 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Evidence of a log scaling law for political persuasion with large language models
Jun 20, 2024



Large language models can now generate political messages as persuasive as those written by humans, raising concerns about how far this persuasiveness may continue to increase with model size. Here, we generate 720 persuasive messages on 10 U.S. political issues from 24 language models spanning several orders of magnitude in size. We then deploy these messages in a large-scale randomized survey experiment (N = 25,982) to estimate the persuasive capability of each model. Our findings are twofold. First, we find evidence of a log scaling law: model persuasiveness is characterized by sharply diminishing returns, such that current frontier models are barely more persuasive than models smaller in size by an order of magnitude or more. Second, mere task completion (coherence, staying on topic) appears to account for larger models' persuasive advantage. These findings suggest that further scaling model size will not much increase the persuasiveness of static LLM-generated messages.
AI for bureaucratic productivity: Measuring the potential of AI to help automate 143 million UK government transactions
Mar 18, 2024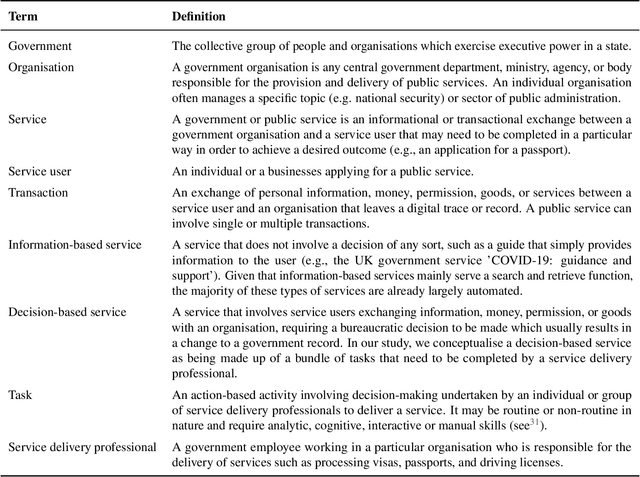
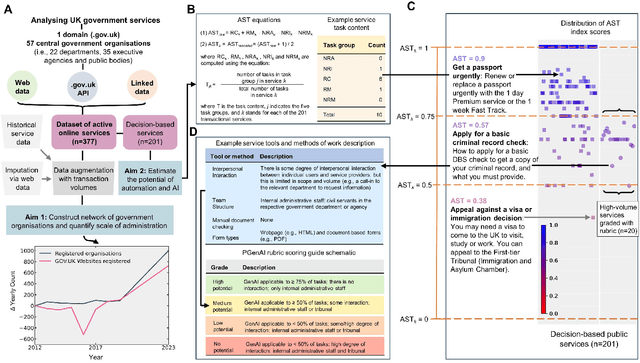
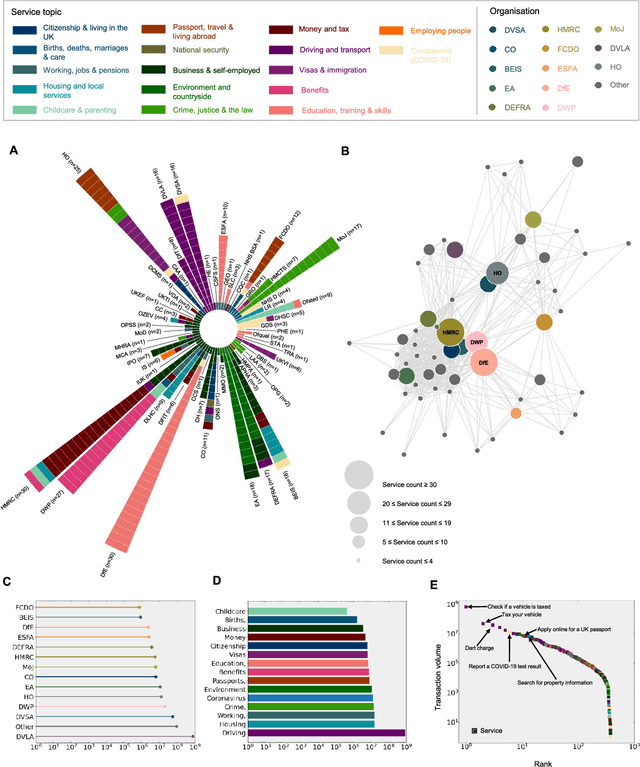
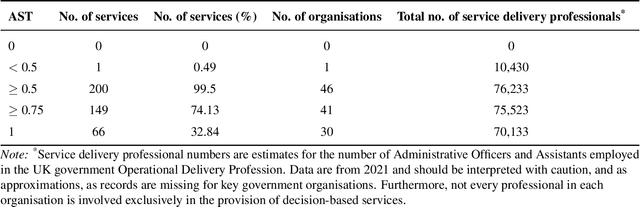
There is currently considerable excitement within government about the potential of artificial intelligence to improve public service productivity through the automation of complex but repetitive bureaucratic tasks, freeing up the time of skilled staff. Here, we explore the size of this opportunity, by mapping out the scale of citizen-facing bureaucratic decision-making procedures within UK central government, and measuring their potential for AI-driven automation. We estimate that UK central government conducts approximately one billion citizen-facing transactions per year in the provision of around 400 services, of which approximately 143 million are complex repetitive transactions. We estimate that 84% of these complex transactions are highly automatable, representing a huge potential opportunity: saving even an average of just one minute per complex transaction would save the equivalent of approximately 1,200 person-years of work every year. We also develop a model to estimate the volume of transactions a government service undertakes, providing