 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedBiCross: A Bi-Level Optimization Framework to Tackle Non-IID Challenges in Data-Free One-Shot Federated Learning on Medical Data
Jan 05, 2026Data-free knowledge distillation-based one-shot federated learning (OSFL) trains a model in a single communication round without sharing raw data, making OSFL attractive for privacy-sensitive medical applications. However, existing methods aggregate predictions from all clients to form a global teacher. Under non-IID data, conflicting predictions cancel out during averaging, yielding near-uniform soft labels that provide weak supervision for distillation. We propose FedBiCross, a personalized OSFL framework with three stages: (1) clustering clients by model output similarity to form coherent sub-ensembles, (2) bi-level cross-cluster optimization that learns adaptive weights to selectively leverage beneficial cross-cluster knowledge while suppressing negative transfer, and (3) personalized distillation for client-specific adaptation. Experiments on four medical image datasets demonstrate that FedBiCross consistently outperforms state-of-the-art baselines across different non-IID degrees.
Unbiased Reasoning for Knowledge-Intensive Tasks in Large Language Models via Conditional Front-Door Adjustment
Aug 23, 2025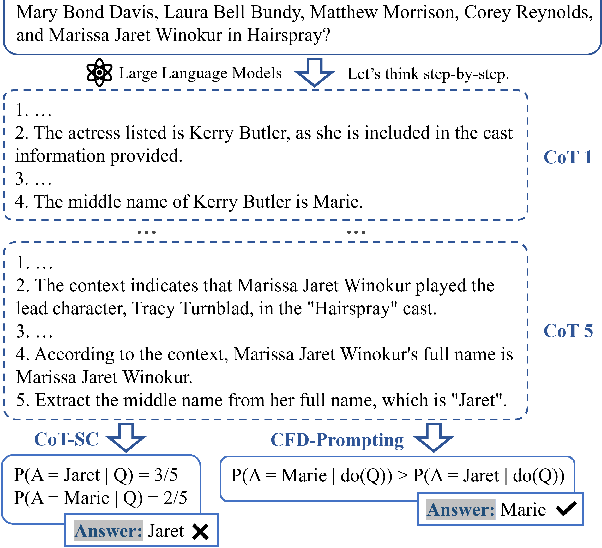
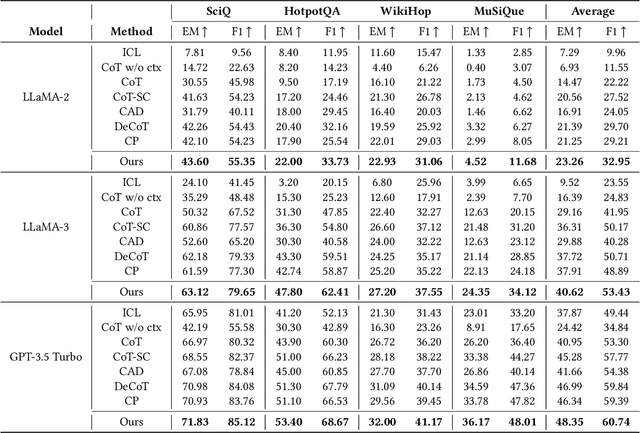
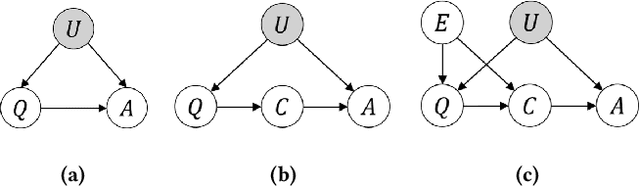
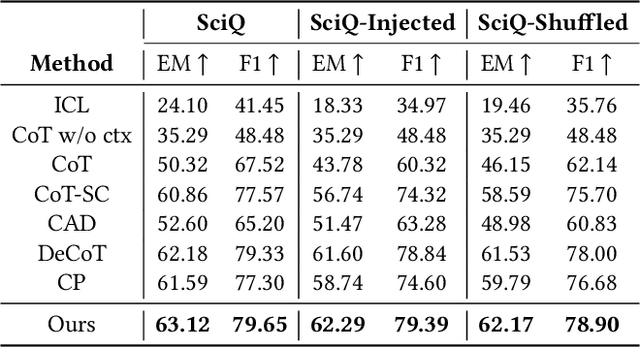
Large Language Models (LLMs) have shown impressive capabilities in natural language processing but still struggle to perform well on knowledge-intensive tasks that require deep reasoning and the integration of external knowledge. Although methods such as Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) have been proposed to enhance LLMs with external knowledge, they still suffer from internal bias in LLMs, which often leads to incorrect answers. In this paper, we propose a novel causal prompting framework, Conditional Front-Door Prompting (CFD-Prompting), which enables the unbiased estimation of the causal effect between the query and the answer, conditional