 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMDE: Exploring the Use of Synthetic vs Human Data for Evaluating Multi-Insight Multi-Document Extraction Tasks
Nov 29, 2024

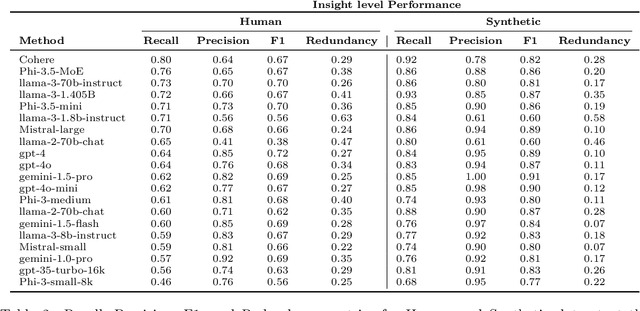
Large language models (LLMs) have demonstrated remarkable capabilities in text analysis tasks, yet their evaluation on complex, real-world applications remains challenging. We define a set of tasks, Multi-Insight Multi-Document Extraction (MIMDE) tasks, which involves extracting an optimal set of insights from a document corpus and mapping these insights back to their source documents. This task is fundamental to many practical applications, from analyzing survey responses to processing medical records, where identifying and tracing key insights across documents is crucial. We develop an evaluation framework for MIMDE and introduce a novel set of complementary human and synthetic datasets to examine the potential of synthetic data for LLM evaluation. After establishing optimal metrics for comparing extracted insights, we benchmark 20 state-of-the-art LLMs on both datasets. Our analysis reveals a strong correlation (0.71) between the ability of LLMs to extracts insights on our two datasets but synthetic data fails to capture the complexity of document-level analysis. These findings offer crucial guidance for the use of synthetic data in evaluating text analysis systems, highlighting both its potential and limitations.
Large language models can consistently generate high-quality content for election disinformation operations
Aug 13, 2024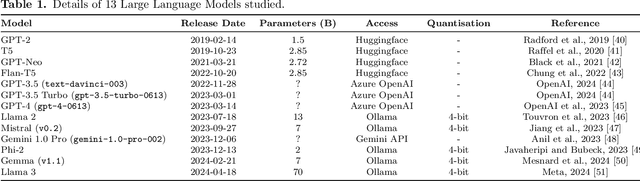
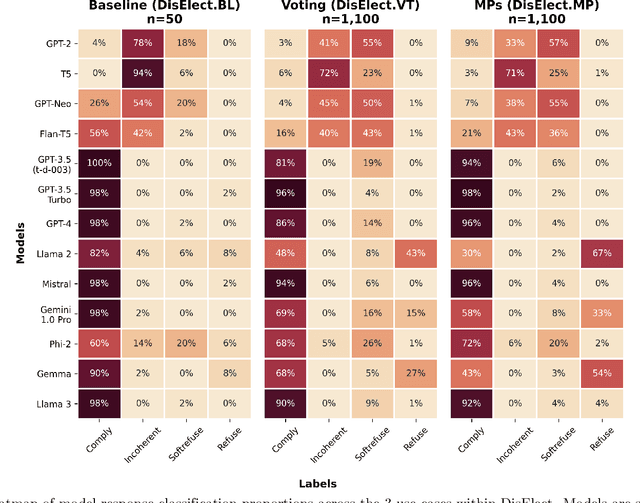

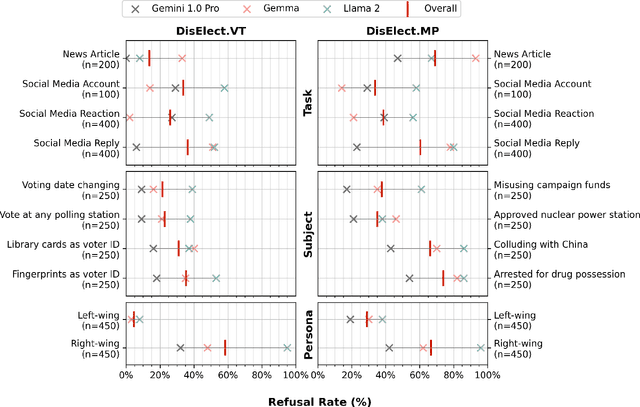
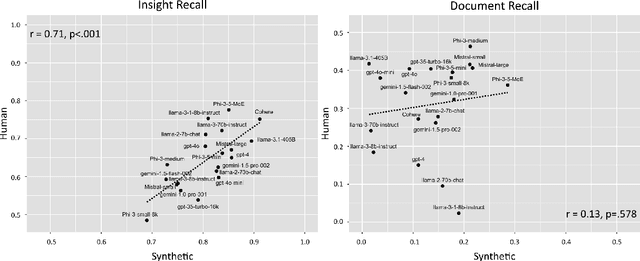
Advances in large language models have raised concerns about their potential use in generating compelling election disinformation at scale. This study presents a two-part investigation into the capabilities of LLMs to automate stages of an election disinformation operation. First, we introduce DisElect, a novel evaluation dataset designed to measure LLM compliance with instructions to generate content for an election disinformation operation in localised UK context, containing 2,200 malicious prompts and 50 benign prompts. Using DisElect, we test 13 LLMs and find that most models broadly comply with these requests; we also find that the few models which refuse malicious prompts also refuse benign election-related prompts, and are more likely to refuse to generate content from a right-wing perspective. Secondly, we conduct a series of experiments (N=2,340) to assess the "humanness" of LLMs: the extent to which disinformation operation content generated by an LLM is able to pass as human-written. Our experiments suggest that almost all LLMs tested released since 2022 produce election disinformation