a way for government to avoid conducting time consuming transaction volume measurements. Finally, we find that there is high turnover in the types of services government provide, meaning that automation efforts should focus on general procedures rather than services themselves which are likely to evolve over time. Overall, our work presents a novel perspective on the structure and functioning of modern government, and how it might evolve in the age of artificial intelligence.
Artificial intelligence in government: Concepts, standards, and a unified framework
Oct 31, 2022



Recent advances in artificial intelligence (AI) and machine learning (ML) hold the promise of improving government. Given the advanced capabilities of AI applications, it is critical that these are embedded using standard operational procedures, clear epistemic criteria, and behave in alignment with the normative expectations of society. Scholars in multiple domains have subsequently begun to conceptualize the different forms that AI systems may take, highlighting both their potential benefits and pitfalls. However, the literature remains fragmented, with researchers in social science disciplines like public administration and political science, and the fast-moving fields of AI, ML, and robotics, all developing concepts in relative isolation. Although there are calls to formalize the emerging study of AI in government, a balanced account that captures the full breadth of theoretical perspectives needed to understand the consequences of embedding AI into a public sector context is lacking. Here, we unify efforts across social and technical disciplines by using concept mapping to identify 107 different terms used in the multidisciplinary study of AI. We inductively sort these into three distinct semantic groups, which we label the (a) operational, (b) epistemic, and (c) normative domains. We then build on the results of this mapping exercise by proposing three new multifaceted concepts to study AI-based systems for government (AI-GOV) in an integrated, forward-looking way, which we call (1) operational fitness, (2) epistemic completeness, and (3) normative salience. Finally, we put these concepts to work by using them as dimensions in a conceptual typology of AI-GOV and connecting each with emerging AI technical measurement standards to encourage operationalization, foster cross-disciplinary dialogue, and stimulate debate among those aiming to reshape public administration with AI.