on external knowledge, while mitigating internal bias. By constructing counterfactual external knowledge, our framework simulates how the query behaves under varying contexts, addressing the challenge that the query is fixed and is not amenable to direct causal intervention. Compared to the standard front-door adjustment, the conditional variant operates under weaker assumptions, enhancing both robustness and generalisability of the reasoning process. Extensive experiments across multiple LLMs and benchmark datasets demonstrate that CFD-Prompting significantly outperforms existing baselines in both accuracy and robustness.
JotlasNet: Joint Tensor Low-Rank and Attention-based Sparse Unrolling Network for Accelerating Dynamic MRI
Feb 17, 2025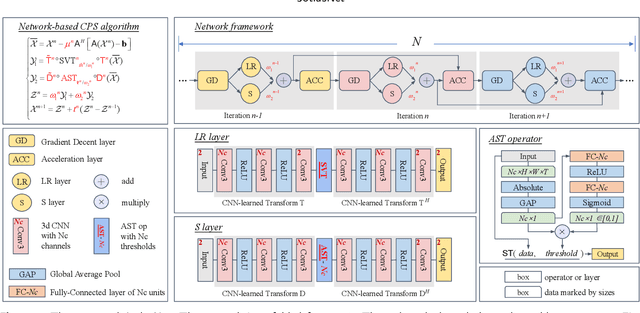

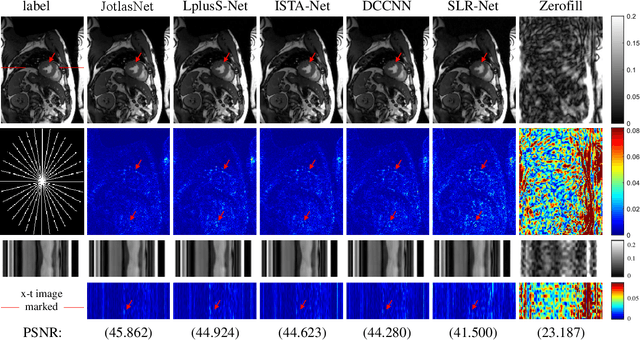

Joint low-rank and sparse unrolling networks have shown superior performance in dynamic MRI reconstruction. However, existing works mainly utilized matrix low-rank priors, neglecting the tensor characteristics of dynamic MRI images, and only a global threshold is applied for the sparse constraint to the multi-channel data, limiting the flexibility of the network. Additionally, most of them have inherently complex network structure, with intricate interactions among variables. In this paper, we propose a novel deep unrolling network, JotlasNet, for dynamic MRI reconstruction by jointly utilizing tensor low-rank and attention-based sparse priors. Specifically, we utilize tensor low-rank prior to exploit the structural correlations in high-dimensional data. Convolutional neural networks are used to adaptively learn the low-rank and sparse transform domains. A novel attention-based soft thresholding operator is proposed to assign a unique learnable threshold to each channel of the data in the CNN-learned sparse domain. The network is unrolled from the elaborately designed composite splitting algorithm and thus features a simple yet efficient parallel structure. Extensive experiments on two datasets (OCMR, CMRxRecon) demonstrate the superior performance of JotlasNet in dynamic MRI reconstruction.
