 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Fake News Detection on Unseen Domains via LLM-Based Domain-Aware User Modeling
Feb 02, 2026Cross-domain fake news detection (CD-FND) transfers knowledge from a source domain to a target domain and is crucial for real-world fake news mitigation. This task becomes particularly important yet more challenging when the target domain is previously unseen (e.g., the COVID-19 outbreak or the Russia-Ukraine war). However, existing CD-FND methods overlook such scenarios and consequently suffer from the following two key limitations: (1) insufficient modeling of high-level semantics in news and user engagements; and (2) scarcity of labeled data in unseen domains. Targeting these limitations, we find that large language models (LLMs) offer strong potential for CD-FND on unseen domains, yet their effective use remains non-trivial. Nevertheless, two key challenges arise: (1) how to capture high-level semantics from both news content and user engagements using LLMs; and (2) how to make LLM-generated features more reliable and transferable for CD-FND on unseen domains. To tackle these challenges, we propose DAUD, a novel LLM-Based Domain-Aware framework for fake news detection on Unseen Domains. DAUD employs LLMs to extract high-level semantics from news content. It models users' single- and cross-domain engagements to generate domain-aware behavioral representations. In addition, DAUD captures the relations between original data-driven features and LLM-derived features of news, users, and user engagements. This allows it to extract more reliable domain-shared representations that improve knowledge transfer to unseen domains. Extensive experiments on real-world datasets demonstrate that DAUD outperforms state-of-the-art baselines in both general and unseen-domain CD-FND settings.
Debiasing Large Language Models via Adaptive Causal Prompting with Sketch-of-Thought
Jan 13, 2026Despite notable advancements in prompting methods for Large Language Models (LLMs), such as Chain-of-Thought (CoT), existing strategies still suffer from excessive token usage and limited generalisability across diverse reasoning tasks. To address these limitations, we propose an Adaptive Causal Prompting with Sketch-of-Thought (ACPS) framework, which leverages structural causal models to infer the causal effect of a query on its answer and adaptively select an appropriate intervention (i.e., standard front-door and conditional front-door adjustments). This design enables generalisable causal reasoning across heterogeneous tasks without task-specific retraining. By replacing verbose CoT with concise Sketch-of-Thought, ACPS enables efficient reasoning that significantly reduces token usage and inference cost. Extensive experiments on multiple reasoning benchmarks and LLMs demonstrate that ACPS consistently outperforms existing prompting baselines in terms of accuracy, robustness, and computational efficiency.
Addressing Mark Imbalance in Integration-free Neural Marked Temporal Point Processes
Oct 23, 2025Marked Temporal Point Process (MTPP) has been well studied to model the event distribution in marked event streams, which can be used to predict the mark and arrival time of the next event. However, existing studies overlook that the distribution of event marks is highly imbalanced in many real-world applications, with some marks being frequent but others rare. The imbalance poses a significant challenge to the performance of the next event prediction, especially for events of rare marks. To address this issue, we propose a thresholding method, which learns thresholds to tune the mark probability normalized by the mark's prior probability to optimize mark prediction, rather than predicting the mark directly based on the mark probability as in existing studies. In conjunction with this method, we predict the mark first and then the time. In particular, we develop a novel neural MTPP model to support effective time sampling and estimation of mark probability without computationally expensive numerical improper integration. Extensive experiments on real-world datasets demonstrate the superior performance of our solution against various baselines for the next event mark and time prediction. The code is available at https://github.com/undes1red/IFNMTPP.
