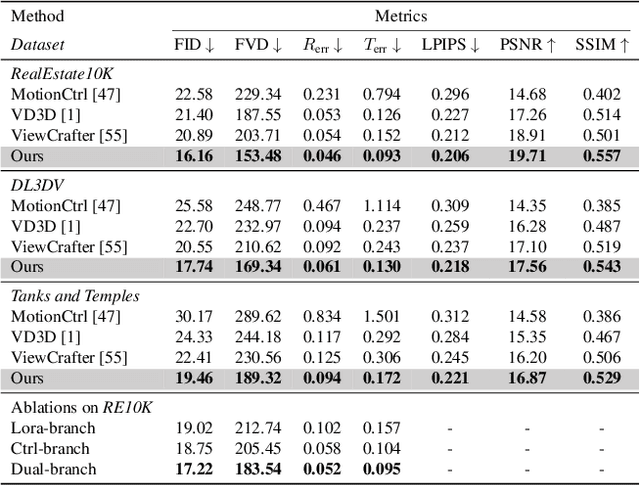
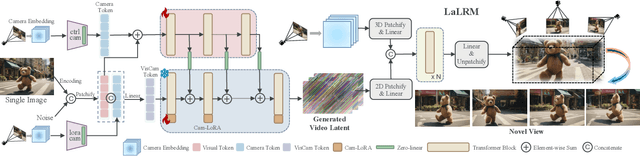
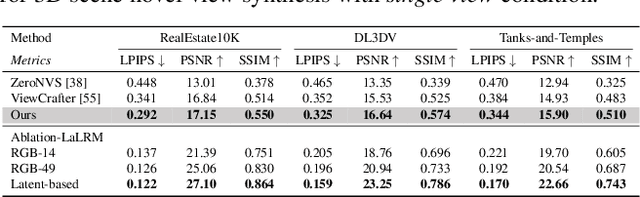

This paper addresses a challenging question: How can we efficiently create high-quality, wide-scope 3D scenes from a single arbitrary image? Existing methods face several constraints, such as requiring multi-view data, time-consuming per-scene optimization, low visual quality in backgrounds, and distorted reconstructions in unseen areas. We propose a novel pipeline to overcome these limitations. Specifically, we introduce a large-scale reconstruction model that uses latents from a video diffusion model to predict 3D Gaussian Splattings for the scenes in a feed-forward manner. The video diffusion model is designed to create videos precisely following specified camera trajectories, allowing it to generate compressed video latents that contain multi-view information while maintaining 3D consistency. We train the 3D reconstruction model to operate on the video latent space with a progressive training strategy, enabling the efficient generation of high-quality, wide-scope, and generic 3D scenes. Extensive evaluations across various datasets demonstrate that our model significantly outperforms existing methods for single-view 3D scene generation, particularly with out-of-domain images. For the first time, we demonstrate that a 3D reconstruction model can be effectively built upon the latent space of a diffusion model to realize efficient 3D scene generation.
TeamCraft: A Benchmark for Multi-Modal Multi-Agent Systems in Minecraft
Dec 06, 2024



Collaboration is a cornerstone of society. In the real world, human teammates make use of multi-sensory data to tackle challenging tasks in ever-changing environments. It is essential for embodied agents collaborating in visually-rich environments replete with dynamic interactions to understand multi-modal observations and task specifications. To evaluate the performance of generalizable multi-modal collaborative agents, we present TeamCraft, a multi-modal multi-agent benchmark built on top of the open-world video game Minecraft. The benchmark features 55,000 task variants specified by multi-modal prompts, procedurally-generated expert demonstrations for imitation learning, and carefully designed protocols to evaluate model generalization capabilities. We also perform extensive analyses to better understand the limitations and strengths of existing approaches. Our results indicate that existing models continue to face significant challenges in generalizing to novel goals, scenes, and unseen numbers of agents. These findings underscore the need for further research in this area. The TeamCraft platform and dataset are publicly available at https://github.com/teamcraft-bench/teamcraft.
Inverse Attention Agent for Multi-Agent System
Oct 29, 2024
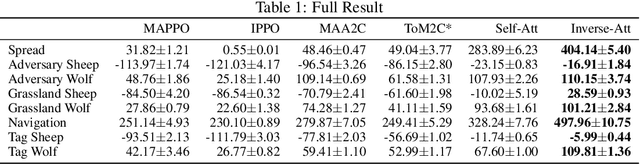