* 13 pages, 7 figures, accepted by Magnetic Resonance Imaging
CaLoRAify: Calorie Estimation with Visual-Text Pairing and LoRA-Driven Visual Language Models
Dec 13, 2024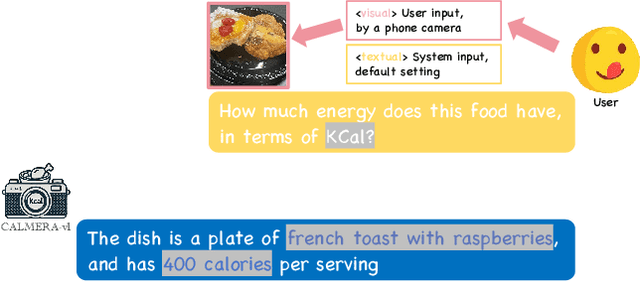
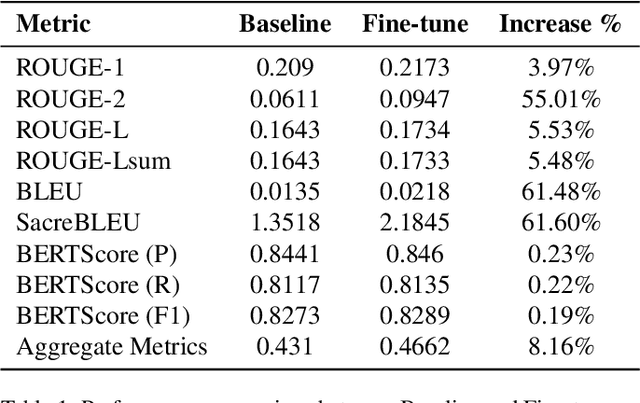
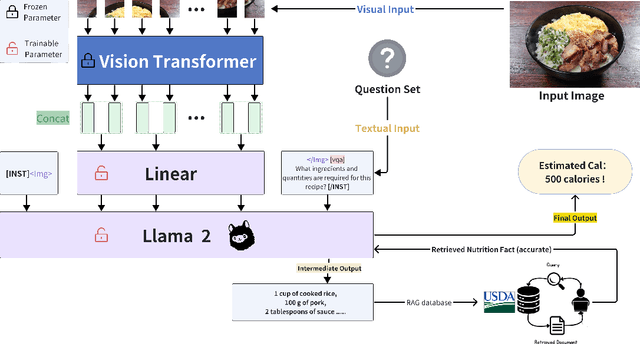

The obesity phenomenon, known as the heavy issue, is a leading cause of preventable chronic diseases worldwide. Traditional calorie estimation tools often rely on specific data formats or complex pipelines, limiting their practicality in real-world scenarios. Recently, vision-language models (VLMs) have excelled in understanding real-world contexts and enabling conversational interactions, making them ideal for downstream tasks such as ingredient analysis. However, applying VLMs to calorie estimation requires domain-specific data and alignment strategies. To this end, we curated CalData, a 330K image-text pair dataset tailored for ingredient recognition and calorie estimation, combining a large-scale recipe dataset with detailed nutritional instructions for robust vision-language training. Built upon this dataset, we present CaLoRAify, a novel VLM framework aligning ingredient recognition and calorie estimation via training with visual-text pairs. During inference, users only need a single monocular food image to estimate calories while retaining the flexibility of agent-based conversational interaction. With Low-rank Adaptation (LoRA) and Retrieve-augmented Generation (RAG) techniques, our system enhances the performance of foundational VLMs in the vertical domain of calorie estimation. Our code and data are fully open-sourced at https://github.com/KennyYao2001/16824-CaLORAify.
