 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoWTracker: Tracking by Warping instead of Correlation
Feb 04, 2026Dense point tracking is a fundamental problem in computer vision, with applications ranging from video analysis to robotic manipulation. State-of-the-art trackers typically rely on cost volumes to match features across frames, but this approach incurs quadratic complexity in spatial resolution, limiting scalability and efficiency. In this paper, we propose \method, a novel dense point tracker that eschews cost volumes in favor of warping. Inspired by recent advances in optical flow, our approach iteratively refines track estimates by warping features from the target frame to the query frame based on the current estimate. Combined with a transformer architecture that performs joint spatiotemporal reasoning across all tracks, our design establishes long-range correspondences without computing feature correlations. Our model is simple and achieves state-of-the-art performance on standard dense point tracking benchmarks, including TAP-Vid-DAVIS, TAP-Vid-Kinetics, and Robo-TAP. Remarkably, the model also excels at optical flow, sometimes outperforming specialized methods on the Sintel, KITTI, and Spring benchmarks. These results suggest that warping-based architectures can unify dense point tracking and optical flow estimation.
V-DPM: 4D Video Reconstruction with Dynamic Point Maps
Jan 14, 2026Powerful 3D representations such as DUSt3R invariant point maps, which encode 3D shape and camera parameters, have significantly advanced feed forward 3D reconstruction. While point maps assume static scenes, Dynamic Point Maps (DPMs) extend this concept to dynamic 3D content by additionally representing scene motion. However, existing DPMs are limited to image pairs and, like DUSt3R, require post processing via optimization when more than two views are involved. We argue that DPMs are more useful when applied to videos and introduce V-DPM to demonstrate this. First, we show how to formulate DPMs for video input in a way that maximizes representational power, facilitates neural prediction, and enables reuse of pretrained models. Second, we implement these ideas on top of VGGT, a recent and powerful 3D reconstructor. Although VGGT was trained on static scenes, we show that a modest amount of synthetic data is sufficient to adapt it into an effective V-DPM predictor. Our approach achieves state of the art performance in 3D and 4D reconstruction for dynamic scenes. In particular, unlike recent dynamic extensions of VGGT such as P3, DPMs recover not only dynamic depth but also the full 3D motion of every point in the scene.
Dynamic Point Maps: A Versatile Representation for Dynamic 3D Reconstruction
Mar 20, 2025

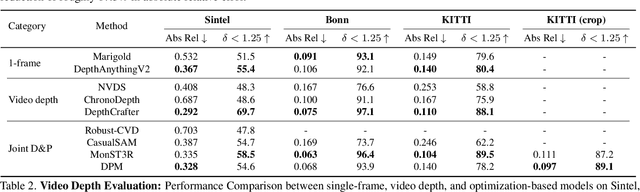

DUSt3R has recently shown that one can reduce many tasks in multi-view geometry, including estimating camera intrinsics and extrinsics, reconstructing the scene in 3D, and establishing image correspondences, to the prediction of a pair of viewpoint-invariant point maps, i.e., pixel-aligned point clouds defined in a common reference frame. This formulation is elegant and powerful, but unable to tackle dynamic scenes. To address this challenge, we introduce the concept of Dynamic Point Maps (DPM), extending standard point maps to support 4D tasks such as motion segmentation, scene flow estimation, 3D object tracking, and 2D correspondence. Our key intuition is that, when time is introduced, there are several possible spatial and time references that can be used to define the point maps. We identify a minimal subset of such combinations that can be regressed by a network to solve the sub tasks mentioned above. We train a DPM predictor on a mixture of synthetic and real data and evaluate it across diverse benchmarks for video depth prediction, dynamic point cloud reconstruction, 3D scene flow and object pose tracking, achieving state-of-the-art performance. Code, models and additional results are available at https://www.robots.ox.ac.uk/~vgg/research/dynamic-point-maps/.
SEED4D: A Synthetic Ego--Exo Dynamic 4D Data Generator, Driving Dataset and Benchmark
Dec 01, 2024



