 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaLoRAify: Calorie Estimation with Visual-Text Pairing and LoRA-Driven Visual Language Models
Dec 13, 2024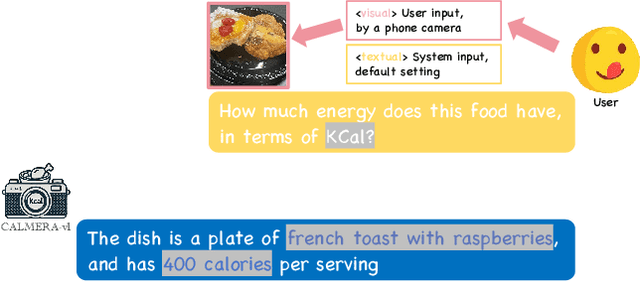
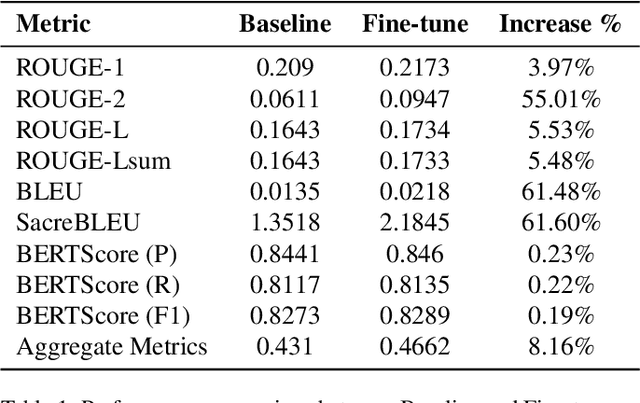
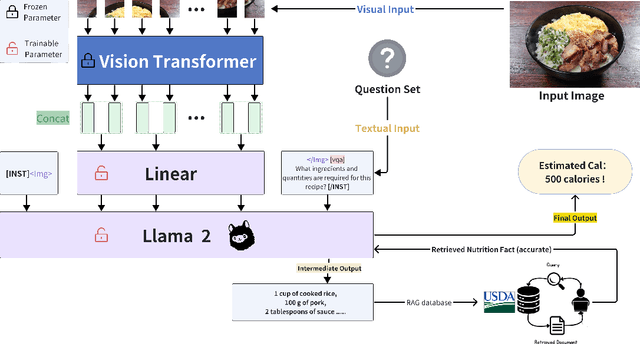

The obesity phenomenon, known as the heavy issue, is a leading cause of preventable chronic diseases worldwide. Traditional calorie estimation tools often rely on specific data formats or complex pipelines, limiting their practicality in real-world scenarios. Recently, vision-language models (VLMs) have excelled in understanding real-world contexts and enabling conversational interactions, making them ideal for downstream tasks such as ingredient analysis. However, applying VLMs to calorie estimation requires domain-specific data and alignment strategies. To this end, we curated CalData, a 330K image-text pair dataset tailored for ingredient recognition and calorie estimation, combining a large-scale recipe dataset with detailed nutritional instructions for robust vision-language training. Built upon this dataset, we present CaLoRAify, a novel VLM framework aligning ingredient recognition and calorie estimation via training with visual-text pairs. During inference, users only need a single monocular food image to estimate calories while retaining the flexibility of agent-based conversational interaction. With Low-rank Adaptation (LoRA) and Retrieve-augmented Generation (RAG) techniques, our system enhances the performance of foundational VLMs in the vertical domain of calorie estimation. Our code and data are fully open-sourced at https://github.com/KennyYao2001/16824-CaLORAify.
Towards Subcentimeter Accuracy Digital-Twin Tracking via An RGBD-based Transformer Model and A Comprehensive Mobile Dataset
Sep 24, 2023The potential of digital twin technology, involving the creation of precise digital replicas of physical objects, to reshape AR experiences in 3D object tracking and localization scenarios is significant. However, enabling 3D object tracking with subcentimeter accuracy in dynamic mobile AR environments remains a formidable challenge. These scenarios often require a more robust pose estimator capable of handling the inherent sensor-level measurement noise. In this paper, recognizing the absence of comprehensive solutions in existing literature, we build upon our previous work, the Digital Twin Tracking Dataset (DTTD), to address these challenges in mobile AR settings. Specifically, we propose a transformer-based 6DoF pose estimator designed to withstand the challenges posed by noisy depth data. Simultaneously, we introduce a novel RGBD dataset captured using a cutting-edge mobile sensor, the iPhone 14 Pro, expanding the applicability of our approach to iPhone sensor data. Through extensive experimentation and in-depth analysis, we illustrate the effectiveness of our methods in the face of significant depth data errors, surpassing the performance of existing baselines. Code will be made publicly available.