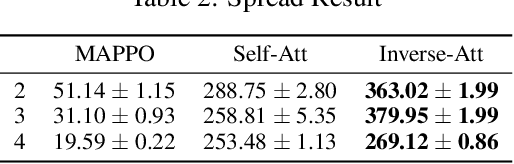
A major challenge for Multi-Agent Systems is enabling agents to adapt dynamically to diverse environments in which opponents and teammates may continually change. Agents trained using conventional methods tend to excel only within the confines of their training cohorts; their performance drops significantly when confronting unfamiliar agents. To address this shortcoming, we introduce Inverse Attention Agents that adopt concepts from the Theory of Mind, implemented algorithmically using an attention mechanism and trained in an end-to-end manner. Crucial to determining the final actions of these agents, the weights in their attention model explicitly represent attention to different goals. We furthermore propose an inverse attention network that deduces the ToM of agents based on observations and prior actions. The network infers the attentional states of other agents, thereby refining the attention weights to adjust the agent's final action. We conduct experiments in a continuous environment, tackling demanding tasks encompassing cooperation, competition, and a blend of both. They demonstrate that the inverse attention network successfully infers the attention of other agents, and that this information improves agent performance. Additional human experiments show that, compared to baseline agent models, our inverse attention agents exhibit superior cooperation with humans and better emulate human behaviors.
Prompting Medical Large Vision-Language Models to Diagnose Pathologies by Visual Question Answering
Jul 31, 2024Large Vision-Language Models (LVLMs) have achieved significant success in recent years, and they have been extended to the medical domain. Although demonstrating satisfactory performance on medical Visual Question Answering (VQA) tasks, Medical LVLMs (MLVLMs) suffer from the hallucination problem, which makes them fail to diagnose complex pathologies. Moreover, they readily fail to learn minority pathologies due to imbalanced training data. We propose two prompting strategies for MLVLMs that reduce hallucination and improve VQA performance. In the first strategy, we provide a detailed explanation of the queried pathology. In the second strategy, we fine-tune a cheap, weak learner to achieve high performance on a specific metric, and textually provide its judgment to the MLVLM. Tested on the MIMIC-CXR-JPG and Chexpert datasets, our methods significantly improve the diagnostic F1 score, with the highest increase being 0.27. We also demonstrate that our prompting strategies can be extended to general LVLM domains. Based on POPE metrics, it effectively suppresses the false negative predictions of existing LVLMs and improves Recall by approximately 0.07.
Cross-Slice Attention and Evidential Critical Loss for Uncertainty-Aware Prostate Cancer Detection
Jul 01, 2024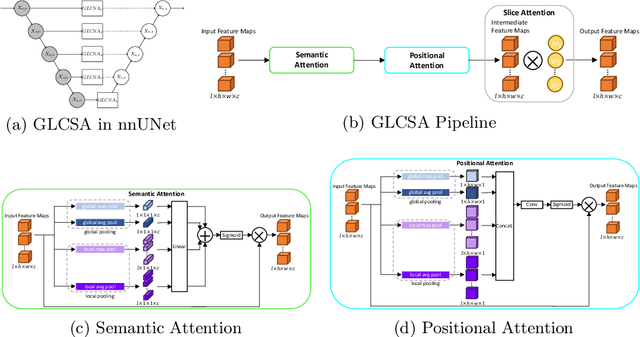

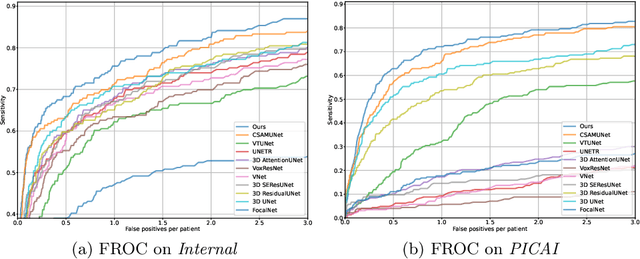

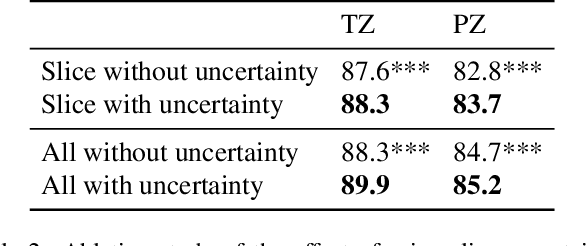
Current deep learning-based models typically analyze medical images in either 2D or 3D albeit disregarding volumetric information or suffering sub-optimal performance due to the anisotropic resolution of MR data. Furthermore, providing an accurate uncertainty estimation is beneficial to clinicians, as it indicates how confident a model is about its prediction. We propose a novel 2.5D cross-slice attention model that utilizes both global and local information, along with an evidential critical loss, to perform evidential deep learning for the detection in MR images of prostate cancer, one of the most common cancers and a leading cause of cancer-related death in men. We perform extensive experiments with our model on two different datasets and achieve state-of-the-art performance in prostate cancer detection along with improved epistemic uncertainty estimation. The implementation of the model is available at https://github.com/aL3x-O-o-Hung/GLCSA_ECLoss.
Position Paper: Agent AI Towards a Holistic Intelligence
Feb 28, 2024Recent advancements in large foundation models have remarkably enhanced our understanding of sensory information in open-world environments. In leveraging the power of foundation models, it is crucial for AI research to pivot away from excessive reductionism and toward an emphasis on systems that function as cohesive wholes. Specifically, we emphasize developing Agent AI -- an embodied system that integrates large foundation models into agent actions. The emerging field of Agent AI spans a wide range of existing embodied and agent-based multimodal interactions, including robotics, gaming, and healthcare systems, etc. In this paper, we propose a novel large action model to achieve embodied intelligent behavior, the Agent Foundation Model. On top of this idea, we discuss how agent AI exhibits remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Furthermore, we discuss the potential of Agent AI from an interdisciplinary perspective, underscoring AI cognition and consciousness within scientific discourse. We believe that those discussions serve as a basis for future research directions and encourage broader societal engagement.
An Interactive Agent Foundation Model
Feb 08, 2024