REFER: Mitigating Bias in Opinion Summarisation via Frequency Framed Prompting
Sep 19, 2025Individuals express diverse opinions, a fair summary should represent these viewpoints comprehensively. Previous research on fairness in opinion summarisation using large language models (LLMs) relied on hyperparameter tuning or providing ground truth distributional information in prompts. However, these methods face practical limitations: end-users rarely modify default model parameters, and accurate distributional information is often unavailable. Building upon cognitive science research demonstrating that frequency-based representations reduce systematic biases in human statistical reasoning by making reference classes explicit and reducing cognitive load, this study investigates whether frequency framed prompting (REFER) can similarly enhance fairness in LLM opinion summarisation. Through systematic experimentation with different prompting frameworks, we adapted techniques known to improve human reasoning to elicit more effective information processing in language models compared to abstract probabilistic representations.Our results demonstrate that REFER enhances fairness in language models when summarising opinions. This effect is particularly pronounced in larger language models and using stronger reasoning instructions.
Less Is More? Examining Fairness in Pruned Large Language Models for Summarising Opinions
Aug 25, 2025Model compression through post-training pruning offers a way to reduce model size and computational requirements without significantly impacting model performance. However, the effect of pruning on the fairness of LLM-generated summaries remains unexplored, particularly for opinion summarisation where biased outputs could influence public views.In this paper, we present a comprehensive empirical analysis of opinion summarisation, examining three state-of-the-art pruning methods and various calibration sets across three open-source LLMs using four fairness metrics. Our systematic analysis reveals that pruning methods have a greater impact on fairness than calibration sets. Building on these insights, we propose High Gradient Low Activation (HGLA) pruning, which identifies and removes parameters that are redundant for input processing but influential in output generation. Our experiments demonstrate that HGLA can better maintain or even improve fairness compared to existing methods, showing promise across models and tasks where traditional methods have limitations. Our human evaluation shows HGLA-generated outputs are fairer than existing state-of-the-art pruning methods. Code is available at: https://github.com/amberhuang01/HGLA.
