 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantV2X: A Fully Quantized Multi-Agent System for Cooperative Perception
Sep 03, 2025Cooperative perception through Vehicle-to-Everything (V2X) communication offers significant potential for enhancing vehicle perception by mitigating occlusions and expanding the field of view. However, past research has predominantly focused on improving accuracy metrics without addressing the crucial system-level considerations of efficiency, latency, and real-world deployability. Noticeably, most existing systems rely on full-precision models, which incur high computational and transmission costs, making them impractical for real-time operation in resource-constrained environments. In this paper, we introduce \textbf{QuantV2X}, the first fully quantized multi-agent system designed specifically for efficient and scalable deployment of multi-modal, multi-agent V2X cooperative perception. QuantV2X introduces a unified end-to-end quantization strategy across both neural network models and transmitted message representations that simultaneously reduces computational load and transmission bandwidth. Remarkably, despite operating under low-bit constraints, QuantV2X achieves accuracy comparable to full-precision systems. More importantly, when evaluated under deployment-oriented metrics, QuantV2X reduces system-level latency by 3.2$\times$ and achieves a +9.5 improvement in mAP30 over full-precision baselines. Furthermore, QuantV2X scales more effectively, enabling larger and more capable models to fit within strict memory budgets. These results highlight the viability of a fully quantized multi-agent intermediate fusion system for real-world deployment. The system will be publicly released to promote research in this field: https://github.com/ucla-mobility/QuantV2X.
TurboTrain: Towards Efficient and Balanced Multi-Task Learning for Multi-Agent Perception and Prediction
Aug 06, 2025End-to-end training of multi-agent systems offers significant advantages in improving multi-task performance. However, training such models remains challenging and requires extensive manual design and monitoring. In this work, we introduce TurboTrain, a novel and efficient training framework for multi-agent perception and prediction. TurboTrain comprises two key components: a multi-agent spatiotemporal pretraining scheme based on masked reconstruction learning and a balanced multi-task learning strategy based on gradient conflict suppression. By streamlining the training process, our framework eliminates the need for manually designing and tuning complex multi-stage training pipelines, substantially reducing training time and improving performance. We evaluate TurboTrain on a real-world cooperative driving dataset, V2XPnP-Seq, and demonstrate that it further improves the performance of state-of-the-art multi-agent perception and prediction models. Our results highlight that pretraining effectively captures spatiotemporal multi-agent features and significantly benefits downstream tasks. Moreover, the proposed balanced multi-task learning strategy enhances detection and prediction.
AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning
Jun 16, 2025Recent advancements in Vision-Language-Action (VLA) models have shown promise for end-to-end autonomous driving by leveraging world knowledge and reasoning capabilities. However, current VLA models often struggle with physically infeasible action outputs, complex model structures, or unnecessarily long reasoning. In this paper, we propose AutoVLA, a novel VLA model that unifies reasoning and action generation within a single autoregressive generation model for end-to-end autonomous driving. AutoVLA performs semantic reasoning and trajectory planning directly from raw visual inputs and language instructions. We tokenize continuous trajectories into discrete, feasible actions, enabling direct integration into the language model. For training, we employ supervised fine-tuning to equip the model with dual thinking modes: fast thinking (trajectory-only) and slow thinking (enhanced with chain-of-thought reasoning). To further enhance planning performance and efficiency, we introduce a reinforcement fine-tuning method based on Group Relative Policy Optimization (GRPO), reducing unnecessary reasoning in straightforward scenarios. Extensive experiments across real-world and simulated datasets and benchmarks, including nuPlan, nuScenes, Waymo, and CARLA, demonstrate the competitive performance of AutoVLA in both open-loop and closed-loop settings. Qualitative results showcase the adaptive reasoning and accurate planning capabilities of AutoVLA in diverse scenarios.
