 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving In-Context Learning with Small Language Model Ensembles
Oct 29, 2024Large language models (LLMs) have shown impressive capabilities across various tasks, but their performance on domain-specific tasks remains limited. While methods like retrieval augmented generation and fine-tuning can help to address this, they require significant resources. In-context learning (ICL) is a cheap and efficient alternative but cannot match the accuracies of advanced methods. We present Ensemble SuperICL, a novel approach that enhances ICL by leveraging the expertise of multiple fine-tuned small language models (SLMs). Ensemble SuperICL achieves state of the art (SoTA) results on several natural language understanding benchmarks. Additionally, we test it on a medical-domain labelling task and showcase its practicality by using off-the-shelf SLMs fine-tuned on a general language task, achieving superior accuracy in large-scale data labelling compared to all baselines. Finally, we conduct an ablation study and sensitivity analyses to elucidate the underlying mechanism of Ensemble SuperICL. Our research contributes to the growing demand for efficient domain specialisation methods in LLMs, offering a cheap and effective method for practitioners.
Fine-tuning Large Language Models with Human-inspired Learning Strategies in Medical Question Answering
Aug 15, 2024



Training Large Language Models (LLMs) incurs substantial data-related costs, motivating the development of data-efficient training methods through optimised data ordering and selection. Human-inspired learning strategies, such as curriculum learning, offer possibilities for efficient training by organising data according to common human learning practices. Despite evidence that fine-tuning with curriculum learning improves the performance of LLMs for natural language understanding tasks, its effectiveness is typically assessed using a single model. In this work, we extend previous research by evaluating both curriculum-based and non-curriculum-based learning strategies across multiple LLMs, using human-defined and automated data labels for medical question answering. Our results indicate a moderate impact of using human-inspired learning strategies for fine-tuning LLMs, with maximum accuracy gains of 1.77% per model and 1.81% per dataset. Crucially, we demonstrate that the effectiveness of these strategies varies significantly across different model-dataset combinations, emphasising that the benefits of a specific human-inspired strategy for fine-tuning LLMs do not generalise. Additionally, we find evidence that curriculum learning using LLM-defined question difficulty outperforms human-defined difficulty, highlighting the potential of using model-generated measures for optimal curriculum design.
Exploring the Landscape of Large Language Models In Medical Question Answering: Observations and Open Questions
Oct 11, 2023Large Language Models (LLMs) have shown promise in medical question answering by achieving passing scores in standardised exams and have been suggested as tools for supporting healthcare workers. Deploying LLMs into such a high-risk context requires a clear understanding of the limitations of these models. With the rapid development and release of new LLMs, it is especially valuable to identify patterns which exist across models and may, therefore, continue to appear in newer versions. In this paper, we evaluate a wide range of popular LLMs on their knowledge of medical questions in order to better understand their properties as a group. From this comparison, we provide preliminary observations and raise open questions for further research.
Lifting 2D Object Locations to 3D by Discounting LiDAR Outliers across Objects and Views
Oct 09, 2021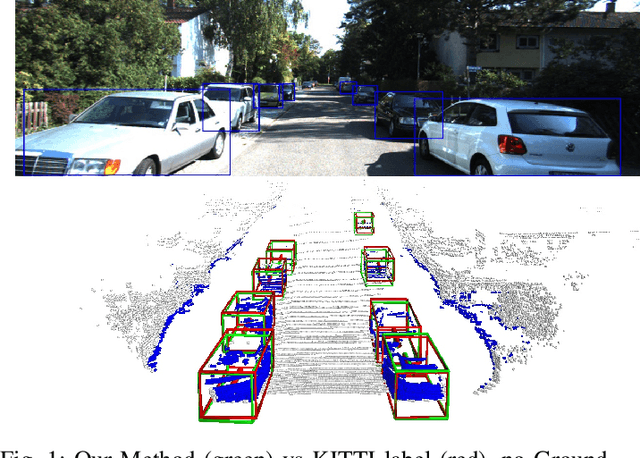
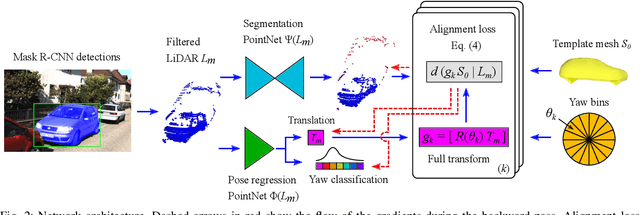


