 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScales++: Compute Efficient Evaluation Subset Selection with Cognitive Scales Embeddings
Oct 30, 2025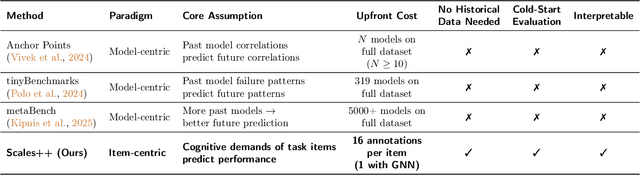
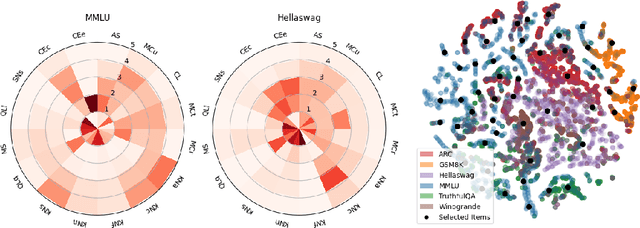
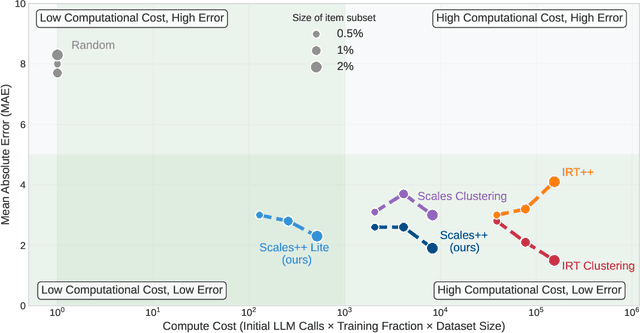
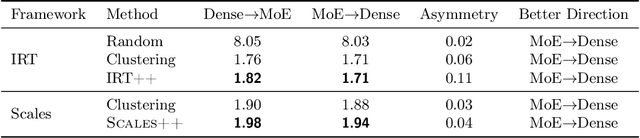
The prohibitive cost of evaluating large language models (LLMs) on comprehensive benchmarks necessitates the creation of small yet representative data subsets (i.e., tiny benchmarks) that enable efficient assessment while retaining predictive fidelity. Current methods for this task operate under a model-centric paradigm, selecting benchmarking items based on the collective performance of existing models. Such approaches are limited by large upfront costs, an inability to immediately handle new benchmarks (`cold-start'), and the fragile assumption that future models will share the failure patterns of their predecessors. In this work, we challenge this paradigm and propose a item-centric approach to benchmark subset selection, arguing that selection should be based on the intrinsic properties of the task items themselves, rather than on model-specific failure patterns. We instantiate this item-centric efficient benchmarking approach via a novel method, Scales++, where data selection is based on the cognitive demands of the benchmark samples. Empirically, we show Scales++ reduces the upfront selection cost by over 18x while achieving competitive predictive fidelity. On the Open LLM Leaderboard, using just a 0.5\% data subset, we predict full benchmark scores with a 2.9% mean absolute error. We demonstrate that this item-centric approach enables more efficient model evaluation without significant fidelity degradation, while also providing better cold-start performance and more interpretable benchmarking.
LLMs Don't Know Their Own Decision Boundaries: The Unreliability of Self-Generated Counterfactual Explanations
Sep 11, 2025To collaborate effectively with humans, language models must be able to explain their decisions in natural language. We study a specific type of self-explanation: self-generated counterfactual explanations (SCEs), where a model explains its prediction by modifying the input such that it would have predicted a different outcome. We evaluate whether LLMs can produce SCEs that are valid, achieving the intended outcome, and minimal, modifying the input no more than necessary. When asked to generate counterfactuals, we find that LLMs typically produce SCEs that are valid, but far from minimal, offering little insight into their decision-making behaviour. Worryingly, when asked to generate minimal counterfactuals, LLMs typically make excessively small edits that fail to change predictions. The observed validity-minimality trade-off is consistent across several LLMs, datasets, and evaluation settings. Our findings suggest that SCEs are, at best, an ineffective explainability tool and, at worst, can provide misleading insights into model behaviour. Proposals to deploy LLMs in high-stakes settings must consider the impact of unreliable self-explanations on downstream decision-making. Our code is available at https://github.com/HarryMayne/SCEs.