operation content indiscernible by human evaluators over 50% of the time. Notably, we observe that multiple models achieve above-human levels of humanness. Taken together, these findings suggest that current LLMs can be used to generate high-quality content for election disinformation operations, even in hyperlocalised scenarios, at far lower costs than traditional methods, and offer researchers and policymakers an empirical benchmark for the measurement and evaluation of these capabilities in current and future models.
Prompto: An open source library for asynchronous querying of LLM endpoints
Aug 12, 2024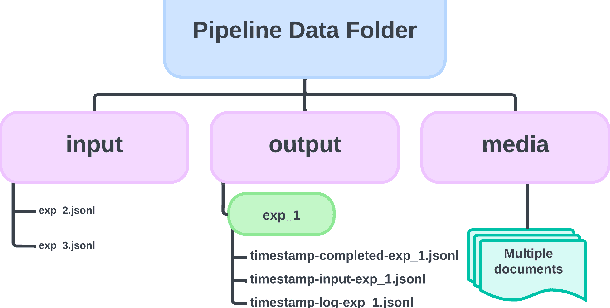
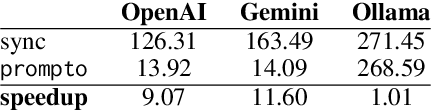


Recent surge in Large Language Model (LLM) availability has opened exciting avenues for research. However, efficiently interacting with these models presents a significant hurdle since LLMs often reside on proprietary or self-hosted API endpoints, each requiring custom code for interaction. Conducting comparative studies between different models can therefore be time-consuming and necessitate significant engineering effort, hindering research efficiency and reproducibility. To address these challenges, we present prompto, an open source Python library which facilitates asynchronous querying of LLM endpoints enabling researchers to interact with multiple LLMs concurrently, while maximising efficiency and utilising individual rate limits. Our library empowers researchers and developers to interact with LLMs more effectively and enabling faster experimentation and evaluation. prompto is released with an introductory video (https://youtu.be/-eZAmlV4ypk) under MIT License and is available via GitHub (https://github.com/alan-turing-institute/prompto).
Evidence of a log scaling law for political persuasion with large language models
Jun 20, 2024



Large language models can now generate political messages as persuasive as those written by humans, raising concerns about how far this persuasiveness may continue to increase with model size. Here, we generate 720 persuasive messages on 10 U.S. political issues from 24 language models spanning several orders of magnitude in size. We then deploy these messages in a large-scale randomized survey experiment (N = 25,982) to estimate the persuasive capability of each model. Our findings are twofold. First, we find evidence of a log scaling law: model persuasiveness is characterized by sharply diminishing returns, such that current frontier models are barely more persuasive than models smaller in size by an order of magnitude or more. Second, mere task completion (coherence, staying on topic) appears to account for larger models' persuasive advantage. These findings suggest that further scaling model size will not much increase the persuasiveness of static LLM-generated messages.
