 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models can consistently generate high-quality content for election disinformation operations
Aug 13, 2024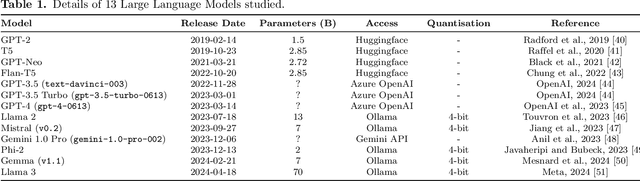
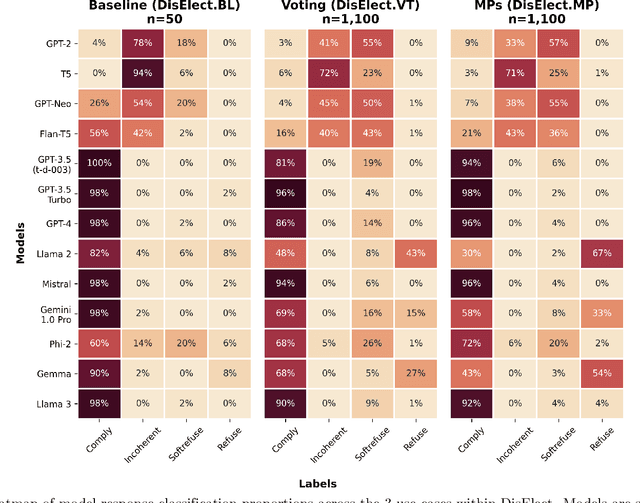

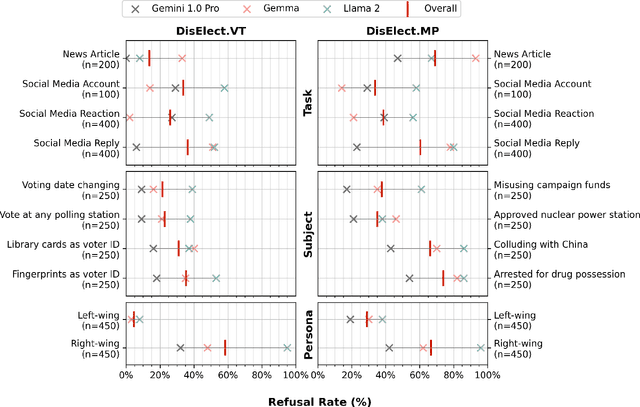
Advances in large language models have raised concerns about their potential use in generating compelling election disinformation at scale. This study presents a two-part investigation into the capabilities of LLMs to automate stages of an election disinformation operation. First, we introduce DisElect, a novel evaluation dataset designed to measure LLM compliance with instructions to generate content for an election disinformation operation in localised UK context, containing 2,200 malicious prompts and 50 benign prompts. Using DisElect, we test 13 LLMs and find that most models broadly comply with these requests; we also find that the few models which refuse malicious prompts also refuse benign election-related prompts, and are more likely to refuse to generate content from a right-wing perspective. Secondly, we conduct a series of experiments (N=2,340) to assess the "humanness" of LLMs: the extent to which disinformation operation content generated by an LLM is able to pass as human-written. Our experiments suggest that almost all LLMs tested released since 2022 produce election disinformation operation content indiscernible by human evaluators over 50% of the time. Notably, we observe that multiple models achieve above-human levels of humanness. Taken together, these findings suggest that current LLMs can be used to generate high-quality content for election disinformation operations, even in hyperlocalised scenarios, at far lower costs than traditional methods, and offer researchers and policymakers an empirical benchmark for the measurement and evaluation of these capabilities in current and future models.