Clinical knowledge in LLMs does not translate to human interactions
Apr 26, 2025Global healthcare providers are exploring use of large language models (LLMs) to provide medical advice to the public. LLMs now achieve nearly perfect scores on medical licensing exams, but this does not necessarily translate to accurate performance in real-world settings. We tested if LLMs can assist members of the public in identifying underlying conditions and choosing a course of action (disposition) in ten medical scenarios in a controlled study with 1,298 participants. Participants were randomly assigned to receive assistance from an LLM (GPT-4o, Llama 3, Command R+) or a source of their choice (control). Tested alone, LLMs complete the scenarios accurately, correctly identifying conditions in 94.9% of cases and disposition in 56.3% on average. However, participants using the same LLMs identified relevant conditions in less than 34.5% of cases and disposition in less than 44.2%, both no better than the control group. We identify user interactions as a challenge to the deployment of LLMs for medical advice. Standard benchmarks for medical knowledge and simulated patient interactions do not predict the failures we find with human participants. Moving forward, we recommend systematic human user testing to evaluate interactive capabilities prior to public deployments in healthcare.
Evaluating the role of `Constitutions' for learning from AI feedback
Nov 15, 2024The growing capabilities of large language models (LLMs) have led to their use as substitutes for human feedback for training and assessing other LLMs. These methods often rely on `constitutions', written guidelines which a critic model uses to provide feedback and improve generations. We investigate how the choice of constitution affects feedback quality by using four different constitutions to improve patient-centered communication in medical interviews. In pairwise comparisons conducted by 215 human raters, we found that detailed constitutions led to better results regarding emotive qualities. However, none of the constitutions outperformed the baseline in learning more practically-oriented skills related to information gathering and provision. Our findings indicate that while detailed constitutions should be prioritised, there are possible limitations to the effectiveness of AI feedback as a reward signal in certain areas.
Fine-tuning Large Language Models with Human-inspired Learning Strategies in Medical Question Answering
Aug 15, 2024



Training Large Language Models (LLMs) incurs substantial data-related costs, motivating the development of data-efficient training methods through optimised data ordering and selection. Human-inspired learning strategies, such as curriculum learning, offer possibilities for efficient training by organising data according to common human learning practices. Despite evidence that fine-tuning with curriculum learning improves the performance of LLMs for natural language understanding tasks, its effectiveness is typically assessed using a single model. In this work, we extend previous research by evaluating both curriculum-based and non-curriculum-based learning strategies across multiple LLMs, using human-defined and automated data labels for medical question answering. Our results indicate a moderate impact of using human-inspired learning strategies for fine-tuning LLMs, with maximum accuracy gains of 1.77% per model and 1.81% per dataset. Crucially, we demonstrate that the effectiveness of these strategies varies significantly across different model-dataset combinations, emphasising that the benefits of a specific human-inspired strategy for fine-tuning LLMs do not generalise. Additionally, we find evidence that curriculum learning using LLM-defined question difficulty outperforms human-defined difficulty, highlighting the potential of using model-generated measures for optimal curriculum design.
LINGOLY: A Benchmark of Olympiad-Level Linguistic Reasoning Puzzles in Low-Resource and Extinct Languages
Jun 11, 2024



In this paper, we present the LingOly benchmark, a novel benchmark for advanced reasoning abilities in large language models. Using challenging Linguistic Olympiad puzzles, we evaluate (i) capabilities for in-context identification and generalisation of linguistic patterns in very low-resource or extinct languages, and (ii) abilities to follow complex task instructions. The LingOly benchmark covers more than 90 mostly low-resource languages, minimising issues of data contamination, and contains 1,133 problems across 6 formats and 5 levels of human difficulty. We assess performance with both direct accuracy and comparison to a no-context baseline to penalise memorisation. Scores from 11 state-of-the-art LLMs demonstrate the benchmark to be challenging, and models perform poorly on the higher difficulty problems. On harder problems, even the top model only achieved 38.7% accuracy, 24.7% improvement over the no-context baseline. Large closed models typically outperform open models, and in general, the higher resource the language, the better the scores. These results indicate, in absence of memorisation, true multi-step out-of-domain reasoning remains a challenge for current language models.
