 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertGen: Scalable Sim-to-Real Expert Policy Learning from Imperfect Behavior Priors
Mar 16, 2026Learning generalizable and robust behavior cloning policies requires large volumes of high-quality robotics data. While human demonstrations (e.g., through teleoperation) serve as the standard source for expert behaviors, acquiring such data at scale in the real world is prohibitively expensive. This paper introduces ExpertGen, a framework that automates expert policy learning in simulation to enable scalable sim-to-real transfer. ExpertGen first initializes a behavior prior using a diffusion policy trained on imperfect demonstrations, which may be synthesized by large language models or provided by humans. Reinforcement learning is then used to steer this prior toward high task success by optimizing the diffusion model's initial noise while keep original policy frozen. By keeping the pretrained diffusion policy frozen, ExpertGen regularizes exploration to remain within safe, human-like behavior manifolds, while also enabling effective learning with only sparse rewards. Empirical evaluations on challenging manipulation benchmarks demonstrate that ExpertGen reliably produces high-quality expert policies with no reward engineering. On industrial assembly tasks, ExpertGen achieves a 90.5% overall success rate, while on long-horizon manipulation tasks it attains 85% overall success, outperforming all baseline methods. The resulting policies exhibit dexterous control and remain robust across diverse initial configurations and failure states. To validate sim-to-real transfer, the learned state-based expert policies are further distilled into visuomotor policies via DAgger and successfully deployed on real robotic hardware.
SurfelSoup: Learned Point Cloud Geometry Compression With a Probablistic SurfelTree Representation
Jan 30, 2026This paper presents SurfelSoup, an end-to-end learned surface-based framework for point cloud geometry compression, with surface-structured primitives for representation. It proposes a probabilistic surface representation, pSurfel, which models local point occupancies using a bounded generalized Gaussian distribution. In addition, the pSurfels are organized into an octree-like hierarchy, pSurfelTree, with a Tree Decision module that adaptively terminates the tree subdivision for rate-distortion optimal Surfel granularity selection. This formulation avoids redundant point-wise compression in smooth regions and produces compact yet smooth surface reconstructions. Experimental results under the MPEG common test condition show consistent gain on geometry compression over voxel-based baselines and MPEG standard G-PCC-GesTM-TriSoup, while providing visually superior reconstructions with smooth and coherent surface structures.
AnyTask: an Automated Task and Data Generation Framework for Advancing Sim-to-Real Policy Learning
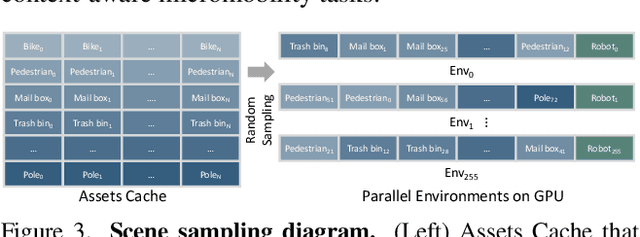
Dec 19, 2025Generalist robot learning remains constrained by data: large-scale, diverse, and high-quality interaction data are expensive to collect in the real world. While simulation has become a promising way for scaling up data collection, the related tasks, including simulation task design, task-aware scene generation, expert demonstration synthesis, and sim-to-real transfer, still demand substantial human effort. We present AnyTask, an automated framework that pairs massively parallel GPU simulation with foundation models to design diverse manipulation tasks and synthesize robot data. We introduce three AnyTask agents for generating expert demonstrations aiming to solve as many tasks as possible: 1) ViPR, a novel task and motion planning agent with VLM-in-the-loop Parallel Refinement; 2) ViPR-Eureka, a reinforcement learning agent with generated dense rewards and LLM-guided contact sampling; 3) ViPR-RL, a hybrid planning and learning approach that jointly produces high-quality demonstrations with only sparse rewards. We train behavior cloning policies on generated data, validate them in simulation, and deploy them directly on real robot hardware. The policies generalize to novel object poses, achieving 44% average success across a suite of real-world pick-and-place, drawer opening, contact-rich pushing, and long-horizon manipulation tasks. Our project website is at https://anytask.rai-inst.com .
Sceniris: A Fast Procedural Scene Generation Framework
Dec 18, 2025Synthetic 3D scenes are essential for developing Physical AI and generative models. Existing procedural generation methods often have low output throughput, creating a significant bottleneck in scaling up dataset creation. In this work, we introduce Sceniris, a highly efficient procedural scene generation framework for rapidly generating large-scale, collision-free scene variations. Sceniris also provides an optional robot reachability check, providing manipulation-feasible scenes for robot tasks. Sceniris is designed for maximum efficiency by addressing the primary performance limitations of the prior method, Scene Synthesizer. Leveraging batch sampling and faster collision checking in cuRobo, Sceniris achieves at least 234x speed-up over Scene Synthesizer. Sceniris also expands the object-wise spatial relationships available in prior work to support diverse scene requirements. Our code is available at https://github.com/rai-inst/sceniris
TeSO: Representing and Compressing 3D Point Cloud Scenes with Textured Surfel Octree
Aug 09, 20253D visual content streaming is a key technology for emerging 3D telepresence and AR/VR applications. One fundamental element underlying the technology is a versatile 3D representation that is capable of producing high-quality renders and can be efficiently compressed at the same time. Existing 3D representations like point clouds, meshes and 3D Gaussians each have limitations in terms of rendering quality, surface definition, and compressibility. In this paper, we present the Textured Surfel Octree (TeSO), a novel 3D representation that is built from point clouds but addresses the aforementioned limitations. It represents a 3D scene as cube-bounded surfels organized on an octree, where each surfel is further associated with a texture patch. By approximating a smooth surface with a large surfel at a coarser level of the octree, it reduces the number of primitives required to represent the 3D scene, and yet retains the high-frequency texture details through the texture map attached to each surfel. We further propose a compression scheme to encode the geometry and texture efficiently, leveraging the octree structure. The proposed textured surfel octree combined with the compression scheme achieves higher rendering quality at lower bit-rates compared to multiple point cloud and 3D Gaussian-based baselines.
Towards Autonomous Micromobility through Scalable Urban Simulation
May 01, 2025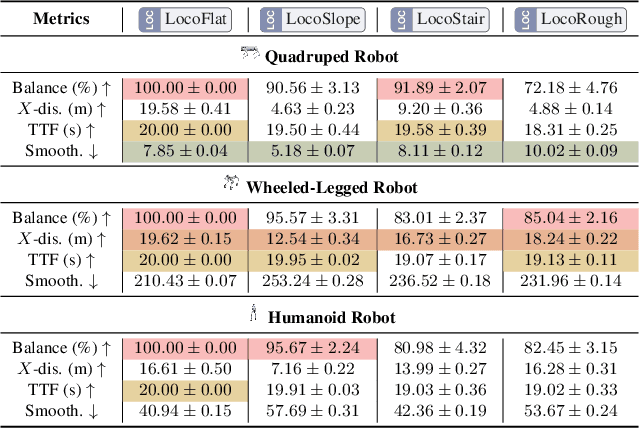