Differentiable SVD based on Moore-Penrose Pseudoinverse for Inverse Imaging Problems
Nov 21, 2024Low-rank regularization-based deep unrolling networks have achieved remarkable success in various inverse imaging problems (IIPs). However, the singular value decomposition (SVD) is non-differentiable when duplicated singular values occur, leading to severe numerical instability during training. In this paper, we propose a differentiable SVD based on the Moore-Penrose pseudoinverse to address this issue. To the best of our knowledge, this is the first work to provide a comprehensive analysis of the differentiability of the trivial SVD. Specifically, we show that the non-differentiability of SVD is essentially due to an underdetermined system of linear equations arising in the derivation process. We utilize the Moore-Penrose pseudoinverse to solve the system, thereby proposing a differentiable SVD. A numerical stability analysis in the context of IIPs is provided. Experimental results in color image compressed sensing and dynamic MRI reconstruction show that our proposed differentiable SVD can effectively address the numerical instability issue while ensuring computational precision. Code is available at https://github.com/yhao-z/SVD-inv.
Causal Effect Estimation using identifiable Variational AutoEncoder with Latent Confounders and Post-Treatment Variables
Aug 13, 2024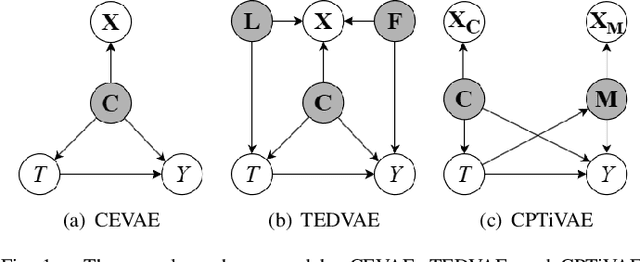
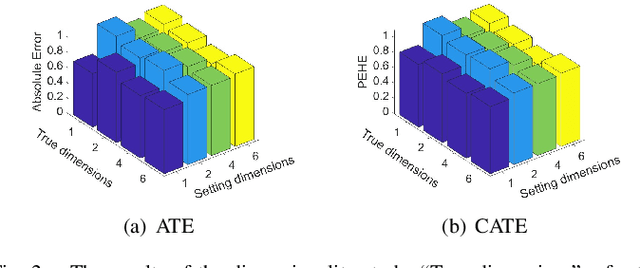
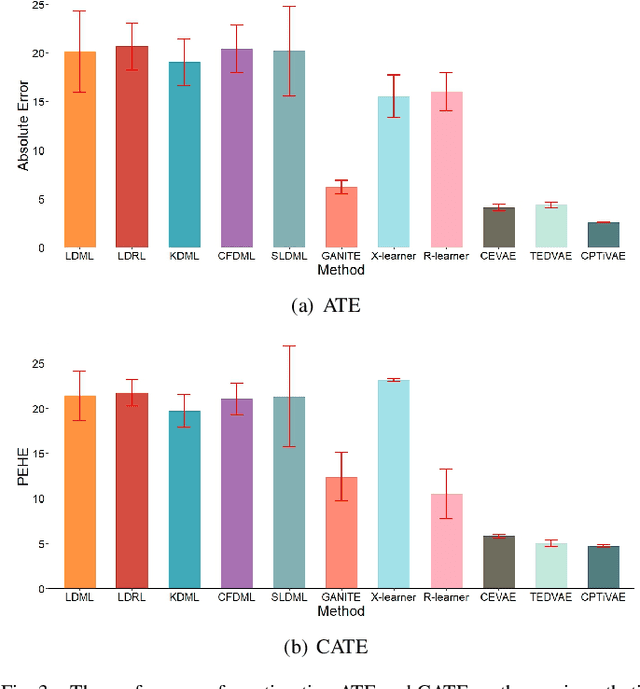
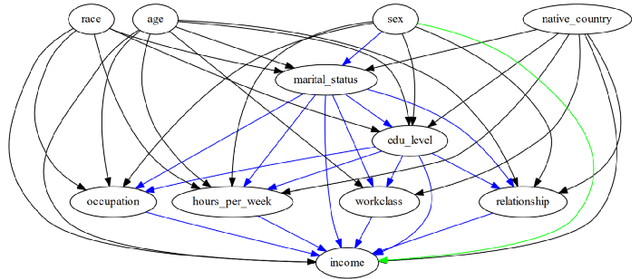
Estimating causal effects from observational data is challenging, especially in the presence of latent confounders. Much work has been done on addressing this challenge, but most of the existing research ignores the bias introduced by the post-treatment variables. In this paper, we propose a novel method of joint Variational AutoEncoder (VAE) and identifiable Variational AutoEncoder (iVAE) for learning the representations of latent