Unbiased Reasoning for Knowledge-Intensive Tasks in Large Language Models via Conditional Front-Door Adjustment
Aug 23, 2025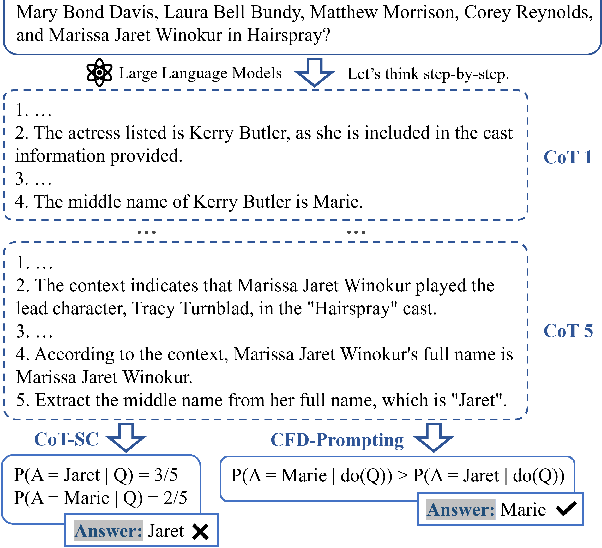
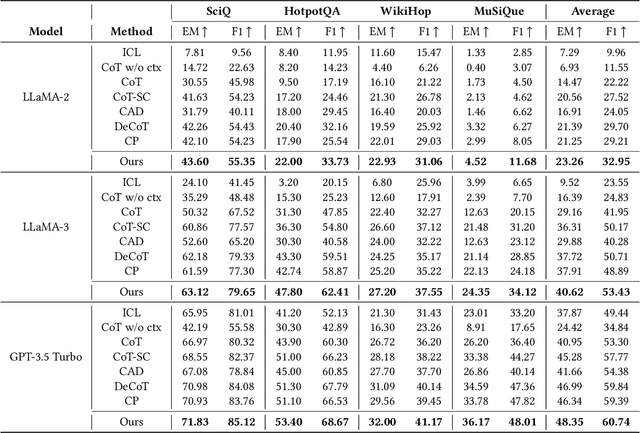
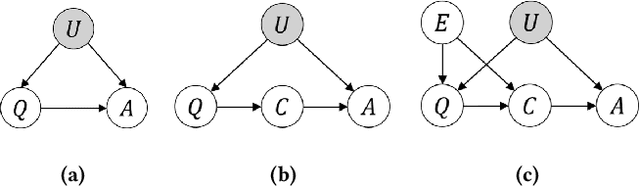
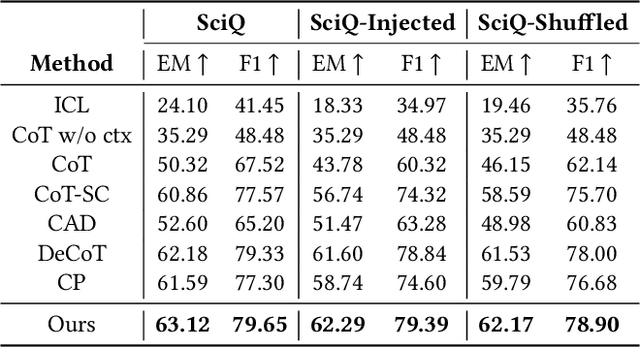
Large Language Models (LLMs) have shown impressive capabilities in natural language processing but still struggle to perform well on knowledge-intensive tasks that require deep reasoning and the integration of external knowledge. Although methods such as Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) have been proposed to enhance LLMs with external knowledge, they still suffer from internal bias in LLMs, which often leads to incorrect answers. In this paper, we propose a novel causal prompting framework, Conditional Front-Door Prompting (CFD-Prompting), which enables the unbiased estimation of the causal effect between the query and the answer, conditional on external knowledge, while mitigating internal bias. By constructing counterfactual external knowledge, our framework simulates how the query behaves under varying contexts, addressing the challenge that the query is fixed and is not amenable to direct causal intervention. Compared to the standard front-door adjustment, the conditional variant operates under weaker assumptions, enhancing both robustness and generalisability of the reasoning process. Extensive experiments across multiple LLMs and benchmark datasets demonstrate that CFD-Prompting significantly outperforms existing baselines in both accuracy and robustness.
Cultural Bias Matters: A Cross-Cultural Benchmark Dataset and Sentiment-Enriched Model for Understanding Multimodal Metaphors
Jun 08, 2025
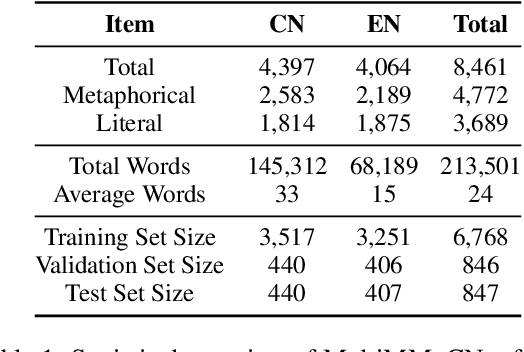

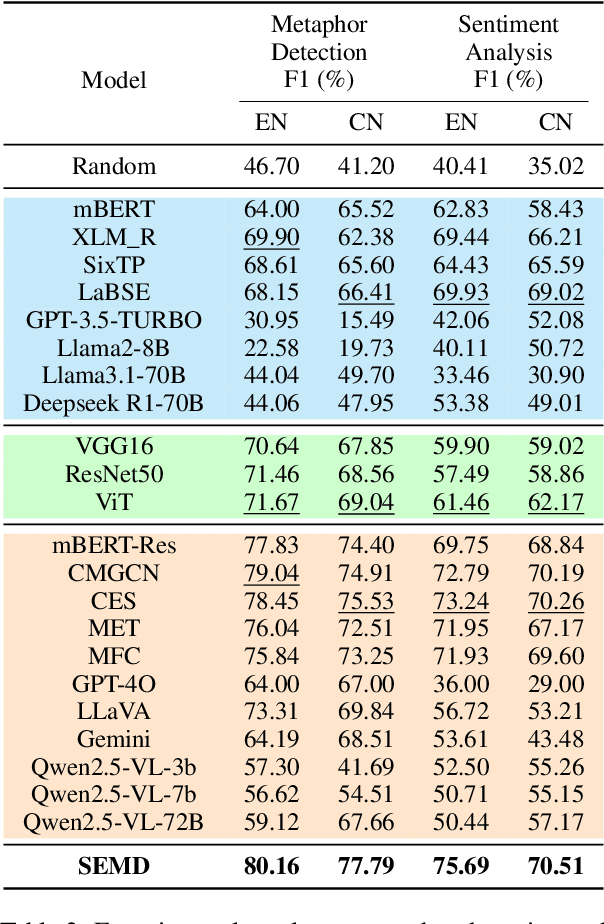
Metaphors are pervasive in communication, making them crucial for natural language processing (NLP). Previous research on automatic metaphor processing predominantly relies on training data consisting of English samples, which often reflect Western European or North American biases. This cultural skew can lead to an overestimation of model performance and contributions to NLP progress. However, the impact of cultural bias on