Towards Autonomous Micromobility through Scalable Urban Simulation
May 01, 2025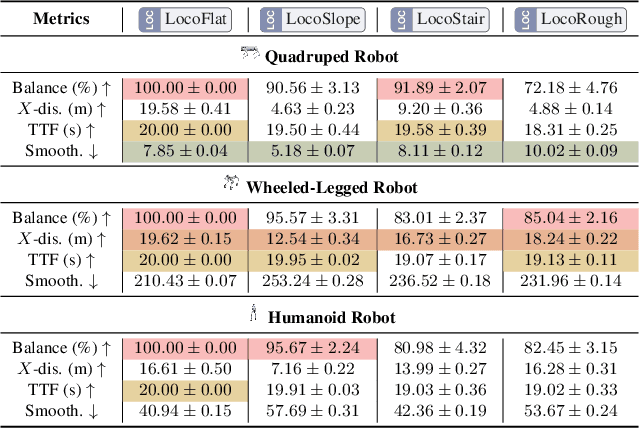

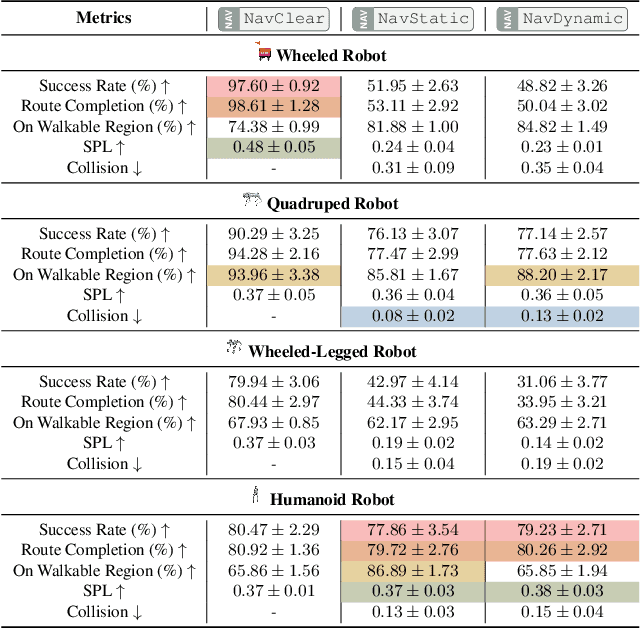
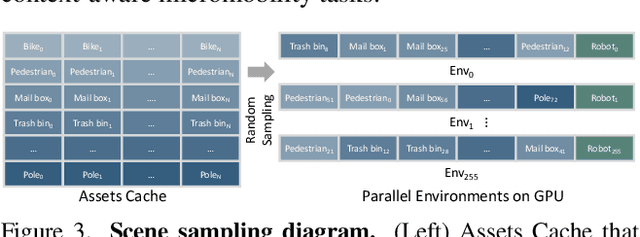
Micromobility, which utilizes lightweight mobile machines moving in urban public spaces, such as delivery robots and mobility scooters, emerges as a promising alternative to vehicular mobility. Current micromobility depends mostly on human manual operation (in-person or remote control), which raises safety and efficiency concerns when navigating busy urban environments full of unpredictable obstacles and pedestrians. Assisting humans with AI agents in maneuvering micromobility devices presents a viable solution for enhancing safety and efficiency. In this work, we present a scalable urban simulation solution to advance autonomous micromobility. First, we build URBAN-SIM - a high-performance robot learning platform for large-scale training of embodied agents in interactive urban scenes. URBAN-SIM contains three critical modules: Hierarchical Urban Generation pipeline, Interactive Dynamics Generation strategy, and Asynchronous Scene Sampling scheme, to improve the diversity, realism, and efficiency of robot learning in simulation. Then, we propose URBAN-BENCH - a suite of essential tasks and benchmarks to gauge various capabilities of the AI agents in achieving autonomous micromobility. URBAN-BENCH includes eight tasks based on three core skills of the agents: Urban Locomotion, Urban Navigation, and Urban Traverse. We evaluate four robots with heterogeneous embodiments, such as the wheeled and legged robots, across these tasks. Experiments on diverse terrains and urban structures reveal each robot's strengths and limitations.