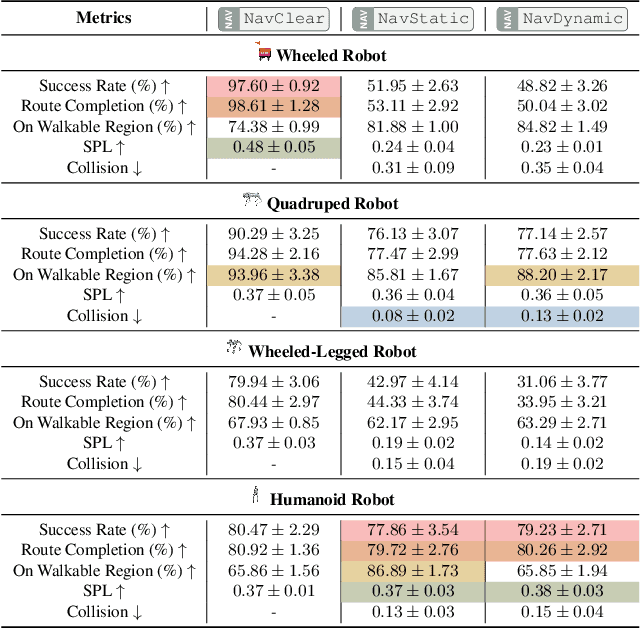
Micromobility, which utilizes lightweight mobile machines moving in urban public spaces, such as delivery robots and mobility scooters, emerges as a promising alternative to vehicular mobility. Current micromobility depends mostly on human manual operation (in-person or remote control), which raises safety and efficiency concerns when navigating busy urban environments full of unpredictable obstacles and pedestrians. Assisting humans with AI agents in maneuvering micromobility devices presents a viable solution for enhancing safety and efficiency. In this work, we present a scalable urban simulation solution to advance autonomous micromobility. First, we build URBAN-SIM - a high-performance robot learning platform for large-scale training of embodied agents in interactive urban scenes. URBAN-SIM contains three critical modules: Hierarchical Urban Generation pipeline, Interactive Dynamics Generation strategy, and Asynchronous Scene Sampling scheme, to improve the diversity, realism, and efficiency of robot learning in simulation. Then, we propose URBAN-BENCH - a suite of essential tasks and benchmarks to gauge various capabilities of the AI agents in achieving autonomous micromobility. URBAN-BENCH includes eight tasks based on three core skills of the agents: Urban Locomotion, Urban Navigation, and Urban Traverse. We evaluate four robots with heterogeneous embodiments, such as the wheeled and legged robots, across these tasks. Experiments on diverse terrains and urban structures reveal each robot's strengths and limitations.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025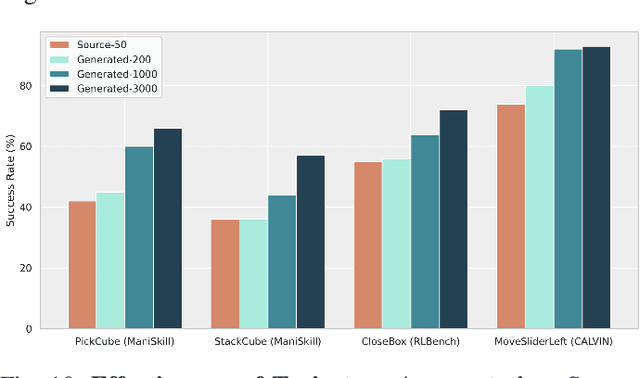



