 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni123: Exploring 3D Native Foundation Models with Limited 3D Data by Unifying Text to 2D and 3D Generation
Apr 02, 2026Recent multimodal large language models have achieved strong performance in unified text and image understanding and generation, yet extending such native capability to 3D remains challenging due to limited data. Compared to abundant 2D imagery, high-quality 3D assets are scarce, making 3D synthesis under-constrained. Existing methods often rely on indirect pipelines that edit in 2D and lift results into 3D via optimization, sacrificing geometric consistency. We present Omni123, a 3D-native foundation model that unifies text-to-2D and text-to-3D generation within a single autoregressive framework. Our key insight is that cross-modal consistency between images and 3D can serve as an implicit structural constraint. By representing text, images, and 3D as discrete tokens in a shared sequence space, the model leverages abundant 2D data as a geometric prior to improve 3D representations. We introduce an interleaved X-to-X training paradigm that coordinates diverse cross-modal tasks over heterogeneous paired datasets without requiring fully aligned text-image-3D triplets. By traversing semantic-visual-geometric cycles (e.g., text to image to 3D to image) within autoregressive sequences, the model jointly enforces semantic alignment, appearance fidelity, and multi-view geometric consistency. Experiments show that Omni123 significantly improves text-guided 3D generation and editing, demonstrating a scalable path toward multimodal 3D world models.
Faithful Contouring: Near-Lossless 3D Voxel Representation Free from Iso-surface
Nov 12, 2025



Accurate and efficient voxelized representations of 3D meshes are the foundation of 3D reconstruction and generation. However, existing representations based on iso-surface heavily rely on water-tightening or rendering optimization, which inevitably compromise geometric fidelity. We propose Faithful Contouring, a sparse voxelized representation that supports 2048+ resolutions for arbitrary meshes, requiring neither converting meshes to field functions nor extracting the isosurface during remeshing. It achieves near-lossless fidelity by preserving sharpness and internal structures, even for challenging cases with complex geometry and topology. The proposed method also shows flexibility for texturing, manipulation, and editing. Beyond representation, we design a dual-mode autoencoder for Faithful Contouring, enabling scalable and detail-preserving shape reconstruction. Extensive experiments show that Faithful Contouring surpasses existing methods in accuracy and efficiency for both representation and reconstruction. For direct representation, it achieves distance errors at the $10^{-5}$ level; for mesh reconstruction, it yields a 93\% reduction in Chamfer Distance and a 35\% improvement in F-score over strong baselines, confirming superior fidelity as a representation for 3D learning tasks.
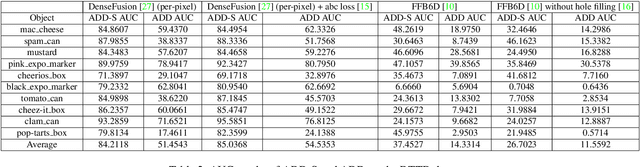
Towards Subcentimeter Accuracy Digital-Twin Tracking via An RGBD-based Transformer Model and A Comprehensive Mobile Dataset
Sep 24, 2023The potential of digital twin technology, involving the creation of precise digital replicas of physical objects, to reshape AR experiences in 3D object tracking and localization scenarios is significant. However, enabling 3D object tracking with subcentimeter accuracy in dynamic mobile AR environments remains a formidable challenge. These scenarios often require a more robust pose estimator capable of handling the inherent sensor-level measurement noise. In this paper, recognizing the absence of comprehensive solutions in existing literature, we build upon our previous work, the Digital Twin Tracking Dataset (DTTD), to address these challenges in mobile AR settings. Specifically, we propose a transformer-based 6DoF pose estimator designed to withstand the challenges posed by noisy depth data. Simultaneously, we introduce a novel RGBD dataset captured using a cutting-edge mobile sensor, the iPhone 14 Pro, expanding the applicability of our approach to iPhone sensor data. Through extensive experimentation and in-depth analysis, we illustrate the effectiveness of our methods in the face of significant depth data errors, surpassing the performance of existing baselines. Code will be made publicly available.
Generating Animatable 3D Cartoon Faces from Single Portraits
Jul 04, 2023



With the booming of virtual reality (VR) technology, there is a growing need for customized 3D avatars. However, traditional methods for 3D avatar modeling are either time-consuming or fail to retain similarity to the person being modeled. We present a novel framework to generate animatable 3D cartoon faces from a single portrait image. We first transfer an input real-world portrait to a stylized cartoon image with a StyleGAN. Then we propose a two-stage reconstruction method to recover the 3D cartoon face with detailed texture, which first makes a coarse estimation based on template models, and then refines the model by non-rigid deformation under landmark supervision. Finally, we propose a semantic preserving face rigging method based on manually created templates and deformation transfer. Compared with prior arts, qualitative and quantitative results show that our method achieves better accuracy, aesthetics, and similarity criteria. Furthermore, we demonstrate the capability of real-time facial animation of our 3D model.
Digital Twin Tracking Dataset : A New RGB+Depth 3D Dataset for Longer-Range Object Tracking Applications
Feb 12, 2023


