 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Models Inherit Value Biases from Pretraining
Jan 28, 2026Reward models (RMs) are central to aligning large language models (LLMs) with human values but have received less attention than pre-trained and post-trained LLMs themselves. Because RMs are initialized from LLMs, they inherit representations that shape their behavior, but the nature and extent of this influence remain understudied. In a comprehensive study of 10 leading open-weight RMs using validated psycholinguistic corpora, we show that RMs exhibit significant differences along multiple dimensions of human value as a function of their base model. Using the "Big Two" psychological axes, we show a robust preference of Llama RMs for "agency" and a corresponding robust preference of Gemma RMs for "communion." This phenomenon holds even when the preference data and finetuning process are identical, and we trace it back to the logits of the respective instruction-tuned and pre-trained models. These log-probability differences themselves can be formulated as an implicit RM; we derive usable implicit reward scores and show that they exhibit the very same agency/communion difference. We run experiments training RMs with ablations for preference data source and quantity, which demonstrate that this effect is not only repeatable but surprisingly durable. Despite RMs being designed to represent human preferences, our evidence shows that their outputs are influenced by the pretrained LLMs on which they are based. This work underscores the importance of safety and alignment efforts at the pretraining stage, and makes clear that open-source developers' choice of base model is as much a consideration of values as of performance.
Reward Model Interpretability via Optimal and Pessimal Tokens
Jun 08, 2025



Reward modeling has emerged as a crucial component in aligning large language models with human values. Significant attention has focused on using reward models as a means for fine-tuning generative models. However, the reward models themselves -- which directly encode human value judgments by turning prompt-response pairs into scalar rewards -- remain relatively understudied. We present a novel approach to reward model interpretability through exhaustive analysis of their responses across their entire vocabulary space. By examining how different reward models score every possible single-token response to value-laden prompts, we uncover several striking findings: (i) substantial heterogeneity between models trained on similar objectives, (ii) systematic asymmetries in how models encode high- vs low-scoring tokens, (iii) significant sensitivity to prompt framing that mirrors human cognitive biases, and (iv) overvaluation of more frequent tokens. We demonstrate these effects across ten recent open-source reward models of varying parameter counts and architectures. Our results challenge assumptions about the interchangeability of reward models, as well as their suitability as proxies of complex and context-dependent human values. We find that these models can encode concerning biases toward certain identity groups, which may emerge as unintended consequences of harmlessness training -- distortions that risk propagating through the downstream large language models now deployed to millions.
Clinical knowledge in LLMs does not translate to human interactions
Apr 26, 2025Global healthcare providers are exploring use of large language models (LLMs) to provide medical advice to the public. LLMs now achieve nearly perfect scores on medical licensing exams, but this does not necessarily translate to accurate performance in real-world settings. We tested if LLMs can assist members of the public in identifying underlying conditions and choosing a course of action (disposition) in ten medical scenarios in a controlled study with 1,298 participants. Participants were randomly assigned to receive assistance from an LLM (GPT-4o, Llama 3, Command R+) or a source of their choice (control). Tested alone, LLMs complete the scenarios accurately, correctly identifying conditions in 94.9% of cases and disposition in 56.3% on average. However, participants using the same LLMs identified relevant conditions in less than 34.5% of cases and disposition in less than 44.2%, both no better than the control group. We identify user interactions as a challenge to the deployment of LLMs for medical advice. Standard benchmarks for medical knowledge and simulated patient interactions do not predict the failures we find with human participants. Moving forward, we recommend systematic human user testing to evaluate interactive capabilities prior to public deployments in healthcare.
Multilingual != Multicultural: Evaluating Gaps Between Multilingual Capabilities and Cultural Alignment in LLMs
Feb 23, 2025Large Language Models (LLMs) are becoming increasingly capable across global languages. However, the ability to communicate across languages does not necessarily translate to appropriate cultural representations. A key concern is US-centric bias, where LLMs reflect US rather than local cultural values. We propose a novel methodology that compares LLM-generated response distributions against population-level opinion data from the World Value Survey across four languages (Danish, Dutch, English, and Portuguese). Using a rigorous linear mixed-effects regression framework, we compare two families of models: Google's Gemma models (2B--27B parameters) and successive iterations of OpenAI's turbo-series. Across the families of models, we find no consistent relationships between language capabilities and cultural alignment. While the Gemma models have a positive correlation between language capability and cultural alignment across languages, the OpenAI models do not. Importantly, we find that self-consistency is a stronger predictor of multicultural alignment than multilingual capabilities. Our results demonstrate that achieving meaningful cultural alignment requires dedicated effort beyond improving general language capabilities.
