 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMDE: Exploring the Use of Synthetic vs Human Data for Evaluating Multi-Insight Multi-Document Extraction Tasks
Nov 29, 2024

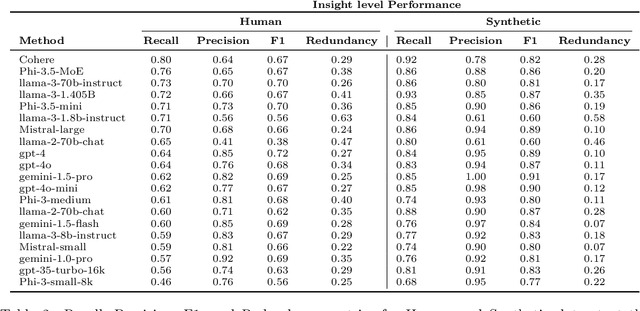
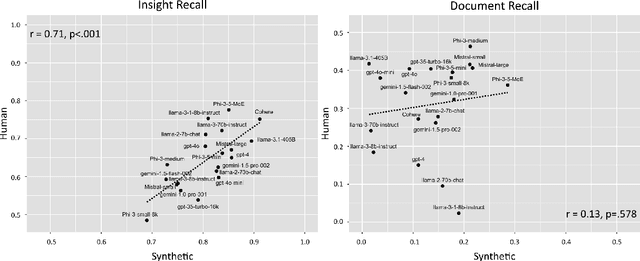
Large language models (LLMs) have demonstrated remarkable capabilities in text analysis tasks, yet their evaluation on complex, real-world applications remains challenging. We define a set of tasks, Multi-Insight Multi-Document Extraction (MIMDE) tasks, which involves extracting an optimal set of insights from a document corpus and mapping these insights back to their source documents. This task is fundamental to many practical applications, from analyzing survey responses to processing medical records, where identifying and tracing key insights across documents is crucial. We develop an evaluation framework for MIMDE and introduce a novel set of complementary human and synthetic datasets to examine the potential of synthetic data for LLM evaluation. After establishing optimal metrics for comparing extracted insights, we benchmark 20 state-of-the-art LLMs on both datasets. Our analysis reveals a strong correlation (0.71) between the ability of LLMs to extracts insights on our two datasets but synthetic data fails to capture the complexity of document-level analysis. These findings offer crucial guidance for the use of synthetic data in evaluating text analysis systems, highlighting both its potential and limitations.
AI for bureaucratic productivity: Measuring the potential of AI to help automate 143 million UK government transactions
Mar 18, 2024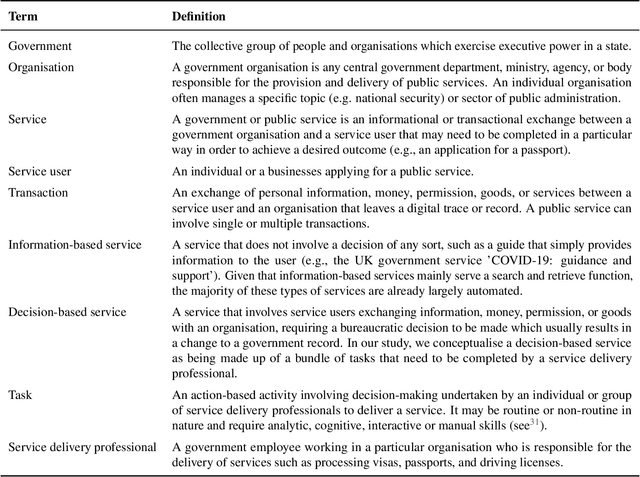