metaphor processing, particularly in multimodal contexts, remains largely unexplored. To address this gap, we introduce MultiMM, a Multicultural Multimodal Metaphor dataset designed for cross-cultural studies of metaphor in Chinese and English. MultiMM consists of 8,461 text-image advertisement pairs, each accompanied by fine-grained annotations, providing a deeper understanding of multimodal metaphors beyond a single cultural domain. Additionally, we propose Sentiment-Enriched Metaphor Detection (SEMD), a baseline model that integrates sentiment embeddings to enhance metaphor comprehension across cultural backgrounds. Experimental results validate the effectiveness of SEMD on metaphor detection and sentiment analysis tasks. We hope this work increases awareness of cultural bias in NLP research and contributes to the development of fairer and more inclusive language models. Our dataset and code are available at https://github.com/DUTIR-YSQ/MultiMM.
Generating Grounded Responses to Counter Misinformation via Learning Efficient Fine-Grained Critiques
Jun 06, 2025Fake news and misinformation poses a significant threat to society, making efficient mitigation essential. However, manual fact-checking is costly and lacks scalability. Large Language Models (LLMs) offer promise in automating counter-response generation to mitigate misinformation, but a critical challenge lies in their tendency to hallucinate non-factual information. Existing models mainly rely on LLM self-feedback to reduce hallucination, but this approach is computationally expensive. In this paper, we propose MisMitiFact, Misinformation Mitigation grounded in Facts, an efficient framework for generating fact-grounded counter-responses at scale. MisMitiFact generates simple critique feedback to refine LLM outputs, ensuring responses are grounded in evidence. We develop lightweight, fine-grained critique models trained on data sourced from readily available fact-checking sites to identify and correct errors in key elements such as numerals, entities, and topics in LLM generations. Experiments show that MisMitiFact generates counter-responses of comparable quality to LLMs' self-feedback while using significantly smaller critique models. Importantly, it achieves ~5x increase in feedback generation throughput, making it highly suitable for cost-effective, large-scale misinformation mitigation. Code and LLM prompt templates are at https://github.com/xxfwin/MisMitiFact.
