 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Predictive Control for Crowd Navigation via Learning-Based Trajectory Prediction
Aug 09, 2025Safe navigation in pedestrian-rich environments remains a key challenge for autonomous robots. This work evaluates the integration of a deep learning-based Social-Implicit (SI) pedestrian trajectory predictor within a Model Predictive Control (MPC) framework on the physical Continental Corriere robot. Tested across varied pedestrian densities, the SI-MPC system is compared to a traditional Constant Velocity (CV) model in both open-loop prediction and closed-loop navigation. Results show that SI improves trajectory prediction - reducing errors by up to 76% in low-density settings - and enhances safety and motion smoothness in crowded scenes. Moreover, real-world deployment reveals discrepancies between open-loop metrics and closed-loop performance, as the SI model yields broader, more cautious predictions. These findings emphasize the importance of system-level evaluation and highlight the SI-MPC framework's promise for safer, more adaptive navigation in dynamic, human-populated environments.
Generative AI for Autonomous Driving: A Review
May 21, 2025Generative AI (GenAI) is rapidly advancing the field of Autonomous Driving (AD), extending beyond traditional applications in text, image, and video generation. We explore how generative models can enhance automotive tasks, such as static map creation, dynamic scenario generation, trajectory forecasting, and vehicle motion planning. By examining multiple generative approaches ranging from Variational Autoencoder (VAEs) over Generative Adversarial Networks (GANs) and Invertible Neural Networks (INNs) to Generative Transformers (GTs) and Diffusion Models (DMs), we highlight and compare their capabilities and limitations for AD-specific applications. Additionally, we discuss hybrid methods integrating conventional techniques with generative approaches, and emphasize their improved adaptability and robustness. We also identify relevant datasets and outline open research questions to guide future developments in GenAI. Finally, we discuss three core challenges: safety, interpretability, and realtime capabilities, and present recommendations for image generation, dynamic scenario generation, and planning.
sshELF: Single-Shot Hierarchical Extrapolation of Latent Features for 3D Reconstruction from Sparse-Views
Feb 06, 2025



Reconstructing unbounded outdoor scenes from sparse outward-facing views poses significant challenges due to minimal view overlap. Previous methods often lack cross-scene understanding and their primitive-centric formulations overload local features to compensate for missing global context, resulting in blurriness in unseen parts of the scene. We propose sshELF, a fast, single-shot pipeline for sparse-view 3D scene reconstruction via hierarchal extrapolation of latent features. Our key insights is that disentangling information extrapolation from primitive decoding allows efficient transfer of structural patterns across training scenes. Our method: (1) learns cross-scene priors to generate intermediate virtual views to extrapolate to unobserved regions, (2) offers a two-stage network design separating virtual view generation from 3D primitive decoding for efficient training and modular model design, and (3) integrates a pre-trained foundation model for joint inference of latent features and texture, improving scene understanding and generalization. sshELF can reconstruct 360 degree scenes from six sparse input views and achieves competitive results on synthetic and real-world datasets. We find that sshELF faithfully reconstructs occluded regions, supports real-time rendering, and provides rich latent features for downstream applications. The code will be released.
SEED4D: A Synthetic Ego--Exo Dynamic 4D Data Generator, Driving Dataset and Benchmark
Dec 01, 2024



Models for egocentric 3D and 4D reconstruction, including few-shot interpolation and extrapolation settings, can benefit from having images from exocentric viewpoints as supervision signals. No existing dataset provides the necessary mixture of complex, dynamic, and multi-view data. To facilitate the development of 3D and 4D reconstruction methods in the autonomous driving context, we propose a Synthetic Ego--Exo Dynamic 4D (SEED4D) data generator and dataset. We present a customizable, easy-to-use data generator for spatio-temporal multi-view data creation. Our open-source data generator allows the creation of synthetic data for camera setups commonly used in the NuScenes, KITTI360, and Waymo datasets. Additionally, SEED4D encompasses two large-scale multi-view synthetic urban scene datasets. Our static (3D) dataset encompasses 212k inward- and outward-facing vehicle images from 2k scenes, while our dynamic (4D) dataset contains 16.8M images from 10k trajectories, each sampled at 100 points in time with egocentric images, exocentric images, and LiDAR data. The datasets and the data generator can be found at https://seed4d.github.io/.