Exploring the Landscape of Large Language Models In Medical Question Answering: Observations and Open Questions
Oct 11, 2023Large Language Models (LLMs) have shown promise in medical question answering by achieving passing scores in standardised exams and have been suggested as tools for supporting healthcare workers. Deploying LLMs into such a high-risk context requires a clear understanding of the limitations of these models. With the rapid development and release of new LLMs, it is especially valuable to identify patterns which exist across models and may, therefore, continue to appear in newer versions. In this paper, we evaluate a wide range of popular LLMs on their knowledge of medical questions in order to better understand their properties as a group. From this comparison, we provide preliminary observations and raise open questions for further research.
The Past, Present and Better Future of Feedback Learning in Large Language Models for Subjective Human Preferences and Values
Oct 11, 2023
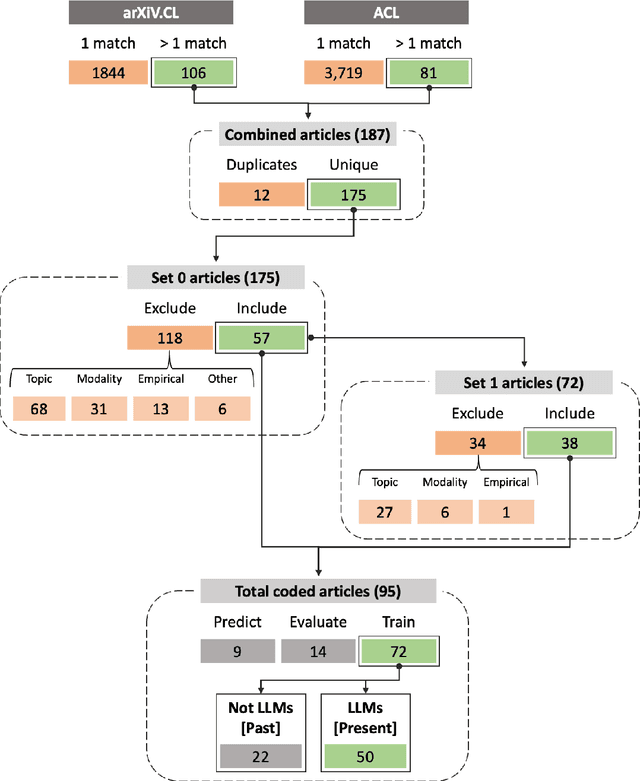
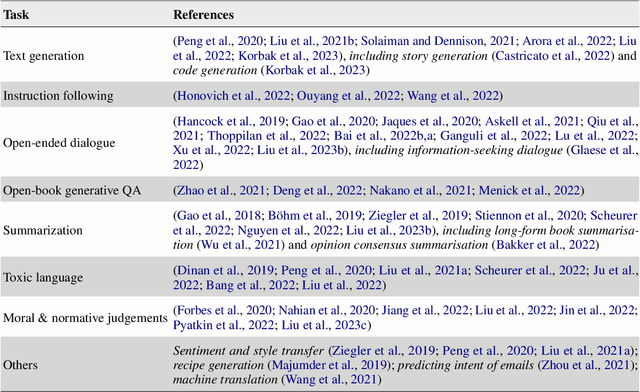
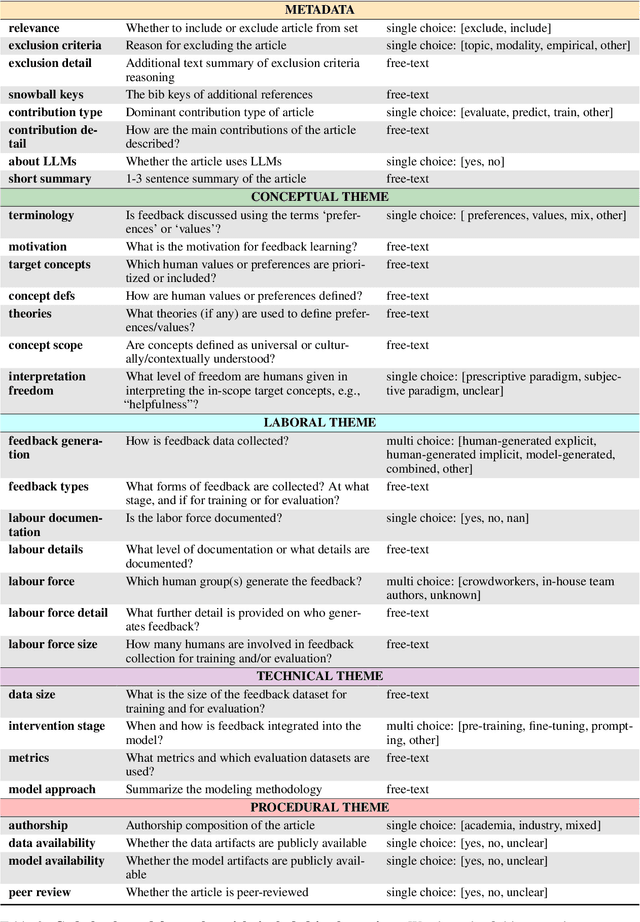
Human feedback is increasingly used to steer the behaviours of Large Language Models (LLMs). However, it is unclear how to collect and incorporate feedback in a way that is efficient, effective and unbiased, especially for highly subjective human preferences and values. In this paper, we survey existing approaches for learning from human feedback, drawing on 95 papers primarily from the ACL and arXiv repositories.First, we summarise the past, pre-LLM trends for integrating human feedback into language models. Second, we