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
TeamCraft: A Benchmark for Multi-Modal Multi-Agent Systems in Minecraft
Dec 06, 2024



Collaboration is a cornerstone of society. In the real world, human teammates make use of multi-sensory data to tackle challenging tasks in ever-changing environments. It is essential for embodied agents collaborating in visually-rich environments replete with dynamic interactions to understand multi-modal observations and task specifications. To evaluate the performance of generalizable multi-modal collaborative agents, we present TeamCraft, a multi-modal multi-agent benchmark built on top of the open-world video game Minecraft. The benchmark features 55,000 task variants specified by multi-modal prompts, procedurally-generated expert demonstrations for imitation learning, and carefully designed protocols to evaluate model generalization capabilities. We also perform extensive analyses to better understand the limitations and strengths of existing approaches. Our results indicate that existing models continue to face significant challenges in generalizing to novel goals, scenes, and unseen numbers of agents. These findings underscore the need for further research in this area. The TeamCraft platform and dataset are publicly available at https://github.com/teamcraft-bench/teamcraft.
Low Latency Point Cloud Rendering with Learned Splatting
Sep 24, 2024
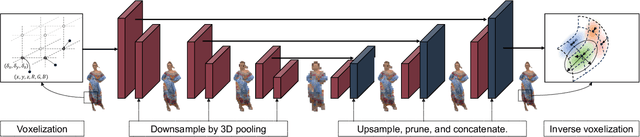

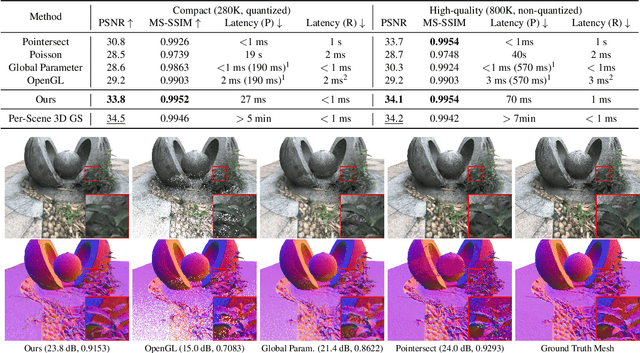
Point cloud is a critical 3D representation with many emerging applications. Because of the point sparsity and irregularity, high-quality rendering of point clouds is challenging and often requires complex computations to recover the continuous surface representation. On the other hand, to avoid visual discomfort, the motion-to-photon latency has to be very short, under 10 ms. Existing rendering solutions lack in either quality or speed. To tackle these challenges, we present a framework that unlocks interactive, free-viewing and high-fidelity point cloud rendering. We train a generic neural network to estimate 3D elliptical Gaussians from arbitrary point clouds and use differentiable surface splatting to render smooth texture and surface normal for arbitrary views. Our approach does not require per-scene optimization, and enable real-time rendering of dynamic point cloud. Experimental results demonstrate the proposed solution enjoys superior visual quality and speed, as well as generalizability to different scene content and robustness to compression artifacts. The code is available at https://github.com/huzi96/gaussian-pcloud-render .
Bits-to-Photon: End-to-End Learned Scalable Point Cloud Compression for Direct Rendering
Jun 09, 2024



Point cloud is a promising 3D representation for volumetric streaming in emerging AR/VR applications. Despite recent advances in point cloud compression, decoding and rendering high-quality images from lossy compressed point clouds is still challenging in terms of quality and complexity, making it a major roadblock to achieve real-time 6-Degree-of-Freedom video streaming. In this paper, we address this problem by developing a point cloud compression scheme that generates a bit stream that can be directly decoded to renderable 3D Gaussians. The encoder and decoder are jointly optimized to consider both bit-rates and rendering quality. It significantly improves the rendering quality while substantially reducing decoding and rendering time, compared to existing point cloud compression methods. Furthermore, the proposed scheme generates a scalable bit stream, allowing multiple levels of details at different bit-rate ranges. Our method supports real-time color decoding and rendering of high quality point clouds, thus paving the way for interactive 3D streaming applications with free view points.