An influencer-based approach to understanding radical right viral tweets
Sep 15, 2021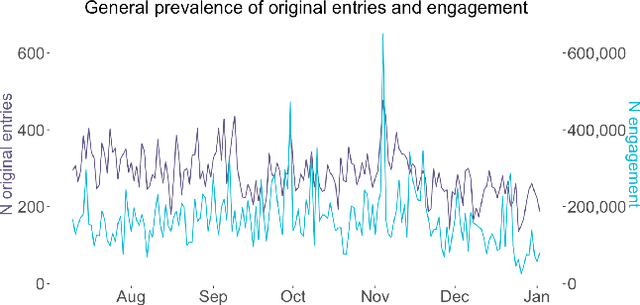
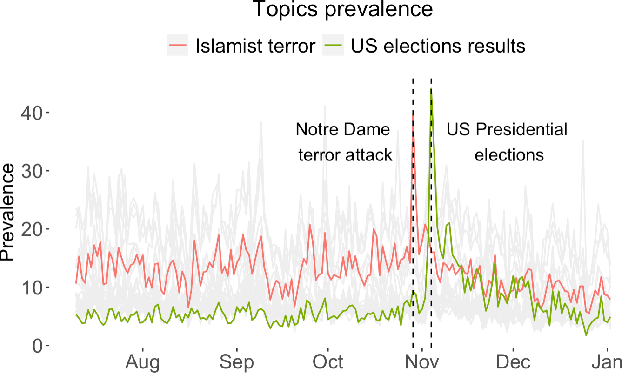
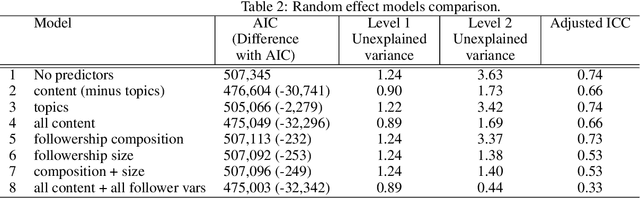
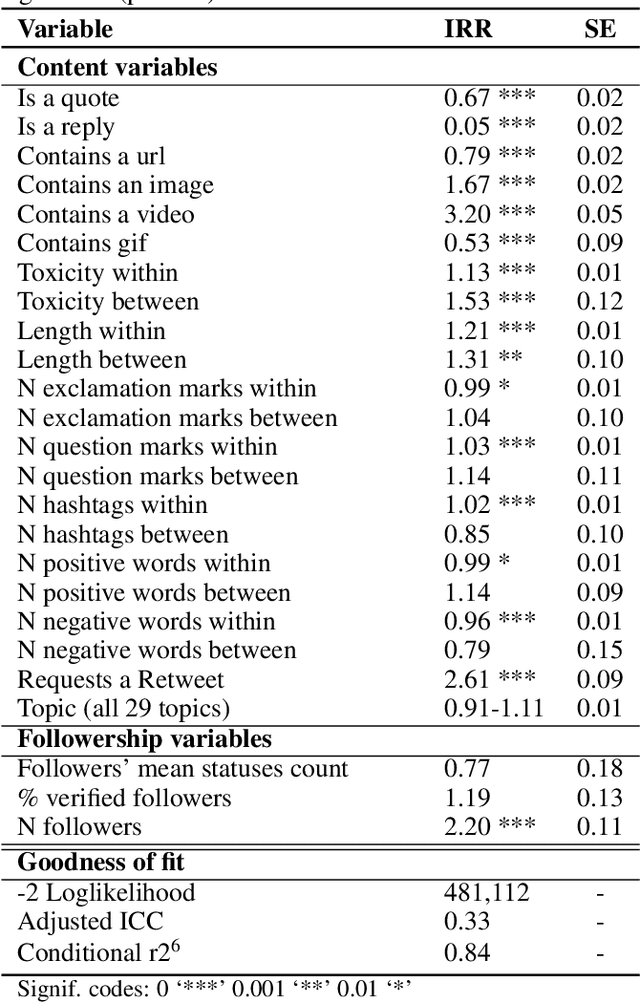
Radical right influencers routinely use social media to spread highly divisive, disruptive and anti-democratic messages. Assessing and countering the challenge that such content poses is crucial for ensuring that online spaces remain open, safe and accessible. Previous work has paid little attention to understanding factors associated with radical right content that goes viral. We investigate this issue with a new dataset ROT which provides insight into the content, engagement and followership of a set of 35 radical right influencers. It includes over 50,000 original entries and over 40 million retweets, quotes, replies and mentions. We use a multilevel model to measure engagement with tweets, which are nested in each influencer. We show that it is crucial to account for the influencer-level structure, and find evidence of the importance of both influencer- and content-level factors, including the number of followers each influencer has, the type of content (original posts, quotes and replies), the length and toxicity of content, and whether influencers request retweets. We make ROT available for other researchers to use.