Why human-AI relationships need socioaffective alignment
Feb 04, 2025Humans strive to design safe AI systems that align with our goals and remain under our control. However, as AI capabilities advance, we face a new challenge: the emergence of deeper, more persistent relationships between humans and AI systems. We explore how increasingly capable AI agents may generate the perception of deeper relationships with users, especially as AI becomes more personalised and agentic. This shift, from transactional interaction to ongoing sustained social engagement with AI, necessitates a new focus on socioaffective alignment-how an AI system behaves within the social and psychological ecosystem co-created with its user, where preferences and perceptions evolve through mutual influence. Addressing these dynamics involves resolving key intrapersonal dilemmas, including balancing immediate versus long-term well-being, protecting autonomy, and managing AI companionship alongside the desire to preserve human social bonds. By framing these challenges through a notion of basic psychological needs, we seek AI systems that support, rather than exploit, our fundamental nature as social and emotional beings.
Beyond the Binary: Capturing Diverse Preferences With Reward Regularization
Dec 05, 2024


Large language models (LLMs) are increasingly deployed via public-facing interfaces to interact with millions of users, each with diverse preferences. Despite this, preference tuning of LLMs predominantly relies on reward models trained using binary judgments where annotators select the preferred choice out of pairs of model outputs. In this work, we argue that this reliance on binary choices does not capture the broader, aggregate preferences of the target user in real-world tasks. We propose a taxonomy that identifies two dimensions of subjectivity where different users disagree on the preferred output-namely, the Plurality of Responses to Prompts, where prompts allow for multiple correct answers, and the Indistinguishability of Responses, where candidate outputs are paraphrases of each other. We show that reward models correlate weakly with user preferences in these cases. As a first step to address this issue, we introduce a simple yet effective method that augments existing binary preference datasets with synthetic preference judgments to estimate potential user disagreement. Incorporating these via a margin term as a form of regularization during model training yields predictions that better align with the aggregate user preferences.
LINGOLY: A Benchmark of Olympiad-Level Linguistic Reasoning Puzzles in Low-Resource and Extinct Languages
Jun 11, 2024



In this paper, we present the LingOly benchmark, a novel benchmark for advanced reasoning abilities in large language models. Using challenging Linguistic Olympiad puzzles, we evaluate (i) capabilities for in-context identification and generalisation of linguistic patterns in very low-resource or extinct languages, and (ii) abilities to follow complex task instructions. The LingOly benchmark covers more than 90 mostly low-resource languages, minimising issues of data contamination, and contains 1,133 problems across 6 formats and 5 levels of human difficulty. We assess performance with both direct accuracy and comparison to a no-context baseline to penalise memorisation. Scores from 11 state-of-the-art LLMs demonstrate the benchmark to be challenging, and models perform poorly on the higher difficulty problems. On harder problems, even the top model only achieved 38.7% accuracy, 24.7% improvement over the no-context baseline. Large closed models typically outperform open models, and in general, the higher resource the language, the better the scores. These results indicate, in absence of memorisation, true multi-step out-of-domain reasoning remains a challenge for current language models.
The AI Community Building the Future? A Quantitative Analysis of Development Activity on Hugging Face Hub
May 20, 2024Open source developers have emerged as key actors in the political economy of artificial intelligence (AI), with open model development being recognised as an alternative to closed-source AI development. However, we still have a limited understanding of collaborative practices in open source AI. This paper responds to this gap with a three-part quantitative analysis of development activity on the Hugging Face (HF) Hub, a popular platform for building, sharing, and demonstrating models. First, we find that various types of activity across 348,181 model, 65,761 dataset, and 156,642 space repositories exhibit right-skewed distributions. Activity is extremely imbalanced between repositories; for example, over 70% of models have 0 downloads, while 1% account for 99% of downloads. Second, we analyse a snapshot of the social network structure of collaboration on models, finding that the community has a core-periphery structure, with a core of prolific developers and a majority of isolate developers (89%). Upon removing isolates, collaboration is characterised by high reciprocity regardless of developers' network positions. Third, we examine model adoption through the lens of model usage in spaces, finding that a minority of models, developed by a handful of companies, are widely used on the HF Hub. Overall, we find that various types of activity on the HF Hub are characterised by Pareto distributions, congruent with prior observations about OSS development patterns on platforms like GitHub. We conclude with a discussion of the implications of the findings and recommendations for (open source) AI researchers, developers, and policymakers.