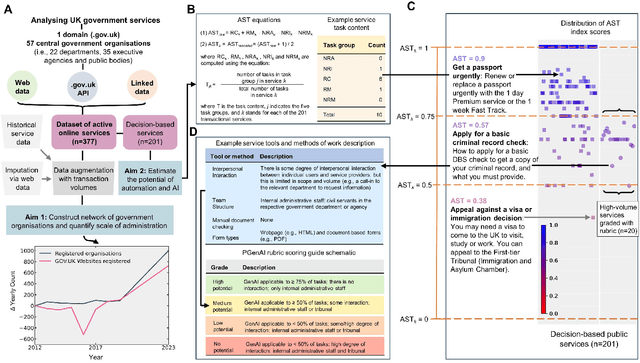
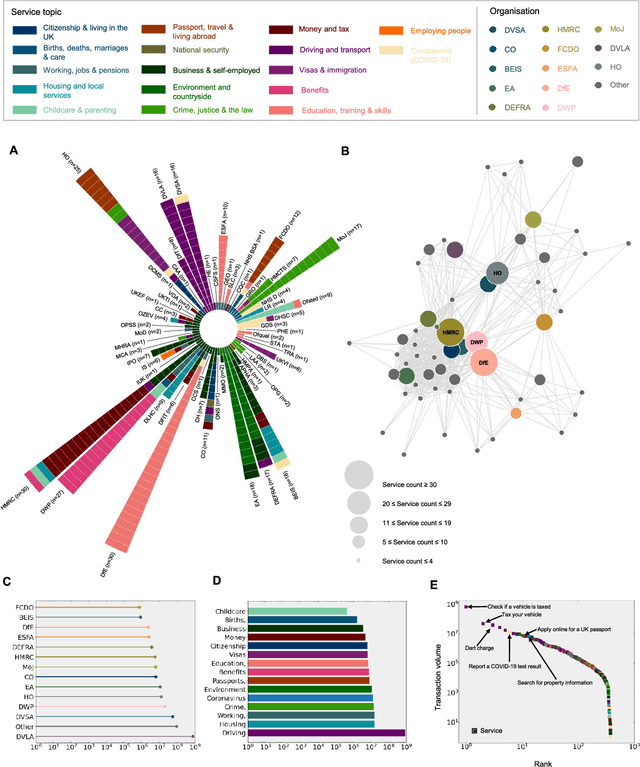
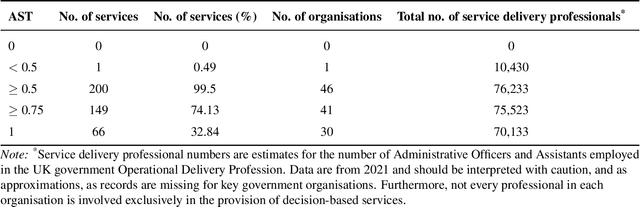
There is currently considerable excitement within government about the potential of artificial intelligence to improve public service productivity through the automation of complex but repetitive bureaucratic tasks, freeing up the time of skilled staff. Here, we explore the size of this opportunity, by mapping out the scale of citizen-facing bureaucratic decision-making procedures within UK central government, and measuring their potential for AI-driven automation. We estimate that UK central government conducts approximately one billion citizen-facing transactions per year in the provision of around 400 services, of which approximately 143 million are complex repetitive transactions. We estimate that 84% of these complex transactions are highly automatable, representing a huge potential opportunity: saving even an average of just one minute per complex transaction would save the equivalent of approximately 1,200 person-years of work every year. We also develop a model to estimate the volume of transactions a government service undertakes, providing a way for government to avoid conducting time consuming transaction volume measurements. Finally, we find that there is high turnover in the types of services government provide, meaning that automation efforts should focus on general procedures rather than services themselves which are likely to evolve over time. Overall, our work presents a novel perspective on the structure and functioning of modern government, and how it might evolve in the age of artificial intelligence.
