 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity Moderation and the New Epistemology of Fact Checking on Social Media
May 26, 2025Social media platforms have traditionally relied on internal moderation teams and partnerships with independent fact-checking organizations to identify and flag misleading content. Recently, however, platforms including X (formerly Twitter) and Meta have shifted towards community-driven content moderation by launching their own versions of crowd-sourced fact-checking -- Community Notes. If effectively scaled and governed, such crowd-checking initiatives have the potential to combat misinformation with increased scale and speed as successfully as community-driven efforts once did with spam. Nevertheless, general content moderation, especially for misinformation, is inherently more complex. Public perceptions of truth are often shaped by personal biases, political leanings, and cultural contexts, complicating consensus on what constitutes misleading content. This suggests that community efforts, while valuable, cannot replace the indispensable role of professional fact-checkers. Here we systemically examine the current approaches to misinformation detection across major platforms, explore the emerging role of community-driven moderation, and critically evaluate both the promises and challenges of crowd-checking at scale.
When Claims Evolve: Evaluating and Enhancing the Robustness of Embedding Models Against Misinformation Edits
Mar 05, 2025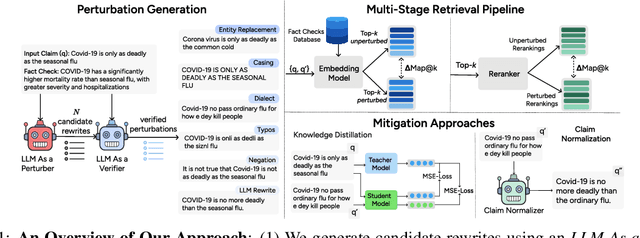
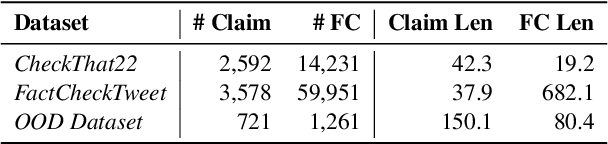
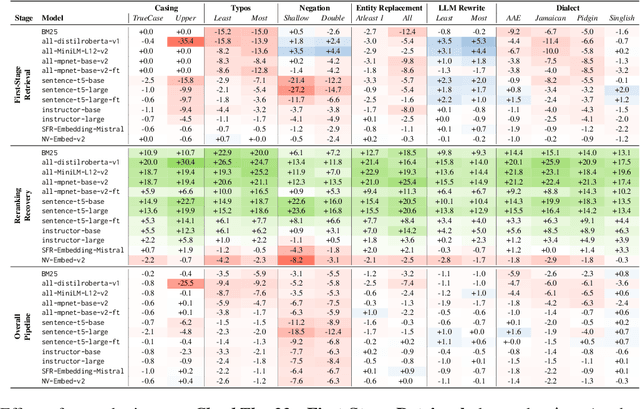
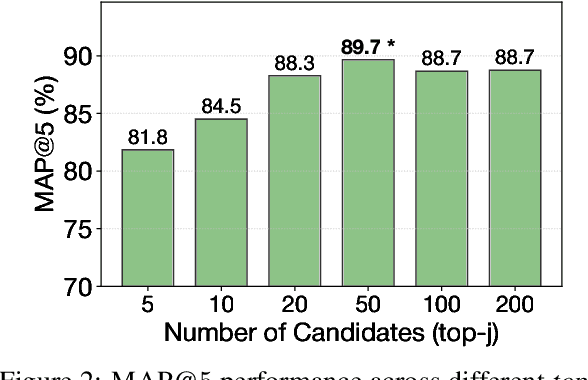
Online misinformation remains a critical challenge, and fact-checkers increasingly rely on embedding-based methods to retrieve relevant fact-checks. Yet, when debunked claims reappear in edited forms, the performance of these methods is unclear. In this work, we introduce a taxonomy of six common real-world misinformation edits and propose a perturbation framework that generates valid, natural claim variations. Our multi-stage retrieval evaluation reveals that standard embedding models struggle with user-introduced edits, while LLM-distilled embeddings offer improved robustness at a higher computational cost. Although a strong reranker helps mitigate some issues, it cannot fully compensate for first-stage retrieval gaps. Addressing these retrieval gaps, our train- and inference-time mitigation approaches enhance in-domain robustness by up to 17 percentage points and boost out-of-domain generalization by 10 percentage points over baseline models. Overall, our findings provide practical improvements to claim-matching systems, enabling more reliable fact-checking of evolving misinformation.