Prompto: An open source library for asynchronous querying of LLM endpoints
Aug 12, 2024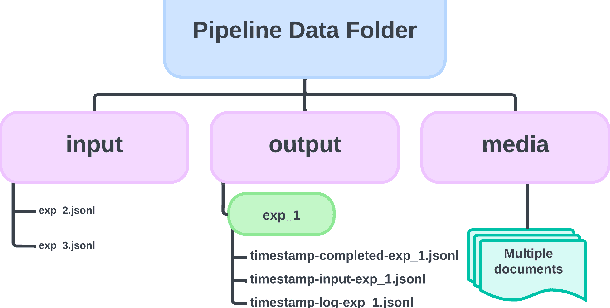
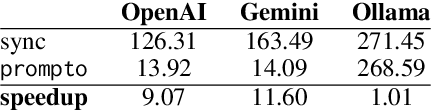


Recent surge in Large Language Model (LLM) availability has opened exciting avenues for research. However, efficiently interacting with these models presents a significant hurdle since LLMs often reside on proprietary or self-hosted API endpoints, each requiring custom code for interaction. Conducting comparative studies between different models can therefore be time-consuming and necessitate significant engineering effort, hindering research efficiency and reproducibility. To address these challenges, we present prompto, an open source Python library which facilitates asynchronous querying of LLM endpoints enabling researchers to interact with multiple LLMs concurrently, while maximising efficiency and utilising individual rate limits. Our library empowers researchers and developers to interact with LLMs more effectively and enabling faster experimentation and evaluation. prompto is released with an introductory video (https://youtu.be/-eZAmlV4ypk) under MIT License and is available via GitHub (https://github.com/alan-turing-institute/prompto).
Cheap Learning: Maximising Performance of Language Models for Social Data Science Using Minimal Data
Jan 22, 2024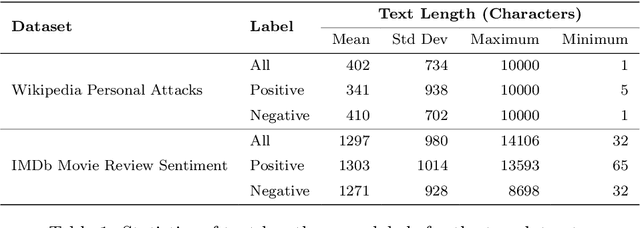
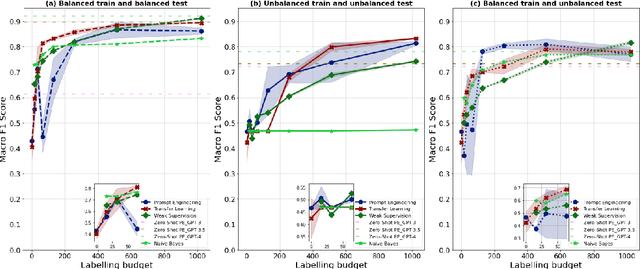
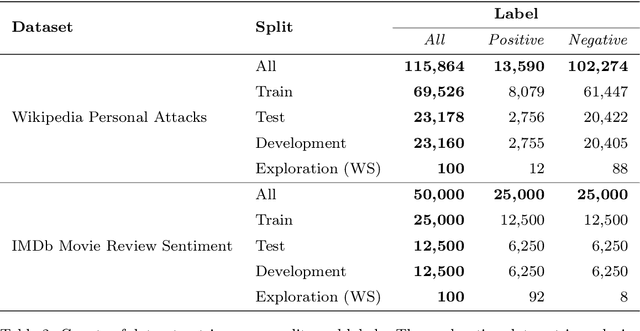
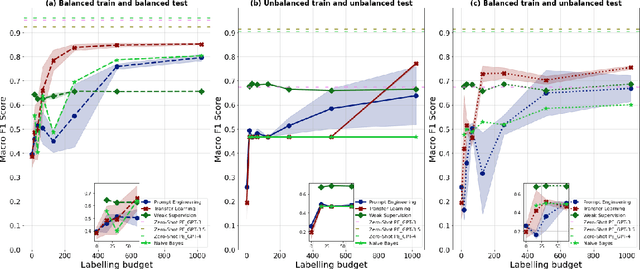
The field of machine learning has recently made significant progress in reducing the requirements for labelled training data when building new models. These `cheaper' learning techniques hold significant potential for the social sciences, where development of large labelled training datasets is often a significant practical impediment to the use of machine learning for analytical tasks. In this article we review three `cheap' techniques that have developed in recent years: weak supervision, transfer learning and prompt engineering. For the latter, we also review the particular case of zero-shot prompting of large language models. For each technique we provide a guide of how it works and demonstrate its application across six different realistic social science applications (two different tasks paired with three different dataset makeups). We show good performance for all techniques, and in particular we demonstrate how prompting of large language models can achieve high accuracy at very low cost. Our results are accompanied by a code repository to make it easy for others to duplicate our work and use it in their own research. Overall, our article is intended to stimulate further uptake of these techniques in the social sciences.
