 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatLands: Generative Floormap Completion From a Single Egocentric View
Mar 16, 2026A single egocentric image typically captures only a small portion of the floor, yet a complete metric traversability map of the surroundings would better serve applications such as indoor navigation. We introduce FlatLands, a dataset and benchmark for single-view bird's-eye view (BEV) floor completion. The dataset contains 270,575 observations from 17,656 real metric indoor scenes drawn from six existing datasets, with aligned observation, visibility, validity, and ground-truth BEV maps, and the benchmark includes both in- and out-of-distribution evaluation protocols. We compare training-free approaches, deterministic models, ensembles, and stochastic generative models. Finally, we instantiate the task as an end-to-end monocular RGB-to-floormaps pipeline. FlatLands provides a rigorous testbed for uncertainty-aware indoor mapping and generative completion for embodied navigation.
Room Envelopes: A Synthetic Dataset for Indoor Layout Reconstruction from Images
Nov 06, 2025Modern scene reconstruction methods are able to accurately recover 3D surfaces that are visible in one or more images. However, this leads to incomplete reconstructions, missing all occluded surfaces. While much progress has been made on reconstructing entire objects given partial observations using generative models, the structural elements of a scene, like the walls, floors and ceilings, have received less attention. We argue that these scene elements should be relatively easy to predict, since they are typically planar, repetitive and simple, and so less costly approaches may be suitable. In this work, we present a synthetic dataset -- Room Envelopes -- that facilitates progress on this task by providing a set of RGB images and two associated pointmaps for each image: one capturing the visible surface and one capturing the first surface once fittings and fixtures are removed, that is, the structural layout. As we show, this enables direct supervision for feed-forward monocular geometry estimators that predict both the first visible surface and the first layout surface. This confers an understanding of the scene's extent, as well as the shape and location of its objects.
RefRef: A Synthetic Dataset and Benchmark for Reconstructing Refractive and Reflective Objects
May 09, 2025Modern 3D reconstruction and novel view synthesis approaches have demonstrated strong performance on scenes with opaque Lambertian objects. However, most assume straight light paths and therefore cannot properly handle refractive and reflective materials. Moreover, datasets specialized for these effects are limited, stymieing efforts to evaluate performance and develop suitable techniques. In this work, we introduce a synthetic RefRef dataset and benchmark for reconstructing scenes with refractive and reflective objects from posed images. Our dataset has 50 such objects of varying complexity, from single-material convex shapes to multi-material non-convex shapes, each placed in three different background types, resulting in 150 scenes. We also propose an oracle method that, given the object geometry and refractive indices, calculates accurate light paths for neural rendering, and an approach based on this that avoids these assumptions. We benchmark these against several state-of-the-art methods and show that all methods lag significantly behind the oracle, highlighting the challenges of the task and dataset.
Probability Density Geodesics in Image Diffusion Latent Space
Apr 09, 2025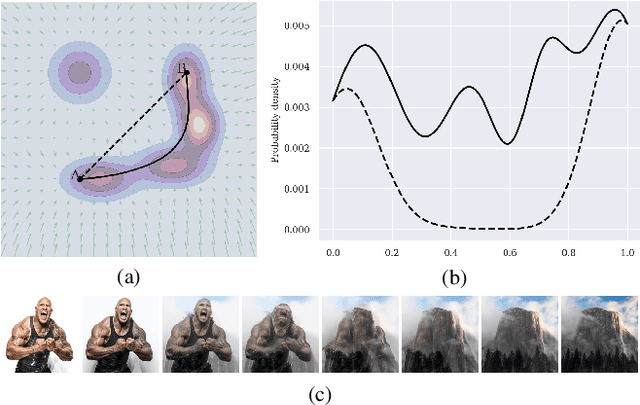
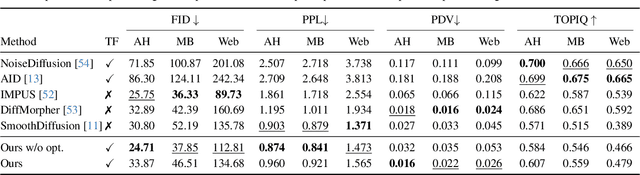
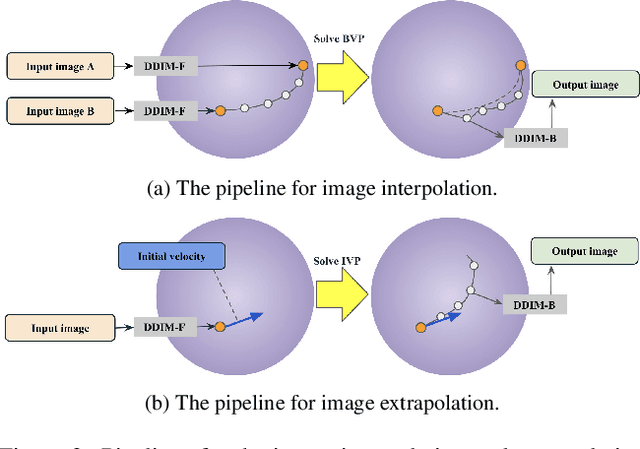
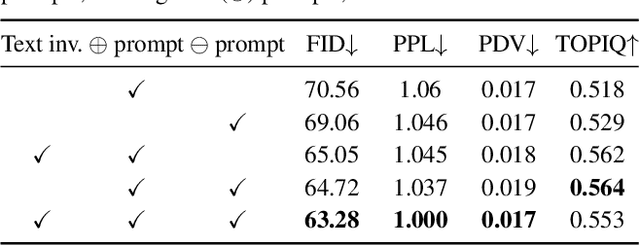
Diffusion models indirectly estimate the probability density over a data space, which can be used to study its structure. In this work, we show that geodesics can be computed in diffusion latent space, where the norm induced by the spatially-varying inner product is inversely proportional to the probability density. In this formulation, a path that traverses a high density (that is, probable) region of image latent space is shorter than the equivalent path through a low density region. We present algorithms for solving the associated initial and boundary value problems and show how to compute the probability density along the path and the geodesic distance between two points. Using these techniques, we analyze how closely video clips approximate geodesics in a pre-trained image diffusion space. Finally, we demonstrate how these techniques can be applied to training-free image sequence interpolation and extrapolation, given a pre-trained image diffusion model.