Scaling Crowdsourced Election Monitoring: Construction and Evaluation of Classification Models for Multilingual and Cross-Domain Classification Settings
Mar 05, 2025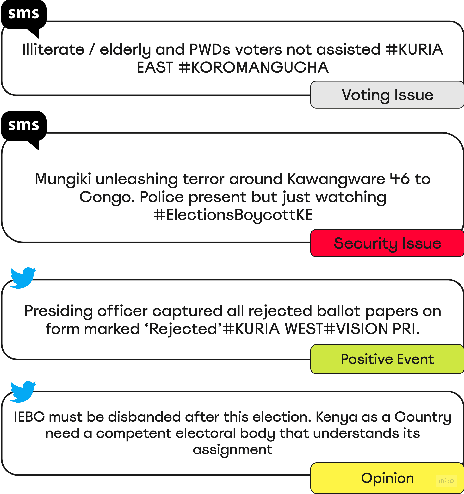
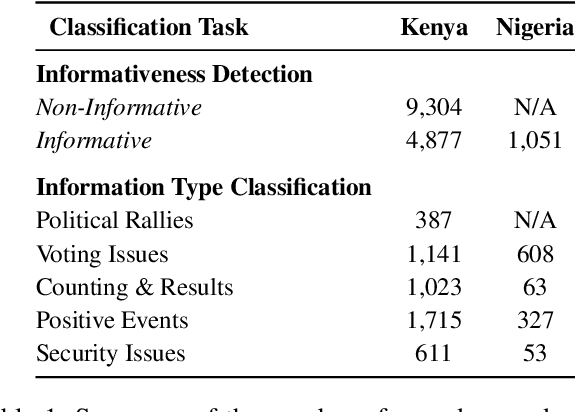
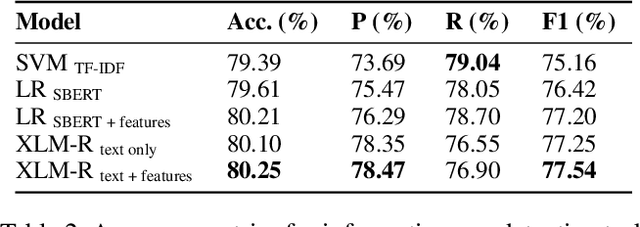
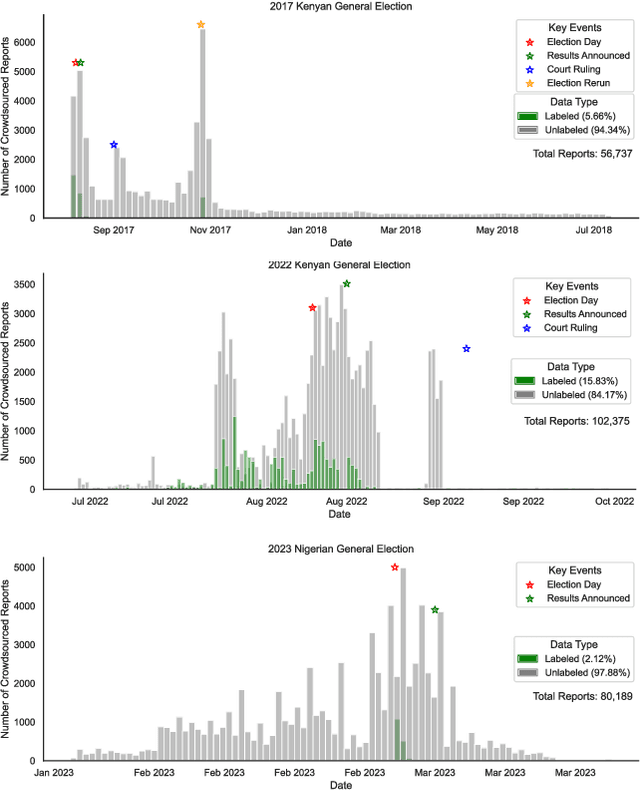
The adoption of crowdsourced election monitoring as a complementary alternative to traditional election monitoring is on the rise. Yet, its reliance on digital response volunteers to manually process incoming election reports poses a significant scaling bottleneck. In this paper, we address the challenge of scaling crowdsourced election monitoring by advancing the task of automated classification of crowdsourced election reports to multilingual and cross-domain classification settings. We propose a two-step classification approach of first identifying informative reports and then categorising them into distinct information types. We conduct classification experiments using multilingual transformer models such as XLM-RoBERTa and multilingual embeddings such as SBERT, augmented with linguistically motivated features. Our approach achieves F1-Scores of 77\% for informativeness detection and 75\% for information type classification. We conduct cross-domain experiments, applying models trained in a source electoral domain to a new target electoral domain in zero-shot and few-shot classification settings. Our results show promising potential for model transfer across electoral domains, with F1-Scores of 59\% in zero-shot and 63\% in few-shot settings. However, our analysis also reveals a performance bias in detecting informative English reports over Swahili, likely due to imbalances in the training data, indicating a need for caution when deploying classification models in real-world election scenarios.