HateCheck: Functional Tests for Hate Speech Detection Models
Dec 31, 2020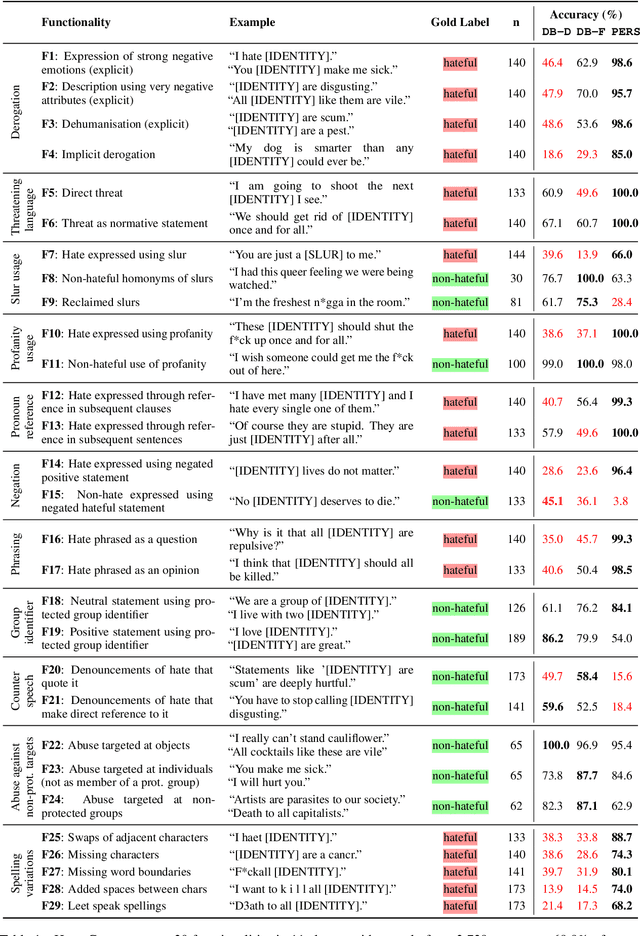
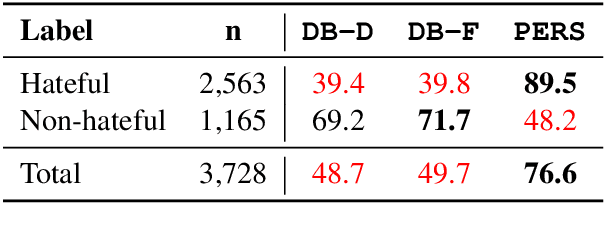
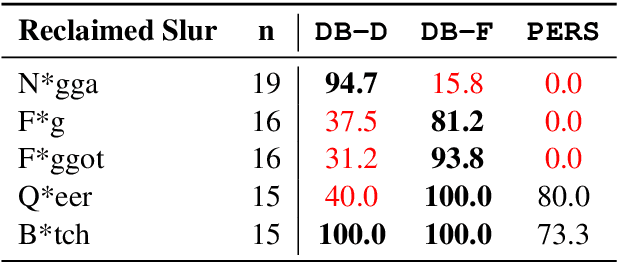
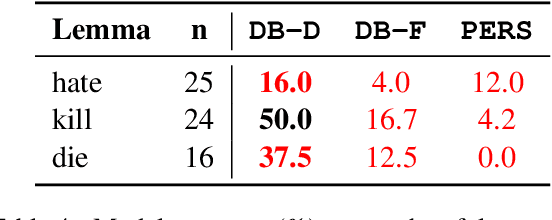
Detecting online hate is a difficult task that even state-of-the-art models struggle with. In previous research, hate speech detection models are typically evaluated by measuring their performance on held-out test data using metrics such as accuracy and F1 score. However, this approach makes it difficult to identify specific model weak points. It also risks overestimating generalisable model quality due to increasingly well-evidenced systematic gaps and biases in hate speech datasets. To enable more targeted diagnostic insights, we introduce HateCheck, a first suite of functional tests for hate speech detection models. We specify 29 model functionalities, the selection of which we motivate by reviewing previous research and through a series of interviews with civil society stakeholders. We craft test cases for each functionality and validate data quality through a structured annotation process. To illustrate HateCheck's utility, we test near-state-of-the-art transformer detection models as well as a popular commercial model, revealing critical model weaknesses.