ProbDiffFlow: An Efficient Learning-Free Framework for Probabilistic Single-Image Optical Flow Estimation
Mar 16, 2025This paper studies optical flow estimation, a critical task in motion analysis with applications in autonomous navigation, action recognition, and film production. Traditional optical flow methods require consecutive frames, which are often unavailable due to limitations in data acquisition or real-world scene disruptions. Thus, single-frame optical flow estimation is emerging in the literature. However, existing single-frame approaches suffer from two major limitations: (1) they rely on labeled training data, making them task-specific, and (2) they produce deterministic predictions, failing to capture motion uncertainty. To overcome these challenges, we propose ProbDiffFlow, a training-free framework that estimates optical flow distributions from a single image. Instead of directly predicting motion, ProbDiffFlow follows an estimation-by-synthesis paradigm: it first generates diverse plausible future frames using a diffusion-based model, then estimates motion from these synthesized samples using a pre-trained optical flow model, and finally aggregates the results into a probabilistic flow distribution. This design eliminates the need for task-specific training while capturing multiple plausible motions. Experiments on both synthetic and real-world datasets demonstrate that ProbDiffFlow achieves superior accuracy, diversity, and efficiency, outperforming existing single-image and two-frame baselines.
Ranked from Within: Ranking Large Multimodal Models for Visual Question Answering Without Labels
Dec 09, 2024



As large multimodal models (LMMs) are increasingly deployed across diverse applications, the need for adaptable, real-world model ranking has become paramount. Traditional evaluation methods are largely dataset-centric, relying on fixed, labeled datasets and supervised metrics, which are resource-intensive and may lack generalizability to novel scenarios, highlighting the importance of unsupervised ranking. In this work, we explore unsupervised model ranking for LMMs by leveraging their uncertainty signals, such as softmax probabilities. We evaluate state-of-the-art LMMs (e.g., LLaVA) across visual question answering benchmarks, analyzing how uncertainty-based metrics can reflect model performance. Our findings show that uncertainty scores derived from softmax distributions provide a robust, consistent basis for ranking models across varied tasks. This finding enables the ranking of LMMs on real-world, unlabeled data for visual question answering, providing a practical approach for selecting models across diverse domains without requiring manual annotation.
SEED4D: A Synthetic Ego--Exo Dynamic 4D Data Generator, Driving Dataset and Benchmark
Dec 01, 2024



Models for egocentric 3D and 4D reconstruction, including few-shot interpolation and extrapolation settings, can benefit from having images from exocentric viewpoints as supervision signals. No existing dataset provides the necessary mixture of complex, dynamic, and multi-view data. To facilitate the development of 3D and 4D reconstruction methods in the autonomous driving context, we propose a Synthetic Ego--Exo Dynamic 4D (SEED4D) data generator and dataset. We present a customizable, easy-to-use data generator for spatio-temporal multi-view data creation. Our open-source data generator allows the creation of synthetic data for camera setups commonly used in the NuScenes, KITTI360, and Waymo datasets. Additionally, SEED4D encompasses two large-scale multi-view synthetic urban scene datasets. Our static (3D) dataset encompasses 212k inward- and outward-facing vehicle images from 2k scenes, while our dynamic (4D) dataset contains 16.8M images from 10k trajectories, each sampled at 100 points in time with egocentric images, exocentric images, and LiDAR data. The datasets and the data generator can be found at https://seed4d.github.io/.