confounders and latent post-treatment variables from their proxy variables, termed CPTiVAE, to achieve unbiased causal effect estimation from observational data. We further prove the identifiability in terms of the representation of latent post-treatment variables. Extensive experiments on synthetic and semi-synthetic datasets demonstrate that the CPTiVAE outperforms the state-of-the-art methods in the presence of latent confounders and post-treatment variables. We further apply CPTiVAE to a real-world dataset to show its potential application.
Disentangled Latent Representation Learning for Tackling the Confounding M-Bias Problem in Causal Inference
Dec 08, 2023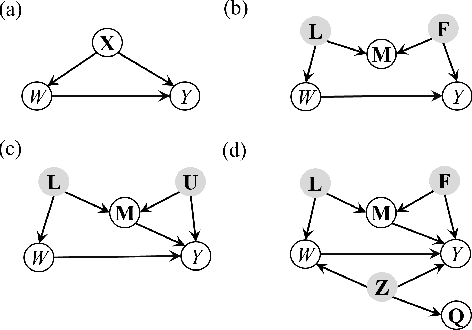
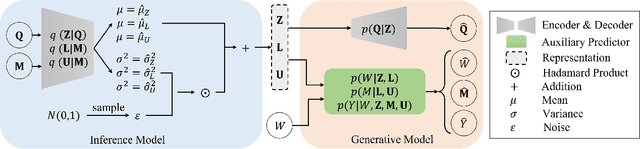

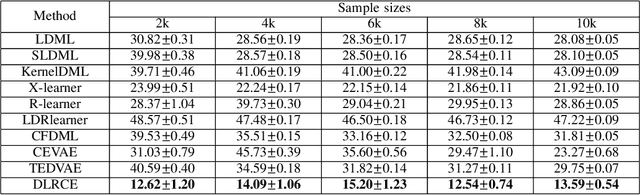
In causal inference, it is a fundamental task to estimate the causal effect from observational data. However, latent confounders pose major challenges in causal inference in observational data, for example, confounding bias and M-bias. Recent data-driven causal effect estimators tackle the confounding bias problem via balanced representation learning, but assume no M-bias in the system, thus they fail to handle the M-bias. In this paper, we identify a challenging and unsolved problem caused by a variable that leads to confounding bias and M-bias simultaneously. To address this problem with co-occurring M-bias and confounding bias, we propose a novel Disentangled Latent Representation learning framework for learning latent representations from proxy variables for unbiased Causal effect Estimation (DLRCE) from observational data. Specifically, DLRCE learns three sets of latent representations from the measured proxy variables to adjust for the confounding bias and M-bias. Extensive experiments on both synthetic and three real-world datasets demonstrate that DLRCE significantly outperforms the state-of-the-art estimators in the case of the presence of both confounding bias and M-bias.