Detecting East Asian Prejudice on Social Media
May 08, 2020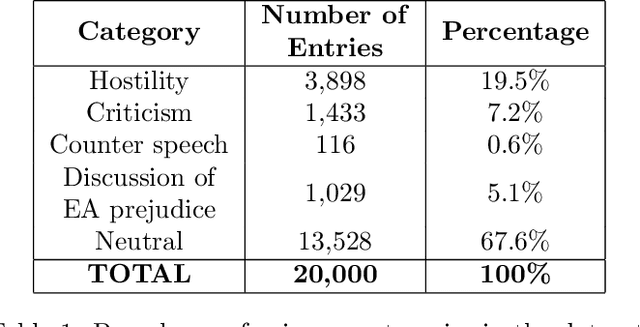
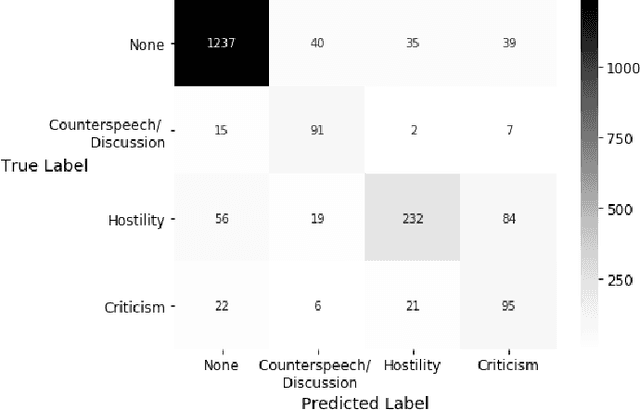
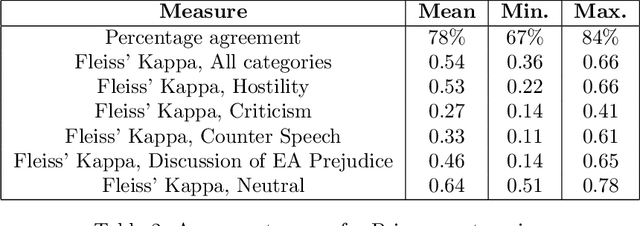
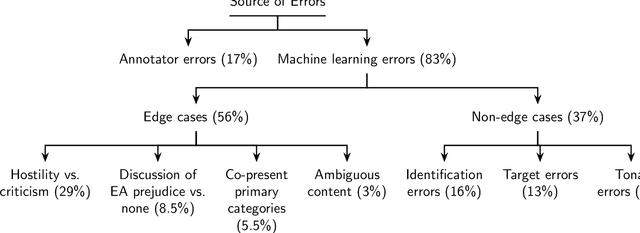
The outbreak of COVID-19 has transformed societies across the world as governments tackle the health, economic and social costs of the pandemic. It has also raised concerns about the spread of hateful language and prejudice online, especially hostility directed against East Asia. In this paper we report on the creation of a classifier that detects and categorizes social media posts from Twitter into four classes: Hostility against East Asia, Criticism of East Asia, Meta-discussions of East Asian prejudice and a neutral class. The classifier achieves an F1 score of 0.83 across all four classes. We provide our final model (coded in Python), as well as a new 20,000 tweet training dataset used to make the classifier, two analyses of hashtags associated with East Asian prejudice and the annotation codebook. The classifier can be implemented by other researchers, assisting with both online content moderation processes and further research into the dynamics, prevalence and impact of East Asian prejudice online during this global pandemic.