QQSUM: A Novel Task and Model of Quantitative Query-Focused Summarization for Review-based Product Question Answering
Jun 04, 2025Review-based Product Question Answering (PQA) allows e-commerce platforms to automatically address customer queries by leveraging insights from user reviews. However, existing PQA systems generate answers with only a single perspective, failing to capture the diversity of customer opinions. In this paper we introduce a novel task Quantitative Query-Focused Summarization (QQSUM), which aims to summarize diverse customer opinions into representative Key Points (KPs) and quantify their prevalence to effectively answer user queries. While Retrieval-Augmented Generation (RAG) shows promise for PQA, its generated answers still fall short of capturing the full diversity of viewpoints. To tackle this challenge, our model QQSUM-RAG, which extends RAG, employs few-shot learning to jointly train a KP-oriented retriever and a KP summary generator, enabling KP-based summaries that capture diverse and representative opinions. Experimental results demonstrate that QQSUM-RAG achieves superior performance compared to state-of-the-art RAG baselines in both textual quality and quantification accuracy of opinions. Our source code is available at: https://github.com/antangrocket1312/QQSUMM
A Macro- and Micro-Hierarchical Transfer Learning Framework for Cross-Domain Fake News Detection
Feb 20, 2025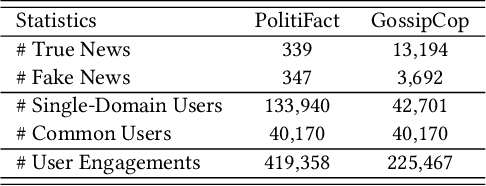
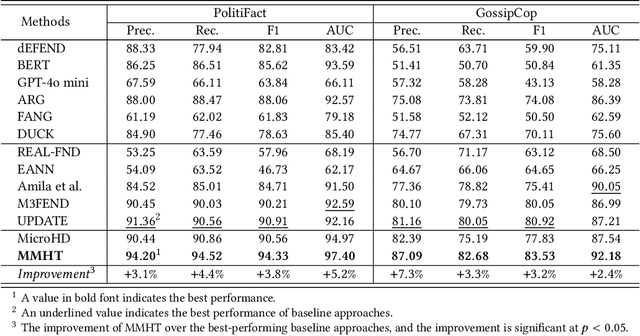
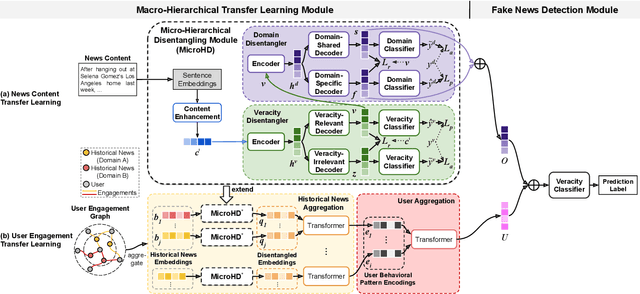
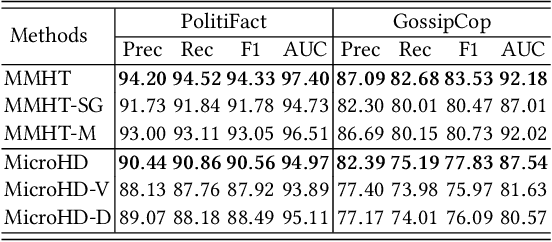
Cross-domain fake news detection aims to mitigate domain shift and improve detection performance by transferring knowledge across domains. Existing approaches transfer knowledge based on news content and user engagements from a source domain to a target domain. However, these approaches face two main limitations, hindering effective knowledge transfer and optimal fake news detection performance. Firstly, from a micro perspective, they neglect the negative impact of veracity-irrelevant features in news content when transferring domain-shared features across domains. Secondly, from a macro perspective, existing approaches ignore the relationship between user engagement and news content, which reveals shared behaviors of common users across domains and can facilitate more effective knowledge transfer. To address these limitations, we propose a novel macro- and micro- hierarchical transfer learning framework (MMHT) for cross-domain fake news detection. Firstly, we propose a micro-hierarchical disentangling module to disentangle veracity-relevant and veracity-irrelevant features from news content in the source domain for improving fake news detection performance in the target domain. Secondly, we propose a macro-hierarchical transfer learning module to generate engagement features based on common users' shared behaviors in different domains for improving effectiveness of knowledge transfer. Extensive experiments on real-world datasets demonstrate that our framework significantly outperforms the state-of-the-art baselines.