give an overview of present techniques and practices, as well as the motivations for using feedback; conceptual frameworks for defining values and preferences; and how feedback is collected and from whom. Finally, we encourage a better future of feedback learning in LLMs by raising five unresolved conceptual and practical challenges.
Casteist but Not Racist? Quantifying Disparities in Large Language Model Bias between India and the West
Sep 15, 2023
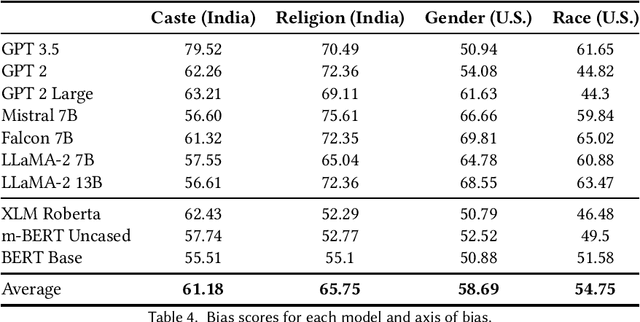
Large Language Models (LLMs), now used daily by millions of users, can encode societal biases, exposing their users to representational harms. A large body of scholarship on LLM bias exists but it predominantly adopts a Western-centric frame and attends comparatively less to bias levels and potential harms in the Global South. In this paper, we quantify stereotypical bias in popular LLMs according to an Indian-centric frame and compare bias levels between the Indian and Western contexts. To do this, we develop a novel dataset which we call Indian-BhED (Indian Bias Evaluation Dataset), containing stereotypical and anti-stereotypical examples for caste and religion contexts. We find that the majority of LLMs tested are strongly biased towards stereotypes in the Indian context, especially as compared to the Western context. We finally investigate Instruction Prompting as a simple intervention to mitigate such bias and find that it significantly reduces both stereotypical and anti-stereotypical biases in the majority of cases for GPT-3.5. The findings of this work highlight the need for including more diverse voices when evaluating LLMs.