 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeciphering Implicit Hate: Evaluating Automated Detection Algorithms for Multimodal Hate
Jun 10, 2021


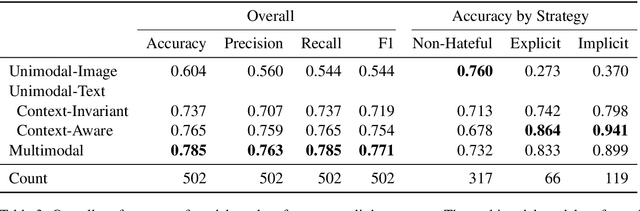
Accurate detection and classification of online hate is a difficult task. Implicit hate is particularly challenging as such content tends to have unusual syntax, polysemic words, and fewer markers of prejudice (e.g., slurs). This problem is heightened with multimodal content, such as memes (combinations of text and images), as they are often harder to decipher than unimodal content (e.g., text alone). This paper evaluates the role of semantic and multimodal context for detecting implicit and explicit hate. We show that both text- and visual- enrichment improves model performance, with the multimodal model (0.771) outperforming other models' F1 scores (0.544, 0.737, and 0.754). While the unimodal-text context-aware (transformer) model was the most accurate on the subtask of implicit hate detection, the multimodal model outperformed it overall because of a lower propensity towards false positives. We find that all models perform better on content with full annotator agreement and that multimodal models are best at classifying the content where annotators disagree. To conduct these investigations, we undertook high-quality annotation of a sample of 5,000 multimodal entries. Tweets were annotated for primary category, modality, and strategy. We make this corpus, along with the codebook, code, and final model, freely available.
* Please note the paper contains examples of hateful content
Detecting East Asian Prejudice on Social Media
May 08, 2020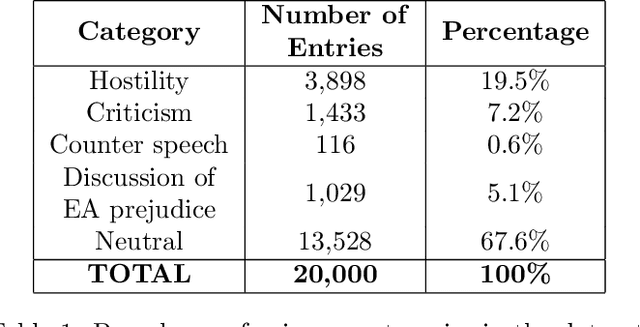
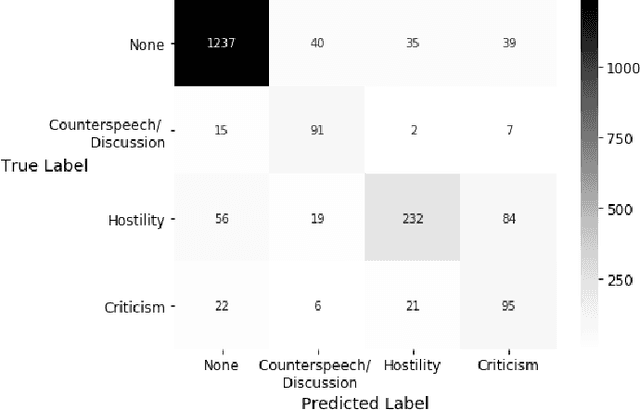
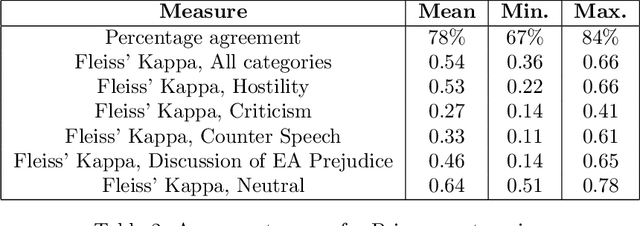
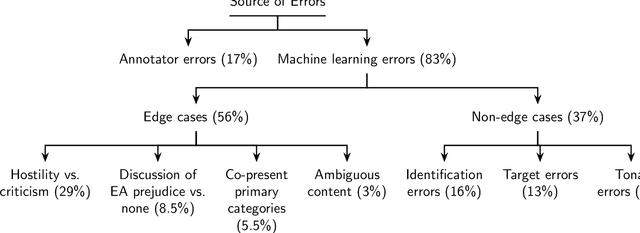
The outbreak of COVID-19 has transformed societies across the world as governments tackle the health, economic and social costs of the pandemic. It has also raised concerns about the spread of hateful language and prejudice online, especially hostility directed against East Asia. In this paper we report on the creation of a classifier that detects and categorizes social media posts from Twitter into four classes: Hostility against East Asia, Criticism of East Asia, Meta-discussions of East Asian prejudice and a neutral class. The classifier achieves an F1 score of 0.83 across all four classes. We provide our final model (coded in Python), as well as a new 20,000 tweet training dataset used to make the classifier, two analyses of hashtags associated with East Asian prejudice and the annotation codebook. The classifier can be implemented by other researchers, assisting with both online content moderation processes and further research into the dynamics, prevalence and impact of East Asian prejudice online during this global pandemic.