We present a system for automatic converting of 2D mask object predictions and raw LiDAR point clouds into full 3D bounding boxes of objects. Because the LiDAR point clouds are partial, directly fitting bounding boxes to the point clouds is meaningless. Instead, we suggest that obtaining good results requires sharing information between \emph{all} objects in the dataset jointly, over multiple frames. We then make three improvements to the baseline. First, we address ambiguities in predicting the object rotations via direct optimization in this space while still backpropagating rotation prediction through the model. Second, we explicitly model outliers and task the network with learning their typical patterns, thus better discounting them. Third, we enforce temporal consistency when video data is available. With these contributions, our method significantly outperforms previous work despite the fact that those methods use significantly more complex pipelines, 3D models and additional human-annotated external sources of prior information.
Real Time Monocular Vehicle Velocity Estimation using Synthetic Data
Sep 16, 2021


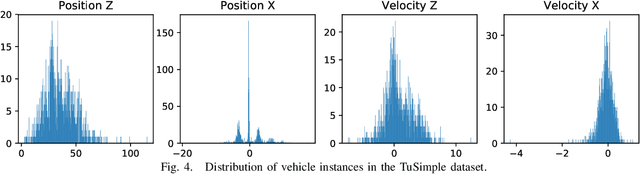
Vision is one of the primary sensing modalities in autonomous driving. In this paper we look at the problem of estimating the velocity of road vehicles from a camera mounted on a moving car. Contrary to prior methods that train end-to-end deep networks that estimate the vehicles' velocity from the video pixels, we propose a two-step approach where first an off-the-shelf tracker is used to extract vehicle bounding boxes and then a small neural network is used to regress the vehicle velocity from the tracked bounding boxes. Surprisingly, we find that this still achieves state-of-the-art estimation performance with the significant benefit of separating perception from dynamics estimation via a clean, interpretable and verifiable interface which allows us distill the statistics which are crucial for velocity estimation. We show that the latter can be used to easily generate synthetic training data in the space of bounding boxes and use this to improve the performance of our method further.
Calibrating Self-supervised Monocular Depth Estimation
Sep 16, 2020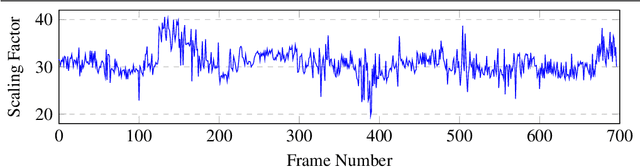