Pose-Aware Weakly-Supervised Action Segmentation
Apr 08, 2025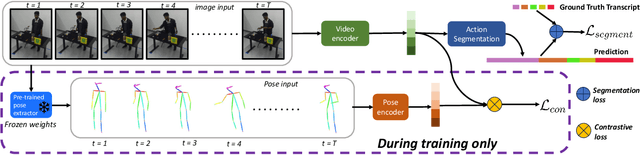
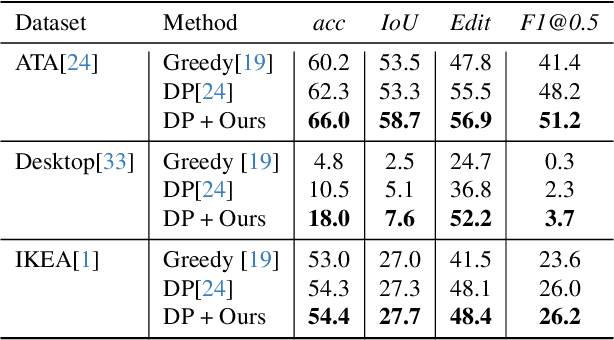
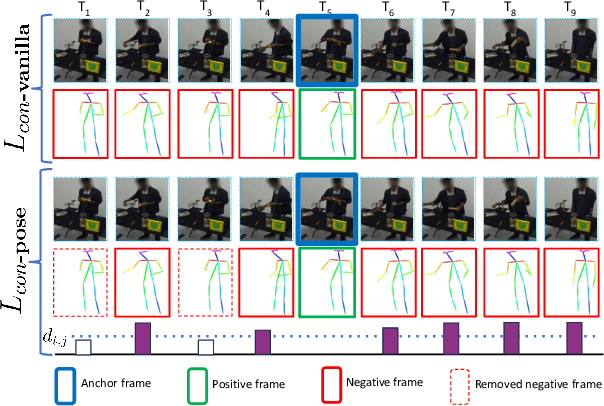
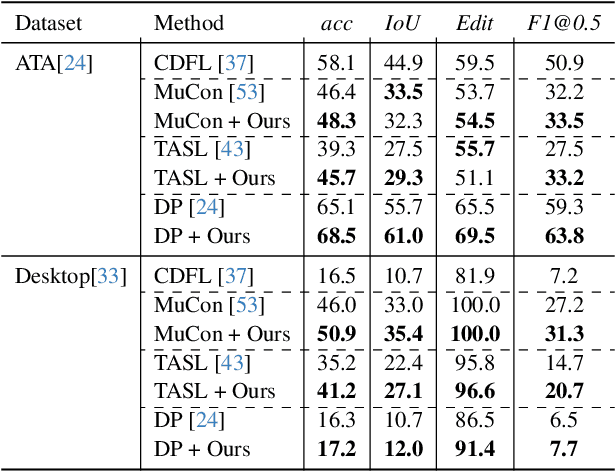
Understanding human behavior is an important problem in the pursuit of visual intelligence. A challenge in this endeavor is the extensive and costly effort required to accurately label action segments. To address this issue, we consider learning methods that demand minimal supervision for segmentation of human actions in long instructional videos. Specifically, we introduce a weakly-supervised framework that uniquely incorporates pose knowledge during training while omitting its use during inference, thereby distilling pose knowledge pertinent to each action component. We propose a pose-inspired contrastive loss as a part of the whole weakly-supervised framework which is trained to distinguish action boundaries more effectively. Our approach, validated through extensive experiments on representative datasets, outperforms previous state-of-the-art (SOTA) in segmenting long instructional videos under both online and offline settings. Additionally, we demonstrate the framework's adaptability to various segmentation backbones and pose extractors across different datasets.
V2X-ReaLO: An Open Online Framework and Dataset for Cooperative Perception in Reality
Mar 13, 2025Cooperative perception enabled by Vehicle-to-Everything (V2X) communication holds significant promise for enhancing the perception capabilities of autonomous vehicles, allowing them to overcome occlusions and extend their field of view. However, existing research predominantly relies on simulated environments or static datasets, leaving the feasibility and effectiveness of V2X cooperative perception especially for intermediate fusion in real-world scenarios largely unexplored. In this work, we introduce V2X-ReaLO, an open online cooperative perception framework deployed on real vehicles and smart infrastructure that integrates early, late, and intermediate fusion methods within a unified pipeline and provides the first practical demonstration of online intermediate fusion's feasibility and performance under genuine real-world conditions. Additionally, we present an open benchmark dataset specifically designed to assess the performance of online cooperative perception systems. This new dataset extends V2X-Real dataset to dynamic, synchronized ROS bags and provides 25,028 test frames with 6,850 annotated key frames in challenging urban scenarios. By enabling real-time assessments of perception accuracy and communication lantency under dynamic conditions, V2X-ReaLO sets a new benchmark for advancing and optimizing cooperative perception systems in real-world applications. The codes and datasets will be released to further advance the field.