Digital twin is a problem of augmenting real objects with their digital counterparts. It can underpin a wide range of applications in augmented reality (AR), autonomy, and UI/UX. A critical component in a good digital twin system is real-time, accurate 3D object tracking. Most existing works solve 3D object tracking through the lens of robotic grasping, employ older generations of depth sensors, and measure performance metrics that may not apply to other digital twin applications such as in AR. In this work, we create a novel RGB-D dataset, called Digital-Twin Tracking Dataset (DTTD), to enable further research of the problem and extend potential solutions towards longer ranges and mm localization accuracy. To reduce point cloud noise from the input source, we select the latest Microsoft Azure Kinect as the state-of-the-art time-of-flight (ToF) camera. In total, 103 scenes of 10 common off-the-shelf objects with rich textures are recorded, with each frame annotated with a per-pixel semantic segmentation and ground-truth object poses provided by a commercial motion capturing system. Through experiments, we demonstrate that DTTD can help researchers develop future object tracking methods and analyze new challenges. We provide the dataset, data generation, annotation, and model evaluation pipeline as open source code at: https://github.com/augcog/DTTDv1.
Object Pursuit: Building a Space of Objects via Discriminative Weight Generation
Dec 18, 2021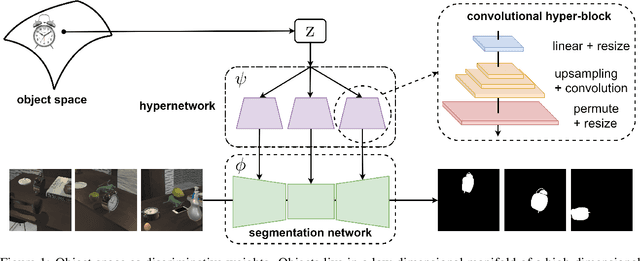



We propose a framework to continuously learn object-centric representations for visual learning and understanding. Existing object-centric representations either rely on supervisions that individualize objects in the scene, or perform unsupervised disentanglement that can hardly deal with complex scenes in the real world. To mitigate the annotation burden and relax the constraints on the statistical complexity of the data, our method leverages interactions to effectively sample diverse variations of an object and the corresponding training signals while learning the object-centric representations. Throughout learning, objects are streamed one by one in random order with unknown identities, and are associated with latent codes that can synthesize discriminative weights for each object through a convolutional hypernetwork. Moreover, re-identification of learned objects and forgetting prevention are employed to make the learning process efficient and robust. We perform an extensive study of the key features of the proposed framework and analyze the characteristics of the learned representations. Furthermore, we demonstrate the capability of the proposed framework in learning representations that can improve label efficiency in downstream tasks. Our code and trained models will be made publicly available.
Robust 3D Self-portraits in Seconds
Apr 06, 2020
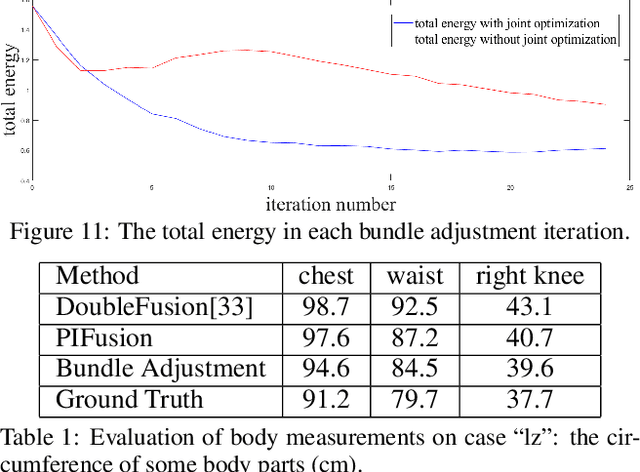
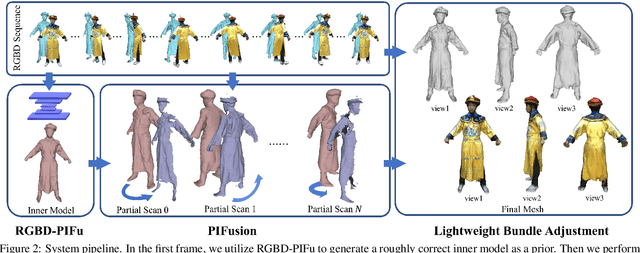

In this paper, we propose an efficient method for robust 3D self-portraits using a single RGBD camera. Benefiting from the proposed PIFusion and lightweight bundle adjustment algorithm, our method can generate detailed 3D self-portraits in seconds and shows the ability to handle subjects wearing extremely loose clothes. To achieve highly efficient and robust reconstruction, we propose PIFusion, which combines learning-based 3D recovery with volumetric non-rigid fusion to generate accurate sparse partial scans of the subject. Moreover, a non-rigid volumetric deformation method is proposed to continuously refine the learned shape prior. Finally, a lightweight bundle adjustment algorithm is proposed to guarantee that all the partial scans can not only "loop" with each other but also remain consistent with the selected live key observations. The results and experiments show that the proposed method achieves more robust and efficient 3D self-portraits compared with state-of-the-art methods.