 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMDE: Exploring the Use of Synthetic vs Human Data for Evaluating Multi-Insight Multi-Document Extraction Tasks
Nov 29, 2024

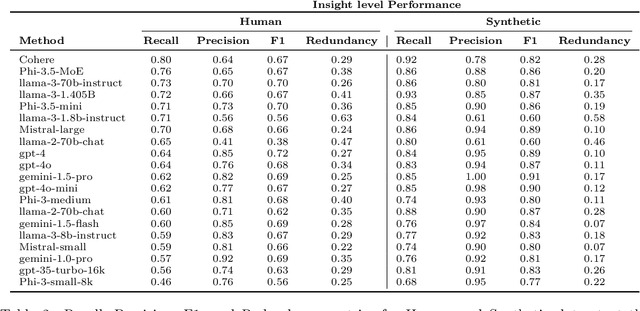
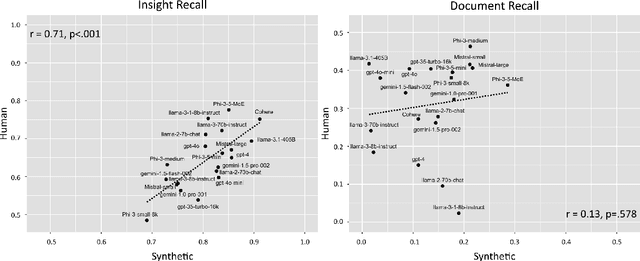
Large language models (LLMs) have demonstrated remarkable capabilities in text analysis tasks, yet their evaluation on complex, real-world applications remains challenging. We define a set of tasks, Multi-Insight Multi-Document Extraction (MIMDE) tasks, which involves extracting an optimal set of insights from a document corpus and mapping these insights back to their source documents. This task is fundamental to many practical applications, from analyzing survey responses to processing medical records, where identifying and tracing key insights across documents is crucial. We develop an evaluation framework for MIMDE and introduce a novel set of complementary human and synthetic datasets to examine the potential of synthetic data for LLM evaluation. After establishing optimal metrics for comparing extracted insights, we benchmark 20 state-of-the-art LLMs on both datasets. Our analysis reveals a strong correlation (0.71) between the ability of LLMs to extracts insights on our two datasets but synthetic data fails to capture the complexity of document-level analysis. These findings offer crucial guidance for the use of synthetic data in evaluating text analysis systems, highlighting both its potential and limitations.