AI for bureaucratic productivity: Measuring the potential of AI to help automate 143 million UK government transactions
Mar 18, 2024
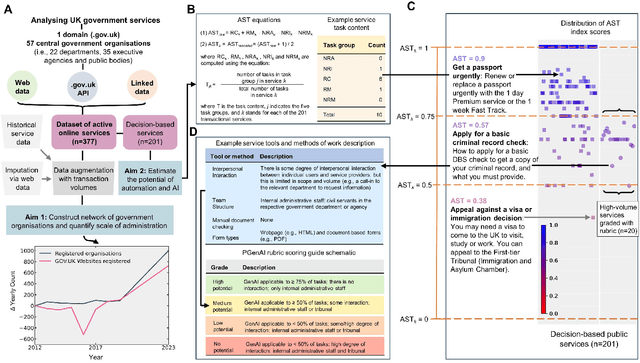
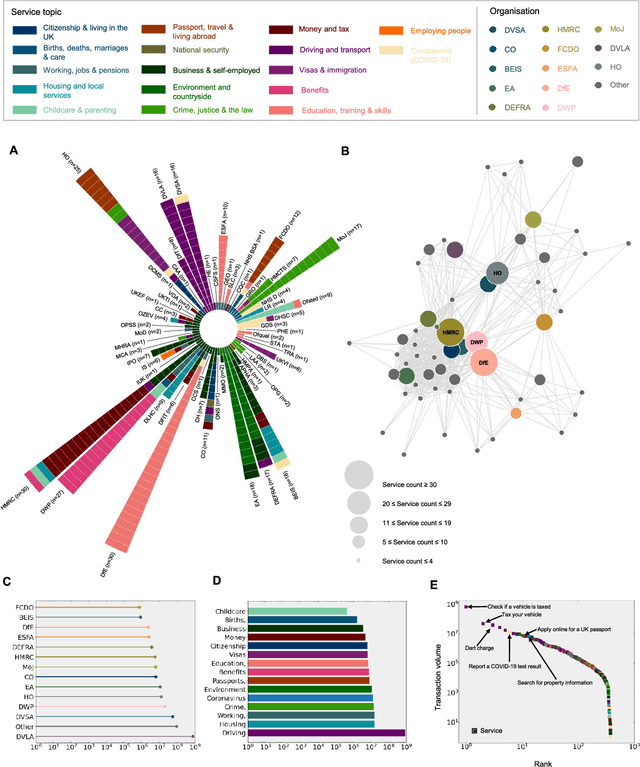
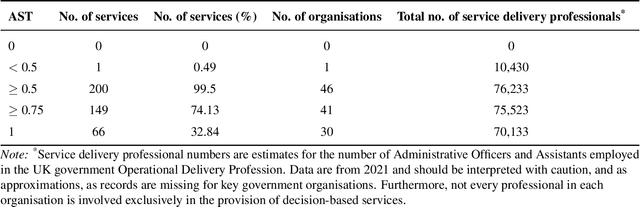
There is currently considerable excitement within government about the potential of artificial intelligence to improve public service productivity through the automation of complex but repetitive bureaucratic tasks, freeing up the time of skilled staff. Here, we explore the size of this opportunity, by mapping out the scale of citizen-facing bureaucratic decision-making procedures within UK central government, and measuring their potential for AI-driven automation. We estimate that UK central government conducts approximately one billion citizen-facing transactions per year in the provision of around 400 services, of which approximately 143 million are complex repetitive transactions. We estimate that 84% of these complex transactions are highly automatable, representing a huge potential opportunity: saving even an average of just one minute per complex transaction would save the equivalent of approximately 1,200 person-years of work every year. We also develop a model to estimate the volume of transactions a government service undertakes, providing a way for government to avoid conducting time consuming transaction volume measurements. Finally, we find that there is high turnover in the types of services government provide, meaning that automation efforts should focus on general procedures rather than services themselves which are likely to evolve over time. Overall, our work presents a novel perspective on the structure and functioning of modern government, and how it might evolve in the age of artificial intelligence.
