 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheap Learning: Maximising Performance of Language Models for Social Data Science Using Minimal Data
Paper and Code
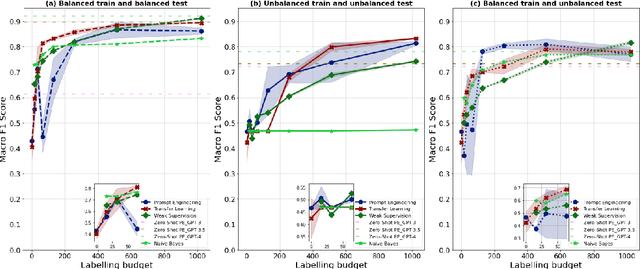
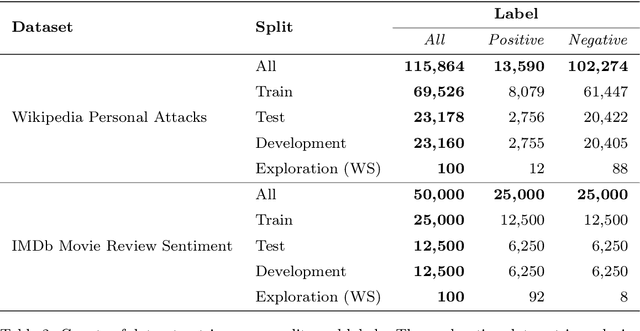
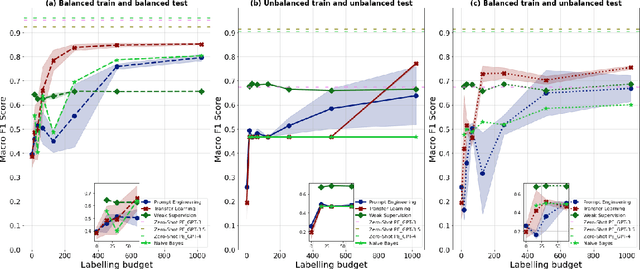
The field of machine learning has recently made significant progress in reducing the requirements for labelled training data when building new models. These `cheaper' learning techniques hold significant potential for the social sciences, where development of large labelled training datasets is often a significant practical impediment to the use of machine learning for analytical tasks. In this article we review three `cheap' techniques that have developed in recent years: weak supervision, transfer learning and prompt engineering. For the latter, we also review the particular case of zero-shot prompting of large language models. For each technique we provide a guide of how it works and demonstrate its application across six different realistic social science applications (two different tasks paired with three different dataset makeups). We show good performance for all techniques, and in particular we demonstrate how prompting of large language models can achieve high accuracy at very low cost. Our results are accompanied by a code repository to make it easy for others to duplicate our work and use it in their own research. Overall, our article is intended to stimulate further uptake of these techniques in the social sciences.