Deep unrolling Shrinkage Network for Dynamic MR imaging
Jul 19, 2023Deep unrolling networks that utilize sparsity priors have achieved great success in dynamic magnetic resonance (MR) imaging. The convolutional neural network (CNN) is usually utilized to extract the transformed domain, and then the soft thresholding (ST) operator is applied to the CNN-transformed data to enforce the sparsity priors. However, the ST operator is usually constrained to be the same across all channels of the CNN-transformed data. In this paper, we propose a novel operator, called soft thresholding with channel attention (AST), that learns the threshold for each channel. In particular, we put forward a novel deep unrolling shrinkage network (DUS-Net) by unrolling the alternating direction method of multipliers (ADMM) for optimizing the transformed $l_1$ norm dynamic MR reconstruction model. Experimental results on an open-access dynamic cine MR dataset demonstrate that the proposed DUS-Net outperforms the state-of-the-art methods. The source code is available at \url{https://github.com/yhao-z/DUS-Net}.
SCULPTOR: Skeleton-Consistent Face Creation Using a Learned Parametric Generator
Sep 14, 2022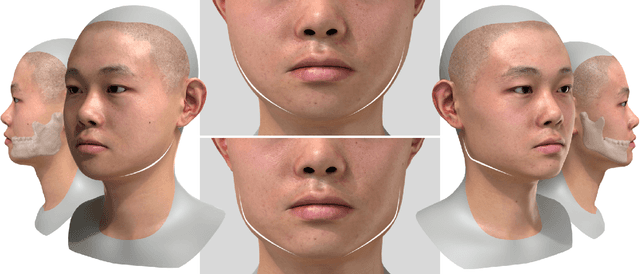
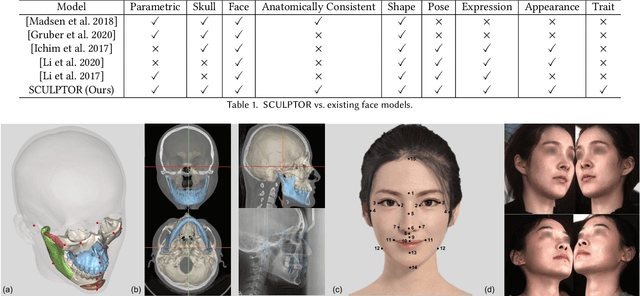
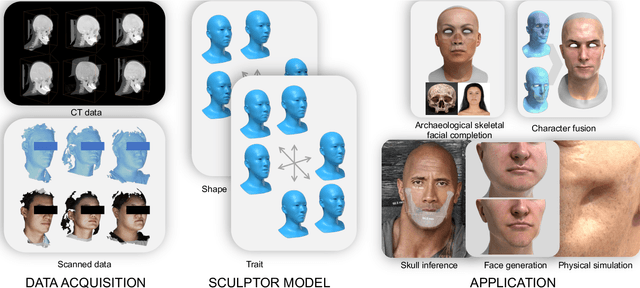
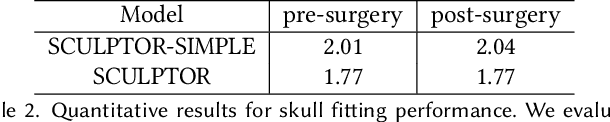
Recent years have seen growing interest in 3D human faces modelling due to its wide applications in digital human, character generation and animation. Existing approaches overwhelmingly emphasized on modeling the exterior shapes, textures and skin properties of faces, ignoring the inherent correlation between inner skeletal structures and appearance. In this paper, we present SCULPTOR, 3D face creations with Skeleton Consistency Using a Learned Parametric facial generaTOR, aiming to facilitate easy creation of both anatomically correct and visually convincing face models via a hybrid parametric-physical representation. At the core of SCULPTOR is LUCY, the first large-scale shape-skeleton face dataset in collaboration with plastic surgeons. Named after the fossils of one of the oldest known human ancestors, our LUCY dataset contains high-quality Computed Tomography (CT) scans of the complete human head before and after orthognathic surgeries, critical for evaluating surgery results. LUCY consists of 144 scans of 72 subjects (31 male and 41 female) where each subject has two CT scans taken pre- and post-orthognathic operations. Based on our LUCY dataset, we learn a novel skeleton consistent parametric facial generator, SCULPTOR, which can create the unique and nuanced facial features that help define a character and at the same time maintain physiological soundness. Our SCULPTOR jointly models the skull, face geometry and face appearance under a unified data-driven framework, by separating the depiction of a 3D face into shape blend shape, pose blend shape and facial expression blend shape. SCULPTOR preserves both anatomic correctness and visual realism in facial generation tasks compared with existing methods. Finally, we showcase the robustness and effectiveness of SCULPTOR in various fancy applications unseen before.