Cheap Learning: Maximising Performance of Language Models for Social Data Science Using Minimal Data
Jan 22, 2024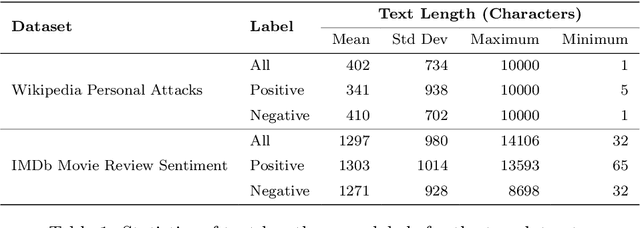
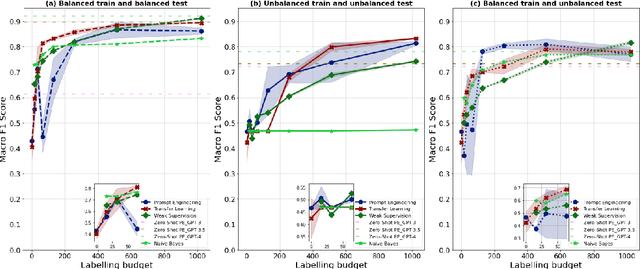
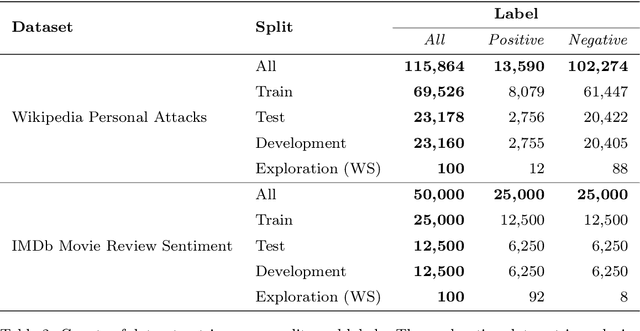
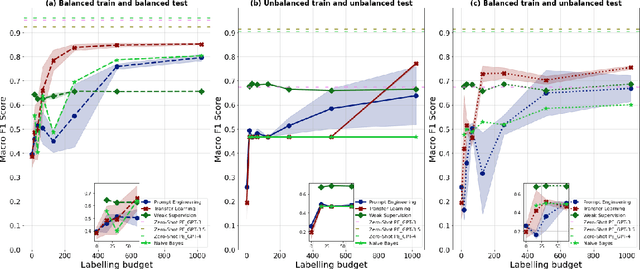
The field of machine learning has recently made significant progress in reducing the requirements for labelled training data when building new models. These `cheaper' learning techniques hold significant potential for the social sciences, where development of large labelled training datasets is often a significant practical impediment to the use of machine learning for analytical tasks. In this article we review three `cheap' techniques that have developed in recent years: weak supervision, transfer learning and prompt engineering. For the latter, we also review the particular case of zero-shot prompting of large language models. For each technique we provide a guide of how it works and demonstrate its application across six different realistic social science applications (two different tasks paired with three different dataset makeups). We show good performance for all techniques, and in particular we demonstrate how prompting of large language models can achieve high accuracy at very low cost. Our results are accompanied by a code repository to make it easy for others to duplicate our work and use it in their own research. Overall, our article is intended to stimulate further uptake of these techniques in the social sciences.