Multilingual != Multicultural: Evaluating Gaps Between Multilingual Capabilities and Cultural Alignment in LLMs
Feb 23, 2025



Large Language Models (LLMs) are becoming increasingly capable across global languages. However, the ability to communicate across languages does not necessarily translate to appropriate cultural representations. A key concern is US-centric bias, where LLMs reflect US rather than local cultural values. We propose a novel methodology that compares LLM-generated response distributions against population-level opinion data from the World Value Survey across four languages (Danish, Dutch, English, and Portuguese). Using a rigorous linear mixed-effects regression framework, we compare two families of models: Google's Gemma models (2B--27B parameters) and successive iterations of OpenAI's turbo-series. Across the families of models, we find no consistent relationships between language capabilities and cultural alignment. While the Gemma models have a positive correlation between language capability and cultural alignment across languages, the OpenAI models do not. Importantly, we find that self-consistency is a stronger predictor of multicultural alignment than multilingual capabilities. Our results demonstrate that achieving meaningful cultural alignment requires dedicated effort beyond improving general language capabilities.
Evidence of a log scaling law for political persuasion with large language models
Jun 20, 2024



Large language models can now generate political messages as persuasive as those written by humans, raising concerns about how far this persuasiveness may continue to increase with model size. Here, we generate 720 persuasive messages on 10 U.S. political issues from 24 language models spanning several orders of magnitude in size. We then deploy these messages in a large-scale randomized survey experiment (N = 25,982) to estimate the persuasive capability of each model. Our findings are twofold. First, we find evidence of a log scaling law: model persuasiveness is characterized by sharply diminishing returns, such that current frontier models are barely more persuasive than models smaller in size by an order of magnitude or more. Second, mere task completion (coherence, staying on topic) appears to account for larger models' persuasive advantage. These findings suggest that further scaling model size will not much increase the persuasiveness of static LLM-generated messages.
A Multilingual Similarity Dataset for News Article Frame
May 22, 2024Understanding the writing frame of news articles is vital for addressing social issues, and thus has attracted notable attention in the fields of communication studies. Yet, assessing such news article frames remains a challenge due to the absence of a concrete and unified standard dataset that considers the comprehensive nuances within news content. To address this gap, we introduce an extended version of a large labeled news article dataset with 16,687 new labeled pairs. Leveraging the pairwise comparison of news articles, our method frees the work of manual identification of frame classes in traditional news frame analysis studies. Overall we introduce the most extensive cross-lingual news article similarity dataset available to date with 26,555 labeled news article pairs across 10 languages. Each data point has been meticulously annotated according to a codebook detailing eight critical aspects of news content, under a human-in-the-loop framework. Application examples demonstrate its potential in unearthing country communities within global news coverage, exposing media bias among news outlets, and quantifying the factors related to news creation. We envision that this news similarity dataset will broaden our understanding of the media ecosystem in terms of news coverage of events and perspectives across countries, locations, languages, and other social constructs. By doing so, it can catalyze advancements in social science research and applied methodologies, thereby exerting a profound impact on our society.
Into the crossfire: evaluating the use of a language model to crowdsource gun violence reports
Jan 16, 2024



Gun violence is a pressing and growing human rights issue that affects nearly every dimension of the social fabric, from healthcare and education to psychology and the economy. Reliable data on firearm events is paramount to developing more effective public policy and emergency responses. However, the lack of comprehensive databases and the risks of in-person surveys prevent human rights organizations from collecting needed data in most countries. Here, we partner with a Brazilian human rights organization to conduct a systematic evaluation of language models to assist with monitoring real-world firearm events from social media data. We propose a fine-tuned BERT-based model trained on Twitter (now X) texts to distinguish gun violence reports from ordinary Portuguese texts. Our model achieves a high AUC score of 0.97. We then incorporate our model into a web application and test it in a live intervention. We study and interview Brazilian analysts who continuously fact-check social media texts to identify new gun violence events. Qualitative assessments show that our solution helped all analysts use their time more efficiently and expanded their search capacities. Quantitative assessments show that the use of our model was associated with more analysts' interactions with online users reporting gun violence. Taken together, our findings suggest that modern Natural Language Processing techniques can help support the work of human rights organizations.