Models for egocentric 3D and 4D reconstruction, including few-shot interpolation and extrapolation settings, can benefit from having images from exocentric viewpoints as supervision signals. No existing dataset provides the necessary mixture of complex, dynamic, and multi-view data. To facilitate the development of 3D and 4D reconstruction methods in the autonomous driving context, we propose a Synthetic Ego--Exo Dynamic 4D (SEED4D) data generator and dataset. We present a customizable, easy-to-use data generator for spatio-temporal multi-view data creation. Our open-source data generator allows the creation of synthetic data for camera setups commonly used in the NuScenes, KITTI360, and Waymo datasets. Additionally, SEED4D encompasses two large-scale multi-view synthetic urban scene datasets. Our static (3D) dataset encompasses 212k inward- and outward-facing vehicle images from 2k scenes, while our dynamic (4D) dataset contains 16.8M images from 10k trajectories, each sampled at 100 points in time with egocentric images, exocentric images, and LiDAR data. The datasets and the data generator can be found at https://seed4d.github.io/.
Flash3D: Feed-Forward Generalisable 3D Scene Reconstruction from a Single Image
Jun 06, 2024In this paper, we propose Flash3D, a method for scene reconstruction and novel view synthesis from a single image which is both very generalisable and efficient. For generalisability, we start from a "foundation" model for monocular depth estimation and extend it to a full 3D shape and appearance reconstructor. For efficiency, we base this extension on feed-forward Gaussian Splatting. Specifically, we predict a first layer of 3D Gaussians at the predicted depth, and then add additional layers of Gaussians that are offset in space, allowing the model to complete the reconstruction behind occlusions and truncations. Flash3D is very efficient, trainable on a single GPU in a day, and thus accessible to most researchers. It achieves state-of-the-art results when trained and tested on RealEstate10k. When transferred to unseen datasets like NYU it outperforms competitors by a large margin. More impressively, when transferred to KITTI, Flash3D achieves better PSNR than methods trained specifically on that dataset. In some instances, it even outperforms recent methods that use multiple views as input. Code, models, demo, and more results are available at https://www.robots.ox.ac.uk/~vgg/research/flash3d/.
SNeS: Learning Probably Symmetric Neural Surfaces from Incomplete Data
Jun 13, 2022
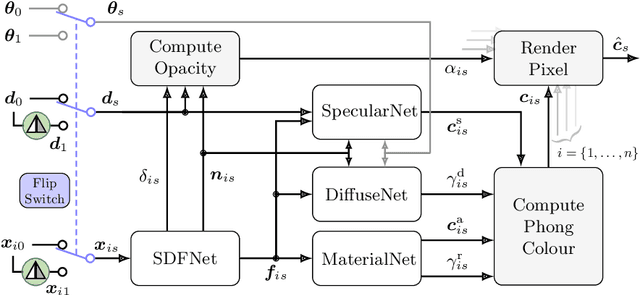
We present a method for the accurate 3D reconstruction of partly-symmetric objects. We build on the strengths of recent advances in neural reconstruction and rendering such as Neural Radiance Fields (NeRF). A major shortcoming of such approaches is that they fail to reconstruct any part of the object which is not clearly visible in the training image, which is often the case for in-the-wild images and videos. When evidence is lacking, structural priors such as symmetry can be used to complete the missing information. However, exploiting such priors in neural rendering is highly non-trivial: while geometry and non-reflective materials may be symmetric, shadows and reflections from the ambient scene are not symmetric in general. To address this, we apply a soft symmetry constraint to the 3D geometry and material properties, having factored appearance into lighting, albedo colour and reflectivity. We evaluate our method on the recently introduced CO3D dataset, focusing on the car category due to the challenge of reconstructing highly-reflective materials. We show that it can reconstruct unobserved regions with high fidelity and render high-quality novel view images.
Lifting 2D Object Locations to 3D by Discounting LiDAR Outliers across Objects and Views
Oct 09, 2021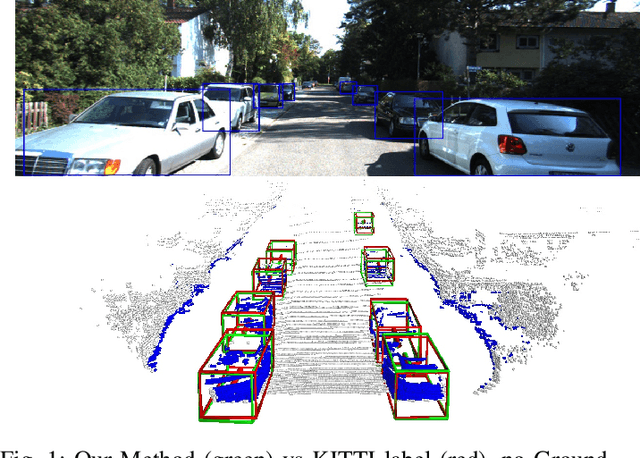
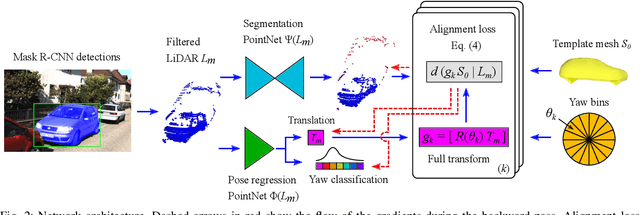