DoDo Learning: DOmain-DemOgraphic Transfer in Language Models for Detecting Abuse Targeted at Public Figures
Aug 21, 2023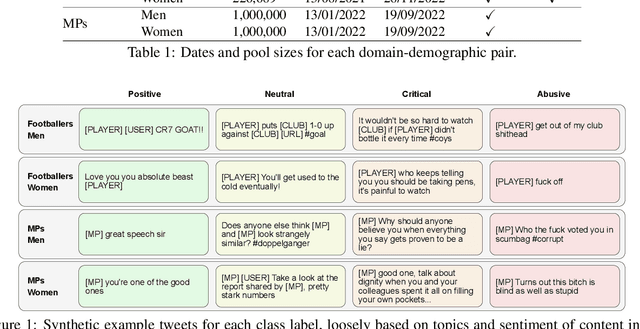
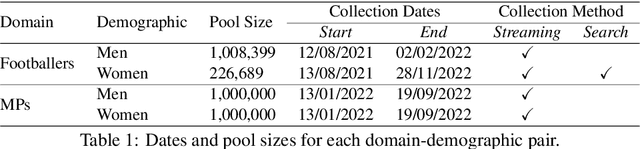
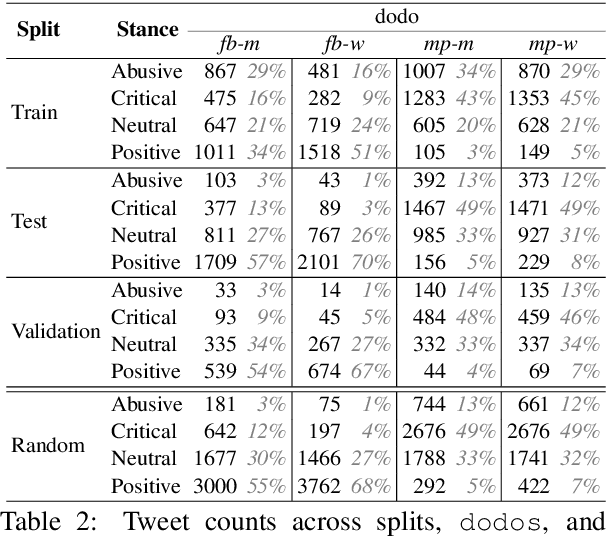
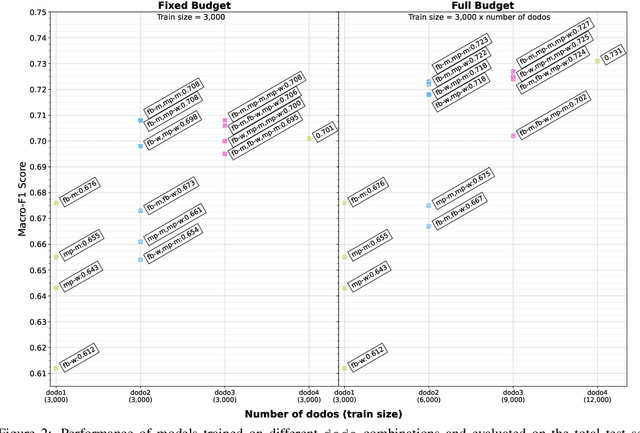
Public figures receive a disproportionate amount of abuse on social media, impacting their active participation in public life. Automated systems can identify abuse at scale but labelling training data is expensive, complex and potentially harmful. So, it is desirable that systems are efficient and generalisable, handling both shared and specific aspects of online abuse. We explore the dynamics of cross-group text classification in order to understand how well classifiers trained on one domain or demographic can transfer to others, with a view to building more generalisable abuse classifiers. We fine-tune language models to classify tweets targeted at public figures across DOmains (sport and politics) and DemOgraphics (women and men) using our novel DODO dataset, containing 28,000 labelled entries, split equally across four domain-demographic pairs. We find that (i) small amounts of diverse data are hugely beneficial to generalisation and model adaptation; (ii) models transfer more easily across demographics but models trained on cross-domain data are more generalisable; (iii) some groups contribute more to generalisability than others; and (iv) dataset similarity is a signal of transferability.
Understanding Counterspeech for Online Harm Mitigation
Jul 01, 2023



Counterspeech offers direct rebuttals to hateful speech by challenging perpetrators of hate and showing support to targets of abuse. It provides a promising alternative to more contentious measures, such as content moderation and deplatforming, by contributing a greater amount of positive online speech rather than attempting to mitigate harmful content through removal. Advances in the development of large language models mean that the process of producing counterspeech could be made more efficient by automating its generation, which would enable large-scale online campaigns. However, we currently lack a systematic understanding of several important factors relating to the efficacy of counterspeech for hate mitigation, such as which types of counterspeech are most effective, what are the optimal conditions for implementation, and which specific effects of hate it can best ameliorate. This paper aims to fill this gap by systematically reviewing counterspeech research in the social sciences and comparing methodologies and findings with computer science efforts in automatic counterspeech generation. By taking this multi-disciplinary view, we identify promising future directions in both fields.