Learning Approximated Maximal Safe Sets via Hypernetworks for MPC-Based Local Motion Planning
Oct 26, 2024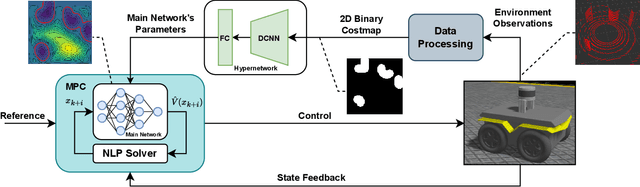
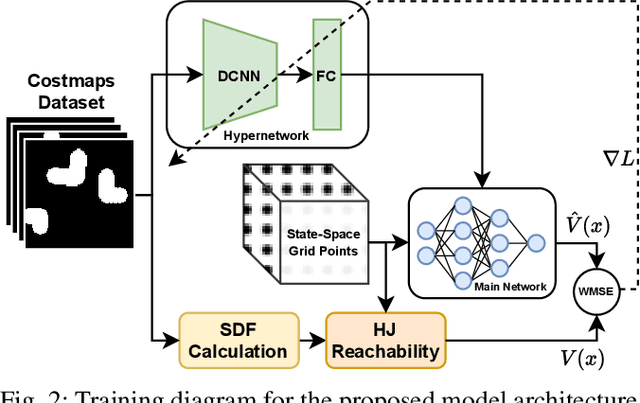
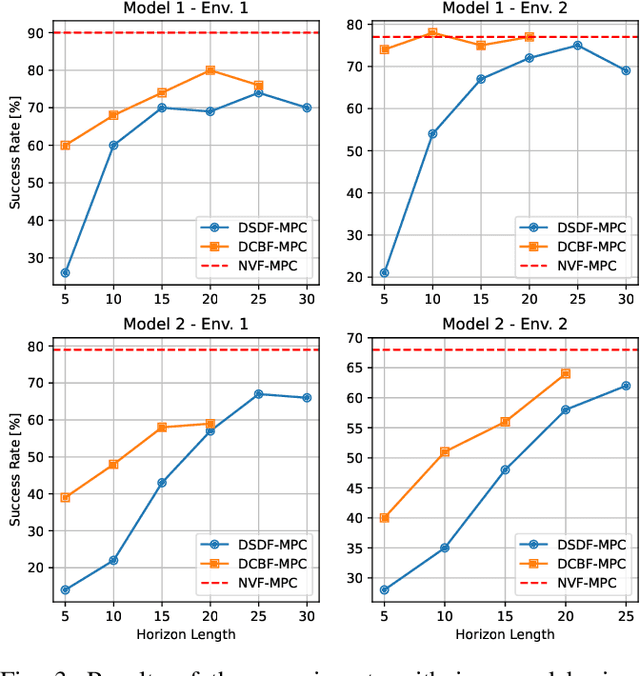
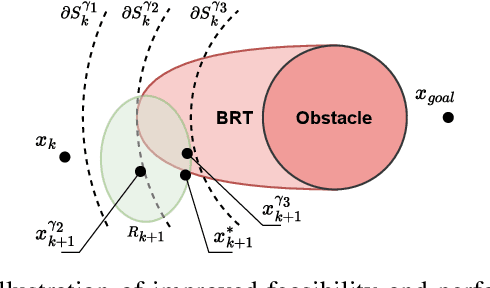
This paper presents a novel learning-based approach for online estimation of maximal safe sets for local motion planning tasks in mobile robotics. We leverage the idea of hypernetworks to achieve good generalization properties and real-time performance simultaneously. As the source of supervision, we employ the Hamilton-Jacobi (HJ) reachability analysis, allowing us to consider general nonlinear dynamics and arbitrary constraints. We integrate our model into a model predictive control (MPC) local planner as a safety constraint and compare the performance with relevant baselines in realistic 3D simulations for different environments and robot dynamics. The results show the advantages of our approach in terms of a significantly higher success rate: 2 to 18 percent over the best baseline, while achieving real-time performance.
6Img-to-3D: Few-Image Large-Scale Outdoor Driving Scene Reconstruction
Apr 18, 2024Current 3D reconstruction techniques struggle to infer unbounded scenes from a few images faithfully. Specifically, existing methods have high computational demands, require detailed pose information, and cannot reconstruct occluded regions reliably. We introduce 6Img-to-3D, an efficient, scalable transformer-based encoder-renderer method for single-shot image to 3D reconstruction. Our method outputs a 3D-consistent parameterized triplane from only six outward-facing input images for large-scale, unbounded outdoor driving scenarios. We take a step towards resolving existing shortcomings by combining contracted custom cross- and self-attention mechanisms for triplane parameterization, differentiable volume rendering, scene contraction, and image feature projection. We showcase that six surround-view vehicle images from a single timestamp without global pose information are enough to reconstruct 360$^{\circ}$ scenes during inference time, taking 395 ms. Our method allows, for example, rendering third-person images and birds-eye views. Our code is available at https://github.com/continental/6Img-to-3D, and more examples can be found at our website here https://6Img-to-3D.GitHub.io/.