The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.
Agent AI: Surveying the Horizons of Multimodal Interaction
Jan 07, 2024



Multi-modal AI systems will likely become a ubiquitous presence in our everyday lives. A promising approach to making these systems more interactive is to embody them as agents within physical and virtual environments. At present, systems leverage existing foundation models as the basic building blocks for the creation of embodied agents. Embedding agents within such environments facilitates the ability of models to process and interpret visual and contextual data, which is critical for the creation of more sophisticated and context-aware AI systems. For example, a system that can perceive user actions, human behavior, environmental objects, audio expressions, and the collective sentiment of a scene can be used to inform and direct agent responses within the given environment. To accelerate research on agent-based multimodal intelligence, we define "Agent AI" as a class of interactive systems that can perceive visual stimuli, language inputs, and other environmentally-grounded data, and can produce meaningful embodied action with infinite agent. In particular, we explore systems that aim to improve agents based on next-embodied action prediction by incorporating external knowledge, multi-sensory inputs, and human feedback. We argue that by developing agentic AI systems in grounded environments, one can also mitigate the hallucinations of large foundation models and their tendency to generate environmentally incorrect outputs. The emerging field of Agent AI subsumes the broader embodied and agentic aspects of multimodal interactions. Beyond agents acting and interacting in the physical world, we envision a future where people can easily create any virtual reality or simulated scene and interact with agents embodied within the virtual environment.
Aligner: One Global Token is Worth Millions of Parameters When Aligning Large Language Models
Dec 09, 2023We introduce Aligner, a novel Parameter-Efficient Fine-Tuning (PEFT) method for aligning multi-billion-parameter-sized Large Language Models (LLMs). Aligner employs a unique design that constructs a globally shared set of tunable tokens that modify the attention of every layer. Remarkably with this method, even when using one token accounting for a mere 5,000 parameters, Aligner can still perform comparably well to state-of-the-art LLM adaptation methods like LoRA that require millions of parameters. This capacity is substantiated in both instruction following and value alignment tasks. Besides the multiple order-of-magnitude improvement in parameter efficiency, the insight Aligner provides into the internal mechanisms of LLMs is also valuable. The architectural features and efficacy of our method, in addition to our experiments demonstrate that an LLM separates its internal handling of "form" and "knowledge" in a somewhat orthogonal manner. This finding promises to motivate new research into LLM mechanism understanding and value alignment.
CSAM: A 2.5D Cross-Slice Attention Module for Anisotropic Volumetric Medical Image Segmentation
Nov 08, 2023
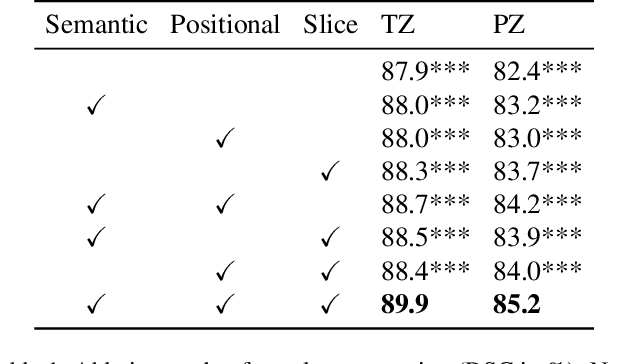
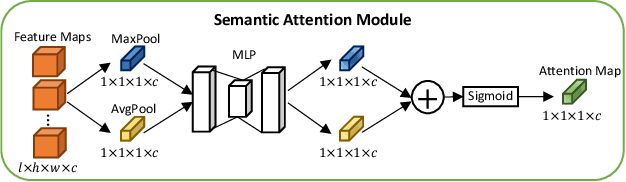
A large portion of volumetric medical data, especially magnetic resonance imaging (MRI) data, is anisotropic, as the through-plane resolution is typically much lower than the in-plane resolution. Both 3D and purely 2D deep learning-based segmentation methods are deficient in dealing with such volumetric data since the performance of 3D methods suffers when confronting anisotropic data, and 2D methods disregard crucial volumetric information. Insufficient work has been done on 2.5D methods, in which 2D convolution is mainly used in concert with volumetric information. These models focus on learning the relationship across slices, but typically have many parameters to train. We offer a Cross-Slice Attention Module (CSAM) with minimal trainable parameters, which captures information across all the slices in the volume by applying semantic, positional, and slice attention on deep feature maps at different scales. Our extensive experiments using different network architectures and tasks demonstrate the usefulness and generalizability of CSAM. Associated code is available at https://github.com/aL3x-O-o-Hung/CSAM.