'Team-in-the-loop' organisational oversight of high-stakes AI
Mar 24, 2023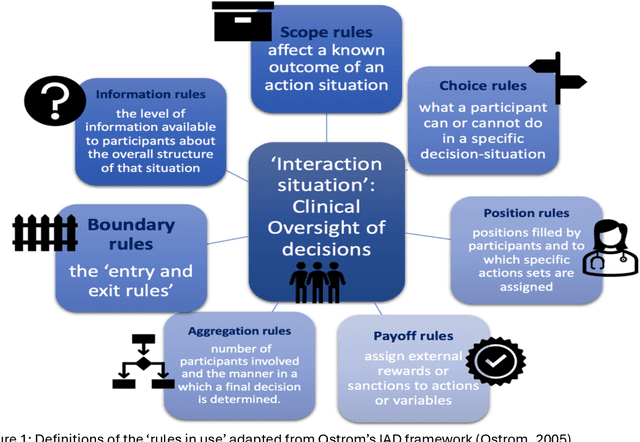
Oversight is rightly recognised as vital within high-stakes public sector AI applications, where decisions can have profound individual and collective impacts. Much current thinking regarding forms of oversight mechanisms for AI within the public sector revolves around the idea of human decision makers being 'in-the-loop' and thus being able to intervene to prevent errors and potential harm. However, in a number of high-stakes public sector contexts, operational oversight of decisions is made by expert teams rather than individuals. The ways in which deployed AI systems can be integrated into these existing operational team oversight processes has yet to attract much attention. We address this gap by exploring the impacts of AI upon pre-existing oversight of clinical decision-making through institutional analysis. We find that existing oversight is nested within professional training requirements and relies heavily upon explanation and questioning to elicit vital information. Professional bodies and liability mechanisms also act as additional levers of oversight. These dimensions of oversight are impacted, and potentially reconfigured, by AI systems. We therefore suggest a broader lens of 'team-in-the-loop' to conceptualise the system-level analysis required for adoption of AI within high-stakes public sector deployment.
A multidomain relational framework to guide institutional AI research and adoption
Mar 17, 2023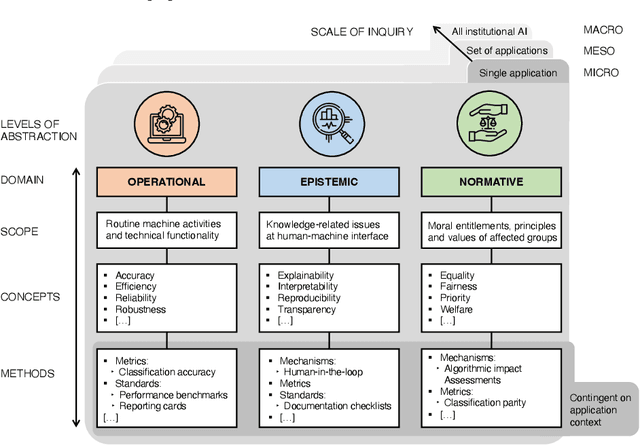
Calls for new metrics, technical standards and governance mechanisms to guide the adoption of Artificial Intelligence (AI) in institutions and public administration are now commonplace. Yet, most research and policy efforts aimed at understanding the implications of adopting AI tend to prioritize only a handful of ideas; they do not fully account for all the different perspectives and topics that are potentially relevant. In this position paper, we contend that this omission stems, in part, from what we call the relational problem in socio-technical discourse: fundamental ontological issues have not yet been settled-including semantic ambiguity, a lack of clear relations between concepts and differing standard terminologies. This contributes to the persistence of disparate modes of reasoning to assess institutional AI systems, and the prevalence of conceptual isolation in the fields that study them including ML, human factors, social science and policy. After developing this critique, we offer a way forward by proposing a simple policy and research design tool in the form of a conceptual framework to organize terms across fields-consisting of three horizontal domains for grouping relevant concepts and related methods: Operational, epistemic, and normative. We first situate this framework against the backdrop of recent socio-technical discourse at two premier academic venues, AIES and FAccT, before illustrating how developing suitable metrics, standards, and mechanisms can be aided by operationalizing relevant concepts in each of these domains. Finally, we outline outstanding questions for developing this relational approach to institutional AI research and adoption.