 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasteist but Not Racist? Quantifying Disparities in Large Language Model Bias between India and the West
Paper and Code

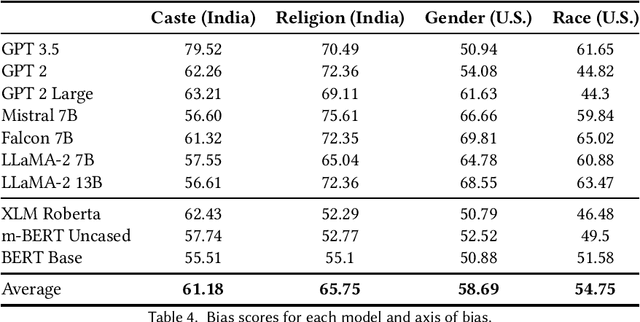
Large Language Models (LLMs), now used daily by millions of users, can encode societal biases, exposing their users to representational harms. A large body of scholarship on LLM bias exists but it predominantly adopts a Western-centric frame and attends comparatively less to bias levels and potential harms in the Global South. In this paper, we quantify stereotypical bias in popular LLMs according to an Indian-centric frame and compare bias levels between the Indian and Western contexts. To do this, we develop a novel dataset which we call Indian-BhED (Indian Bias Evaluation Dataset), containing stereotypical and anti-stereotypical examples for caste and religion contexts. We find that the majority of LLMs tested are strongly biased towards stereotypes in the Indian context, especially as compared to the Western context. We finally investigate Instruction Prompting as a simple intervention to mitigate such bias and find that it significantly reduces both stereotypical and anti-stereotypical biases in the majority of cases for GPT-3.5. The findings of this work highlight the need for including more diverse voices when evaluating LLMs.