We present a system for automatic converting of 2D mask object predictions and raw LiDAR point clouds into full 3D bounding boxes of objects. Because the LiDAR point clouds are partial, directly fitting bounding boxes to the point clouds is meaningless. Instead, we suggest that obtaining good results requires sharing information between \emph{all} objects in the dataset jointly, over multiple frames. We then make three improvements to the baseline. First, we address ambiguities in predicting the object rotations via direct optimization in this space while still backpropagating rotation prediction through the model. Second, we explicitly model outliers and task the network with learning their typical patterns, thus better discounting them. Third, we enforce temporal consistency when video data is available. With these contributions, our method significantly outperforms previous work despite the fact that those methods use significantly more complex pipelines, 3D models and additional human-annotated external sources of prior information.
360-Degree Textures of People in Clothing from a Single Image
Aug 20, 2019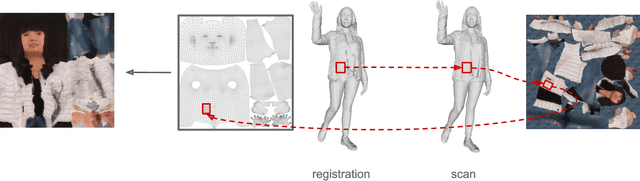

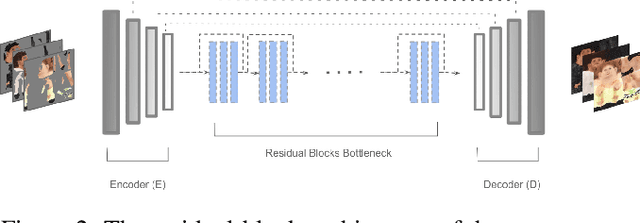
In this paper we predict a full 3D avatar of a person from a single image. We infer texture and geometry in the UV-space of the SMPL model using an image-to-image translation method. Given partial texture and segmentation layout maps derived from the input view, our model predicts the complete segmentation map, the complete texture map, and a displacement map. The predicted maps can be applied to the SMPL model in order to naturally generalize to novel poses, shapes, and even new clothing. In order to learn our model in a common UV-space, we non-rigidly register the SMPL model to thousands of 3D scans, effectively encoding textures and geometries as images in correspondence. This turns a difficult 3D inference task into a simpler image-to-image translation one. Results on rendered scans of people and images from the DeepFashion dataset demonstrate that our method can reconstruct plausible 3D avatars from a single image. We further use our model to digitally change pose, shape, swap garments between people and edit clothing. To encourage research in this direction we will make the source code available for research purpose.
Unsupervised Learning of Shape and Pose with Differentiable Point Clouds
Oct 22, 2018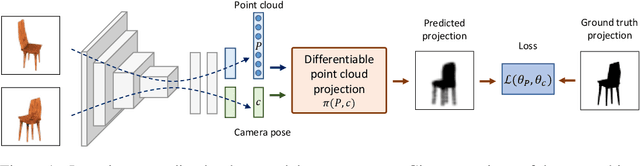