Factuality Challenges in the Era of Large Language Models
Oct 10, 2023The emergence of tools based on Large Language Models (LLMs), such as OpenAI's ChatGPT, Microsoft's Bing Chat, and Google's Bard, has garnered immense public attention. These incredibly useful, natural-sounding tools mark significant advances in natural language generation, yet they exhibit a propensity to generate false, erroneous, or misleading content -- commonly referred to as "hallucinations." Moreover, LLMs can be exploited for malicious applications, such as generating false but credible-sounding content and profiles at scale. This poses a significant challenge to society in terms of the potential deception of users and the increasing dissemination of inaccurate information. In light of these risks, we explore the kinds of technological innovations, regulatory reforms, and AI literacy initiatives needed from fact-checkers, news organizations, and the broader research and policy communities. By identifying the risks, the imminent threats, and some viable solutions, we seek to shed light on navigating various aspects of veracity in the era of generative AI.
Detecting East Asian Prejudice on Social Media
May 08, 2020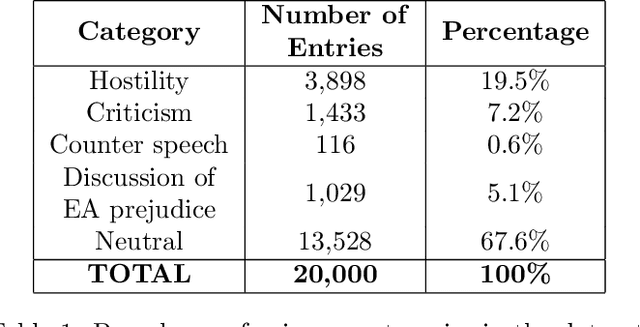
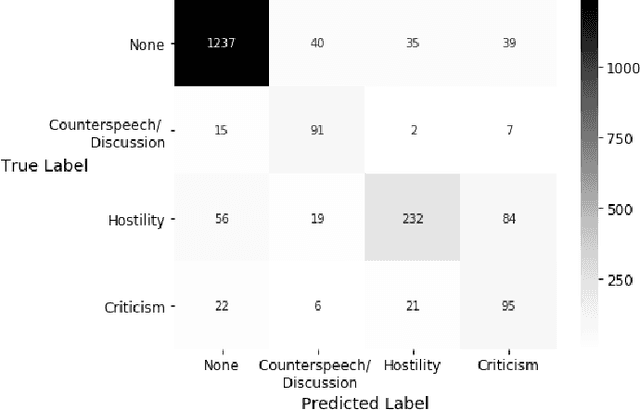
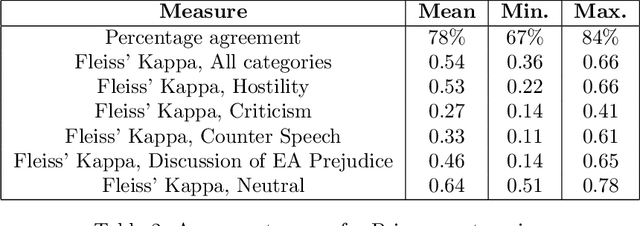
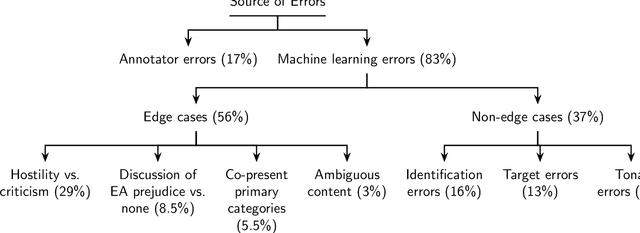
The outbreak of COVID-19 has transformed societies across the world as governments tackle the health, economic and social costs of the pandemic. It has also raised concerns about the spread of hateful language and prejudice online, especially hostility directed against East Asia. In this paper we report on the creation of a classifier that detects and categorizes social media posts from Twitter into four classes: Hostility against East Asia, Criticism of East Asia, Meta-discussions of East Asian prejudice and a neutral class. The classifier achieves an F1 score of 0.83 across all four classes. We provide our final model (coded in Python), as well as a new 20,000 tweet training dataset used to make the classifier, two analyses of hashtags associated with East Asian prejudice and the annotation codebook. The classifier can be implemented by other researchers, assisting with both online content moderation processes and further research into the dynamics, prevalence and impact of East Asian prejudice online during this global pandemic.