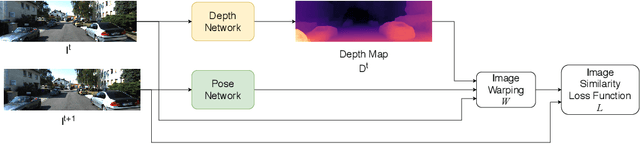
In the recent years, many methods demonstrated the ability of neural networks tolearn depth and pose changes in a sequence of images, using only self-supervision as thetraining signal. Whilst the networks achieve good performance, the often over-lookeddetail is that due to the inherent ambiguity of monocular vision they predict depth up to aunknown scaling factor. The scaling factor is then typically obtained from the LiDARground truth at test time, which severely limits practical applications of these methods.In this paper, we show that incorporating prior information about the camera configu-ration and the environment, we can remove the scale ambiguity and predict depth directly,still using the self-supervised formulation and not relying on any additional sensors.
Monocular Depth Estimation with Self-supervised Instance Adaptation
Apr 13, 2020
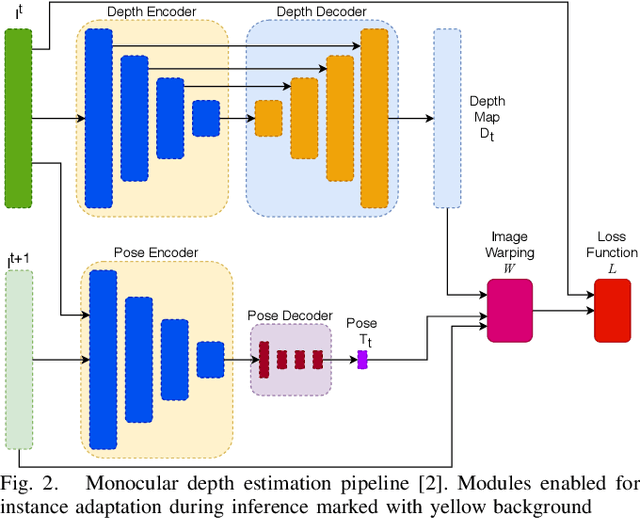
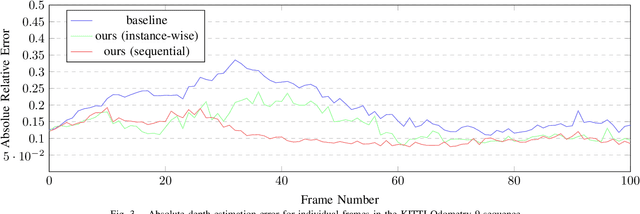
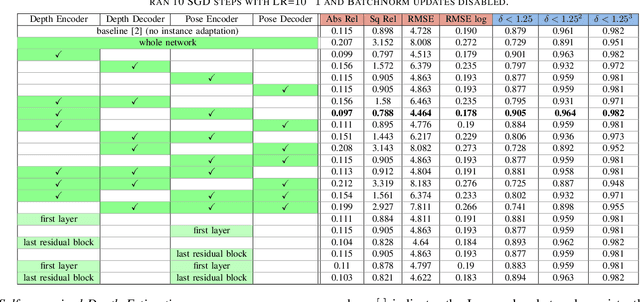
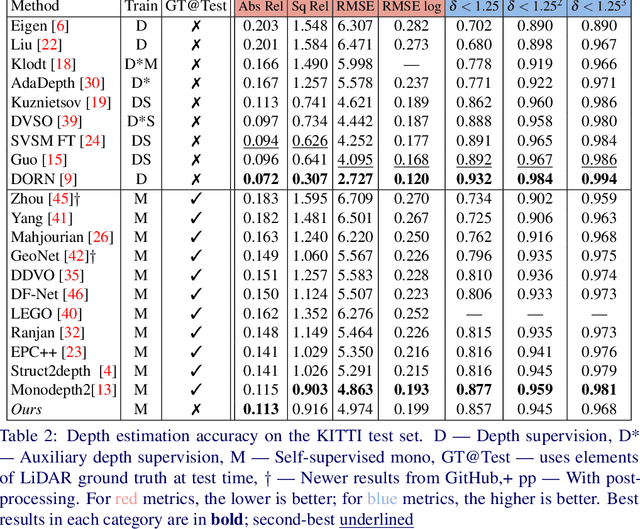
Recent advances in self-supervised learning havedemonstrated that it is possible to learn accurate monoculardepth reconstruction from raw video data, without using any 3Dground truth for supervision. However, in robotics applications,multiple views of a scene may or may not be available, depend-ing on the actions of the robot, switching between monocularand multi-view reconstruction. To address this mixed setting,we proposed a new approach that extends any off-the-shelfself-supervised monocular depth reconstruction system to usemore than one image at test time. Our method builds on astandard prior learned to perform monocular reconstruction,but uses self-supervision at test time to further improve thereconstruction accuracy when multiple images are available.When used to update the correct components of the model, thisapproach is highly-effective. On the standard KITTI bench-mark, our self-supervised method consistently outperformsall the previous methods with an average 25% reduction inabsolute error for the three common setups (monocular, stereoand monocular+stereo), and comes very close in accuracy whencompared to the fully-supervised state-of-the-art methods.
State-of-Art-Reviewing: A Radical Proposal to Improve Scientific Publication
Mar 31, 2020


Peer review forms the backbone of modern scientific manuscript evaluation. But after two hundred and eighty-nine years of egalitarian service to the scientific community, does this protocol remain fit for purpose in 2020? In this work, we answer this question in the negative (strong reject, high confidence) and propose instead State-Of-the-Art Review (SOAR), a neoteric reviewing pipeline that serves as a 'plug-and-play' replacement for peer review. At the heart of our approach is an interpretation of the review process as a multi-objective, massively distributed and extremely-high-latency optimisation, which we scalarise and solve efficiently for PAC and CMT-optimal solutions. We make the following contributions: (1) We propose a highly scalable, fully automatic methodology for review, drawing inspiration from best-practices from premier computer vision and machine learning conferences; (2) We explore several instantiations of our approach and demonstrate that SOAR can be used to both review prints and pre-review pre-prints; (3) We wander listlessly in vain search of catharsis from our latest rounds of savage CVPR rejections.