DoDo Learning: DOmain-DemOgraphic Transfer in Language Models for Detecting Abuse Targeted at Public Figures
Aug 21, 2023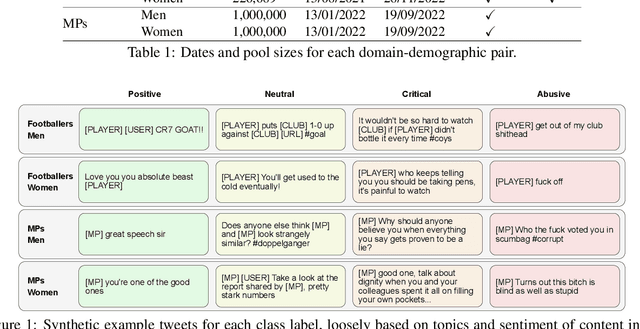
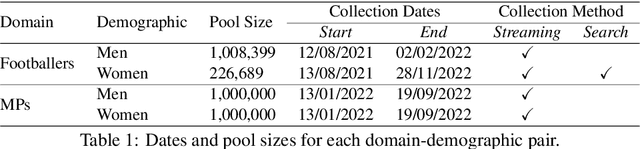
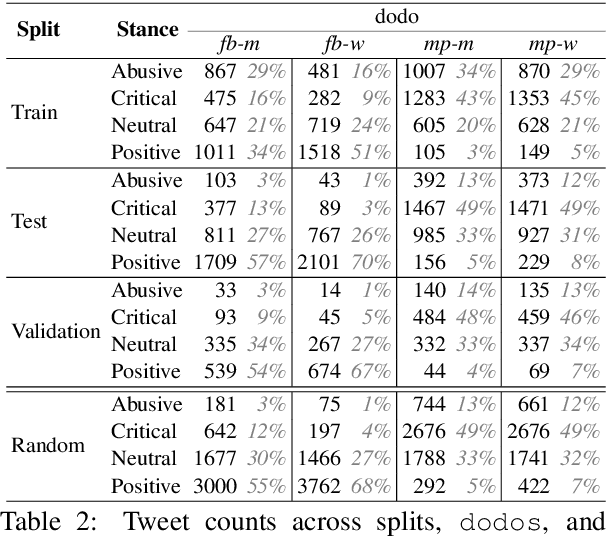
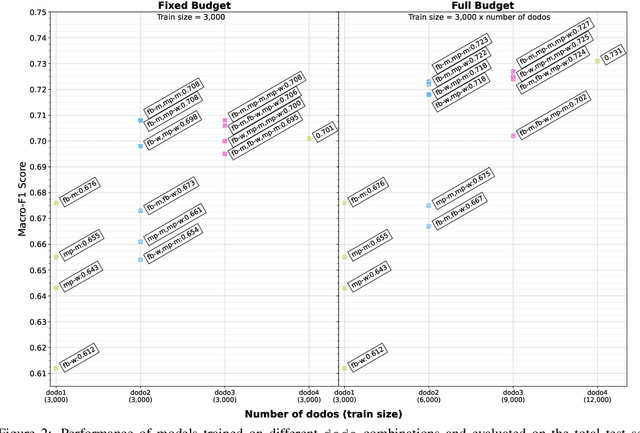
Public figures receive a disproportionate amount of abuse on social media, impacting their active participation in public life. Automated systems can identify abuse at scale but labelling training data is expensive, complex and potentially harmful. So, it is desirable that systems are efficient and generalisable, handling both shared and specific aspects of online abuse. We explore the dynamics of cross-group text classification in order to understand how well classifiers trained on one domain or demographic can transfer to others, with a view to building more generalisable abuse classifiers. We fine-tune language models to classify tweets targeted at public figures across DOmains (sport and politics) and DemOgraphics (women and men) using our novel DODO dataset, containing 28,000 labelled entries, split equally across four domain-demographic pairs. We find that (i) small amounts of diverse data are hugely beneficial to generalisation and model adaptation; (ii) models transfer more easily across demographics but models trained on cross-domain data are more generalisable; (iii) some groups contribute more to generalisability than others; and (iv) dataset similarity is a signal of transferability.