V2XPnP: Vehicle-to-Everything Spatio-Temporal Fusion for Multi-Agent Perception and Prediction
Dec 02, 2024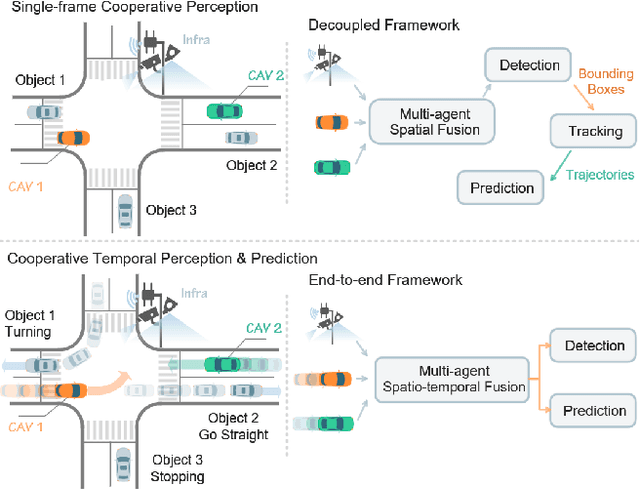
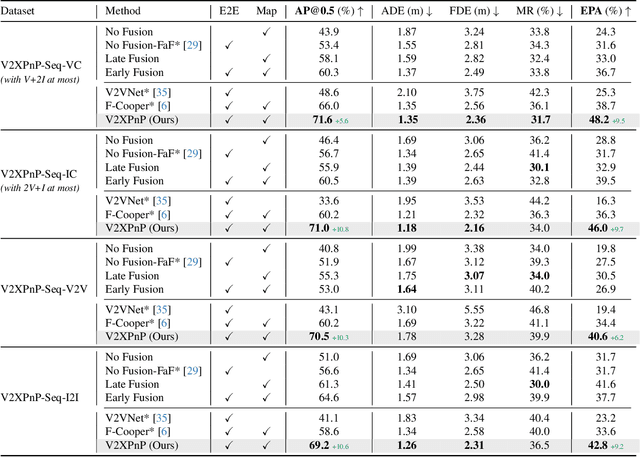
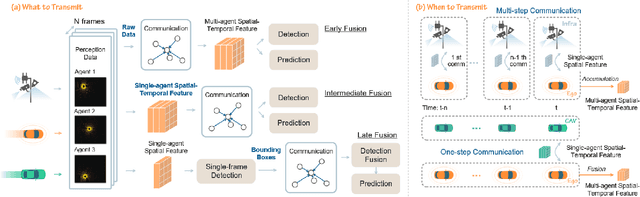
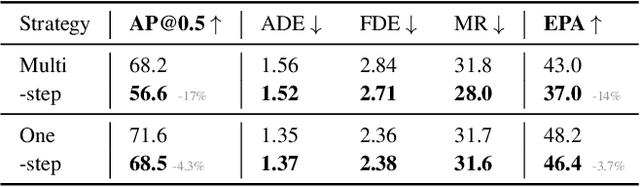
Vehicle-to-everything (V2X) technologies offer a promising paradigm to mitigate the limitations of constrained observability in single-vehicle systems. Prior work primarily focuses on single-frame cooperative perception, which fuses agents' information across different spatial locations but ignores temporal cues and temporal tasks (e.g., temporal perception and prediction). In this paper, we focus on temporal perception and prediction tasks in V2X scenarios and design one-step and multi-step communication strategies (when to transmit) as well as examine their integration with three fusion strategies - early, late, and intermediate (what to transmit), providing comprehensive benchmarks with various fusion models (how to fuse). Furthermore, we propose V2XPnP, a novel intermediate fusion framework within one-step communication for end-to-end perception and prediction. Our framework employs a unified Transformer-based architecture to effectively model complex spatiotemporal relationships across temporal per-frame, spatial per-agent, and high-definition map. Moreover, we introduce the V2XPnP Sequential Dataset that supports all V2X cooperation modes and addresses the limitations of existing real-world datasets, which are restricted to single-frame or single-mode cooperation. Extensive experiments demonstrate our framework outperforms state-of-the-art methods in both perception and prediction tasks.
Driving with Regulation: Interpretable Decision-Making for Autonomous Vehicles with Retrieval-Augmented Reasoning via LLM
Oct 07, 2024



This work presents an interpretable decision-making framework for autonomous vehicles that integrates traffic regulations, norms, and safety guidelines comprehensively and enables seamless adaptation to different regions. While traditional rule-based methods struggle to incorporate the full scope of traffic rules, we develop a Traffic Regulation Retrieval (TRR) Agent based on Retrieval-Augmented Generation (RAG) to automatically retrieve relevant traffic rules and guidelines from extensive regulation documents and relevant records based on the ego vehicle's situation. Given the semantic complexity of the retrieved rules, we also design a reasoning module powered by a Large Language Model (LLM) to interpret these rules, differentiate between mandatory rules and safety guidelines, and assess actions on legal compliance and safety. Additionally, the reasoning is designed to be interpretable, enhancing both transparency and reliability. The framework demonstrates robust performance on both hypothesized and real-world cases across diverse scenarios, along with the ability to adapt to different regions with ease.