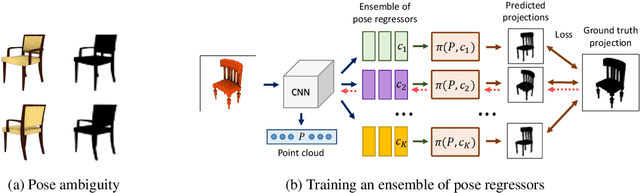
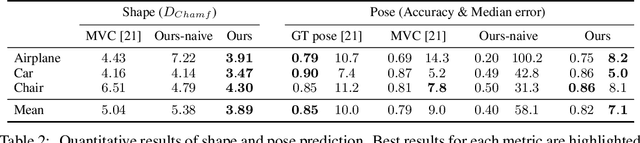
We address the problem of learning accurate 3D shape and camera pose from a collection of unlabeled category-specific images. We train a convolutional network to predict both the shape and the pose from a single image by minimizing the reprojection error: given several views of an object, the projections of the predicted shapes to the predicted camera poses should match the provided views. To deal with pose ambiguity, we introduce an ensemble of pose predictors which we then distill to a single "student" model. To allow for efficient learning of high-fidelity shapes, we represent the shapes by point clouds and devise a formulation allowing for differentiable projection of these. Our experiments show that the distilled ensemble of pose predictors learns to estimate the pose accurately, while the point cloud representation allows to predict detailed shape models. The supplementary video can be found at https://www.youtube.com/watch?v=LuIGovKeo60
PoseTrack: A Benchmark for Human Pose Estimation and Tracking
Apr 10, 2018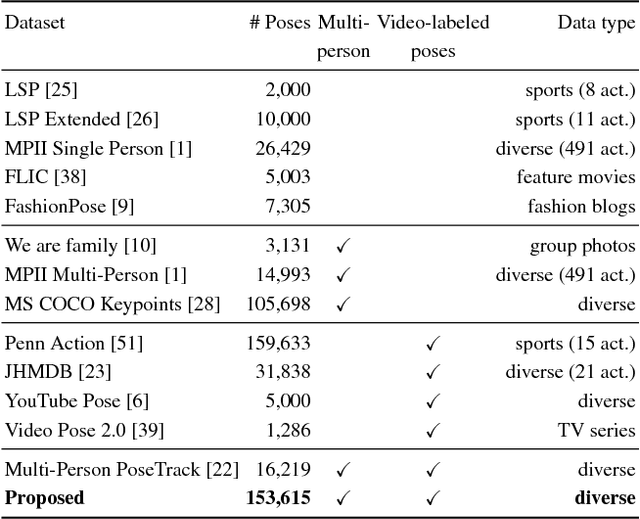


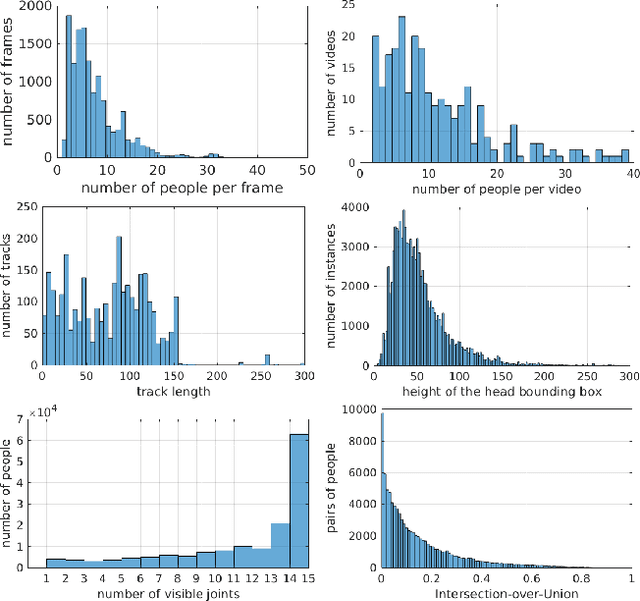
Human poses and motions are important cues for analysis of videos with people and there is strong evidence that representations based on body pose are highly effective for a variety of tasks such as activity recognition, content retrieval and social signal processing. In this work, we aim to further advance the state of the art by establishing "PoseTrack", a new large-scale benchmark for video-based human pose estimation and articulated tracking, and bringing together the community of researchers working on visual human analysis. The benchmark encompasses three competition tracks focusing on i) single-frame multi-person pose estimation, ii) multi-person pose estimation in videos, and iii) multi-person articulated tracking. To facilitate the benchmark and challenge we collect, annotate and release a new %large-scale benchmark dataset that features videos with multiple people labeled with person tracks and articulated pose. A centralized evaluation server is provided to allow participants to evaluate on a held-out test set. We envision that the proposed benchmark will stimulate productive research both by providing a large and representative training dataset as well as providing a platform to objectively evaluate and compare the proposed methods. The benchmark is freely accessible at https://posetrack.net.