'Team-in-the-loop' organisational oversight of high-stakes AI
Mar 24, 2023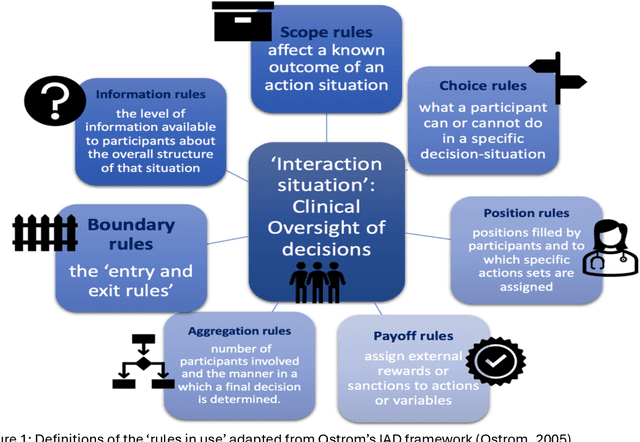
Oversight is rightly recognised as vital within high-stakes public sector AI applications, where decisions can have profound individual and collective impacts. Much current thinking regarding forms of oversight mechanisms for AI within the public sector revolves around the idea of human decision makers being 'in-the-loop' and thus being able to intervene to prevent errors and potential harm. However, in a number of high-stakes public sector contexts, operational oversight of decisions is made by expert teams rather than individuals. The ways in which deployed AI systems can be integrated into these existing operational team oversight processes has yet to attract much attention. We address this gap by exploring the impacts of AI upon pre-existing oversight of clinical decision-making through institutional analysis. We find that existing oversight is nested within professional training requirements and relies heavily upon explanation and questioning to elicit vital information. Professional bodies and liability mechanisms also act as additional levers of oversight. These dimensions of oversight are impacted, and potentially reconfigured, by AI systems. We therefore suggest a broader lens of 'team-in-the-loop' to conceptualise the system-level analysis required for adoption of AI within high-stakes public sector deployment.
A multidomain relational framework to guide institutional AI research and adoption
Mar 17, 2023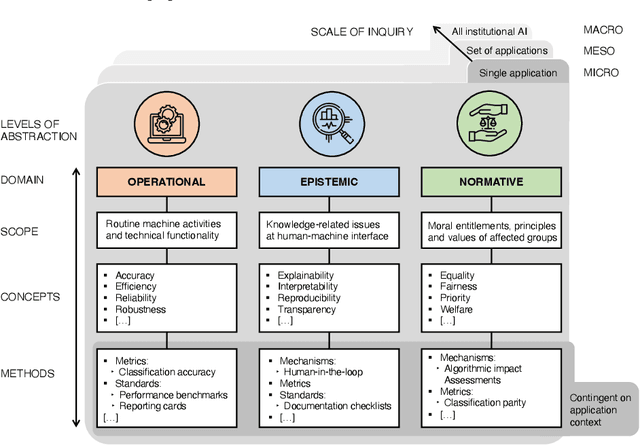
Calls for new metrics, technical standards and governance mechanisms to guide the adoption of Artificial Intelligence (AI) in institutions and public administration are now commonplace. Yet, most research and policy efforts aimed at understanding the implications of adopting AI tend to prioritize only a handful of ideas; they do not fully account for all the different perspectives and topics that are potentially relevant. In this position paper, we contend that this omission stems, in part, from what we call the relational problem in socio-technical discourse: fundamental ontological issues have not yet been settled-including semantic ambiguity, a lack of clear relations between concepts and differing standard terminologies. This contributes to the persistence of disparate modes of reasoning to assess institutional AI systems, and the prevalence of conceptual isolation in the fields that study them including ML, human factors, social science and policy. After developing this critique, we offer a way forward by proposing a simple policy and research design tool in the form of a conceptual framework to organize terms across fields-consisting of three horizontal domains for grouping relevant concepts and related methods: Operational, epistemic, and normative. We first situate this framework against the backdrop of recent socio-technical discourse at two premier academic venues, AIES and FAccT, before illustrating how developing suitable metrics, standards, and mechanisms can be aided by operationalizing relevant concepts in each of these domains. Finally, we outline outstanding questions for developing this relational approach to institutional AI research and adoption.