CooPre: Cooperative Pretraining for V2X Cooperative Perception
Aug 20, 2024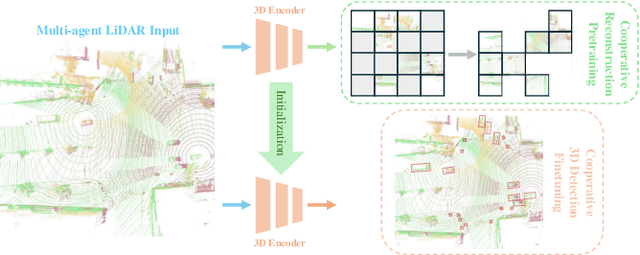
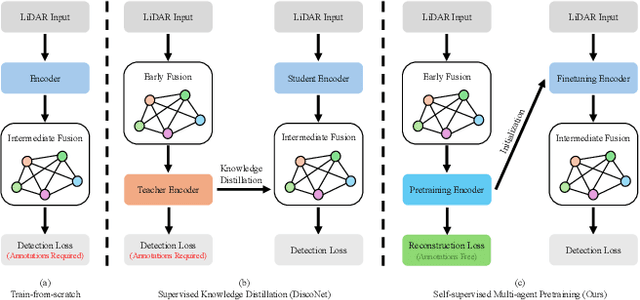

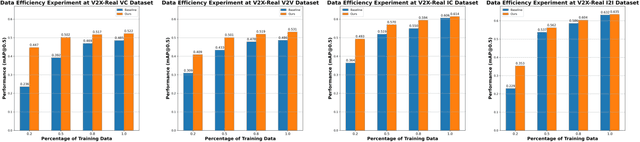
Existing Vehicle-to-Everything (V2X) cooperative perception methods rely on accurate multi-agent 3D annotations. Nevertheless, it is time-consuming and expensive to collect and annotate real-world data, especially for V2X systems. In this paper, we present a self-supervised learning method for V2X cooperative perception, which utilizes the vast amount of unlabeled 3D V2X data to enhance the perception performance. Beyond simply extending the previous pre-training methods for point-cloud representation learning, we introduce a novel self-supervised Cooperative Pretraining framework (termed as CooPre) customized for a collaborative scenario. We point out that cooperative point-cloud sensing compensates for information loss among agents. This motivates us to design a novel proxy task for the 3D encoder to reconstruct LiDAR point clouds across different agents. Besides, we develop a V2X bird-eye-view (BEV) guided masking strategy which effectively allows the model to pay attention to 3D features across heterogeneous V2X agents (i.e., vehicles and infrastructure) in the BEV space. Noticeably, such a masking strategy effectively pretrains the 3D encoder and is compatible with mainstream cooperative perception backbones. Our approach, validated through extensive experiments on representative datasets (i.e., V2X-Real, V2V4Real, and OPV2V), leads to a performance boost across all V2X settings. Additionally, we demonstrate the framework's improvements in cross-domain transferability, data efficiency, and robustness under challenging scenarios. The code will be made publicly available.
Towards Subcentimeter Accuracy Digital-Twin Tracking via An RGBD-based Transformer Model and A Comprehensive Mobile Dataset
Sep 24, 2023The potential of digital twin technology, involving the creation of precise digital replicas of physical objects, to reshape AR experiences in 3D object tracking and localization scenarios is significant. However, enabling 3D object tracking with subcentimeter accuracy in dynamic mobile AR environments remains a formidable challenge. These scenarios often require a more robust pose estimator capable of handling the inherent sensor-level measurement noise. In this paper, recognizing the absence of comprehensive solutions in existing literature, we build upon our previous work, the Digital Twin Tracking Dataset (DTTD), to address these challenges in mobile AR settings. Specifically, we propose a transformer-based 6DoF pose estimator designed to withstand the challenges posed by noisy depth data. Simultaneously, we introduce a novel RGBD dataset captured using a cutting-edge mobile sensor, the iPhone 14 Pro, expanding the applicability of our approach to iPhone sensor data. Through extensive experimentation and in-depth analysis, we illustrate the effectiveness of our methods in the face of significant depth data errors, surpassing the performance of existing baselines. Code will be made publicly available.