T$^2$LR-Net: An Unrolling Reconstruction Network Learning Transformed Tensor Low-Rank prior for Dynamic MR Imaging
Sep 08, 2022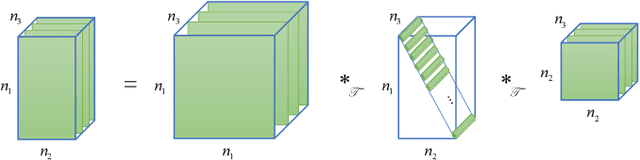
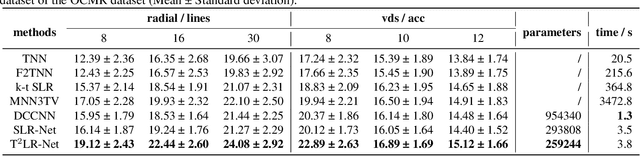
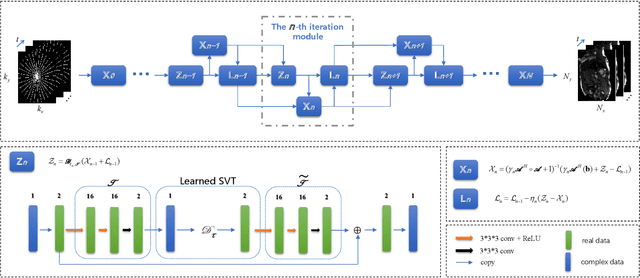
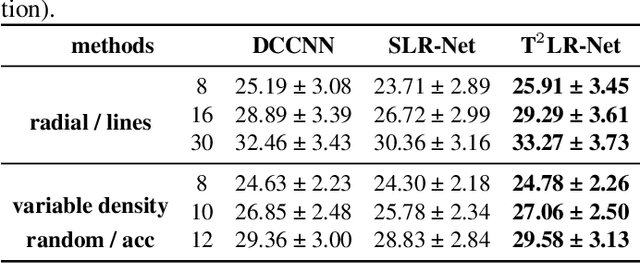
While the methods exploiting the tensor low-rank prior are booming in high-dimensional data processing and have obtained satisfying performance, their applications in dynamic magnetic resonance (MR) image reconstruction are limited. In this paper, we concentrate on the tensor singular value decomposition (t-SVD), which is based on the Fast Fourier Transform (FFT) and only provides the definite and limited tensor low-rank prior in the FFT domain, heavily reliant upon how closely the data and the FFT domain match up. By generalizing the FFT into an arbitrary unitary transformation of the transformed t-SVD and proposing the transformed tensor nuclear norm (TTNN), we introduce a flexible model based on TTNN with the ability to exploit the tensor low-rank prior of a transformed domain in a larger transformation space and elaborately design an iterative optimization algorithm based on the alternating direction method of multipliers (ADMM), which is further unrolled into a model-based deep unrolling reconstruction network to learn the transformed tensor low-rank prior (T$^2$LR-Net). The convolutional neural network (CNN) is incorporated within the T$^2$LR-Net to learn the best-matched transform from the dynamic MR image dataset. The unrolling reconstruction network also provides a new perspective on the low-rank prior utilization by exploiting the low-rank prior in the CNN-extracted feature domain. Experimental results on two cardiac cine MR datasets demonstrate that the proposed framework can provide improved recovery results compared with the state-of-the-art optimization-based and unrolling network-based methods.