HandCraft: Anatomically Correct Restoration of Malformed Hands in Diffusion Generated Images
Nov 07, 2024



Generative text-to-image models, such as Stable Diffusion, have demonstrated a remarkable ability to generate diverse, high-quality images. However, they are surprisingly inept when it comes to rendering human hands, which are often anatomically incorrect or reside in the "uncanny valley". In this paper, we propose a method HandCraft for restoring such malformed hands. This is achieved by automatically constructing masks and depth images for hands as conditioning signals using a parametric model, allowing a diffusion-based image editor to fix the hand's anatomy and adjust its pose while seamlessly integrating the changes into the original image, preserving pose, color, and style. Our plug-and-play hand restoration solution is compatible with existing pretrained diffusion models, and the restoration process facilitates adoption by eschewing any fine-tuning or training requirements for the diffusion models. We also contribute MalHand datasets that contain generated images with a wide variety of malformed hands in several styles for hand detector training and hand restoration benchmarking, and demonstrate through qualitative and quantitative evaluation that HandCraft not only restores anatomical correctness but also maintains the integrity of the overall image.
Unobserved Object Detection using Generative Models
Oct 08, 2024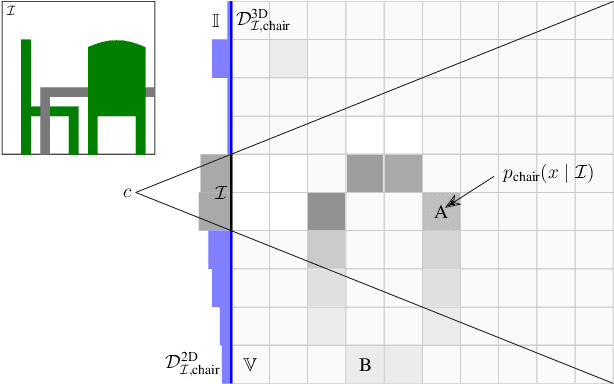
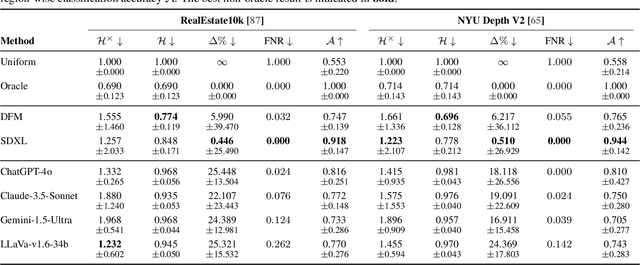
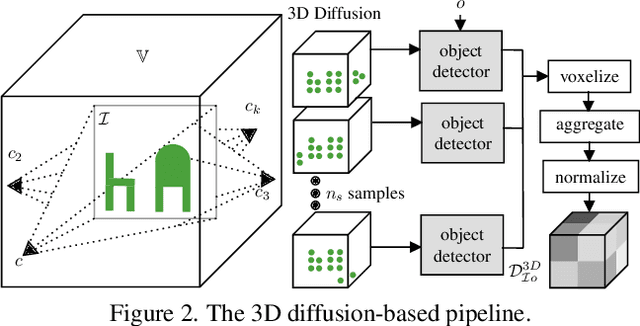
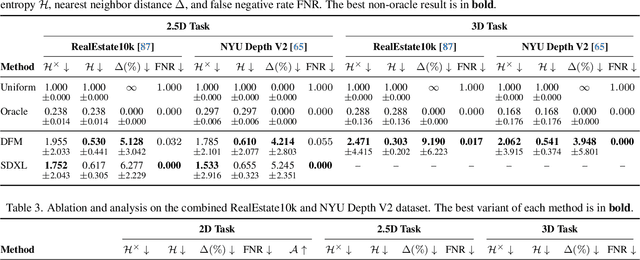
Can we detect an object that is not visible in an image? This study introduces the novel task of 2D and 3D unobserved object detection for predicting the location of objects that are occluded or lie outside the image frame. We adapt several state-of-the-art pre-trained generative models to solve this task, including 2D and 3D diffusion models and vision--language models, and show that they can be used to infer the presence of objects that are not directly observed. To benchmark this task, we propose a suite of metrics that captures different aspects of performance. Our empirical evaluations on indoor scenes from the RealEstate10k dataset with COCO object categories demonstrate results that motivate the use of generative models for the unobserved object detection task. The current work presents a promising step towards compelling applications like visual search and probabilistic planning that can leverage object detection beyond what can be directly observed.
LMOD: A Large Multimodal Ophthalmology Dataset and Benchmark for Large Vision-Language Models
Oct 02, 2024



Ophthalmology relies heavily on detailed image analysis for diagnosis and treatment planning. While large vision-language models (LVLMs) have shown promise in understanding complex visual information, their performance on ophthalmology images remains underexplored. We introduce LMOD, a dataset and benchmark for evaluating LVLMs on ophthalmology images, covering anatomical understanding, diagnostic analysis, and demographic extraction. LMODincludes 21,993 images spanning optical coherence tomography, scanning laser ophthalmoscopy, eye photos, surgical scenes, and color fundus photographs. We benchmark 13 state-of-the-art LVLMs and find that they are far from perfect for comprehending ophthalmology images. Models struggle with diagnostic analysis and demographic extraction, reveal weaknesses in spatial reasoning, diagnostic analysis, handling out-of-domain queries, and safeguards for handling biomarkers of ophthalmology images.