The PRISM Alignment Project: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models
Apr 24, 2024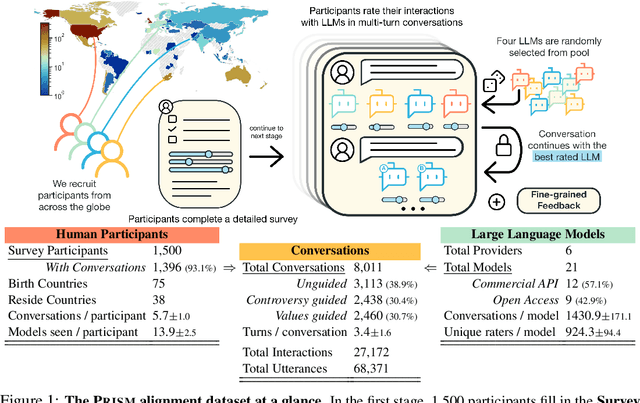
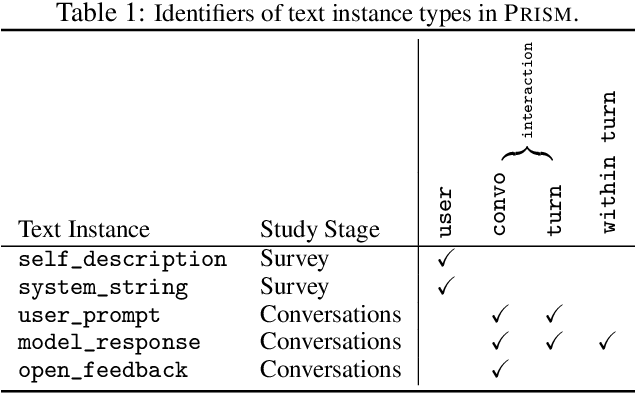
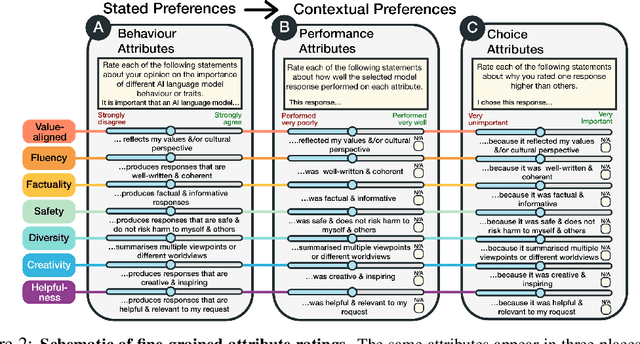

Human feedback plays a central role in the alignment of Large Language Models (LLMs). However, open questions remain about the methods (how), domains (where), people (who) and objectives (to what end) of human feedback collection. To navigate these questions, we introduce PRISM, a new dataset which maps the sociodemographics and stated preferences of 1,500 diverse participants from 75 countries, to their contextual preferences and fine-grained feedback in 8,011 live conversations with 21 LLMs. PRISM contributes (i) wide geographic and demographic participation in human feedback data; (ii) two census-representative samples for understanding collective welfare (UK and US); and (iii) individualised feedback where every rating is linked to a detailed participant profile, thus permitting exploration of personalisation and attribution of sample artefacts. We focus on collecting conversations that centre subjective and multicultural perspectives on value-laden and controversial topics, where we expect the most interpersonal and cross-cultural disagreement. We demonstrate the usefulness of PRISM via three case studies of dialogue diversity, preference diversity, and welfare outcomes, showing that it matters which humans set alignment norms. As well as offering a rich community resource, we advocate for broader participation in AI development and a more inclusive approach to technology design.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.