 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoDo Learning: DOmain-DemOgraphic Transfer in Language Models for Detecting Abuse Targeted at Public Figures
Paper and Code
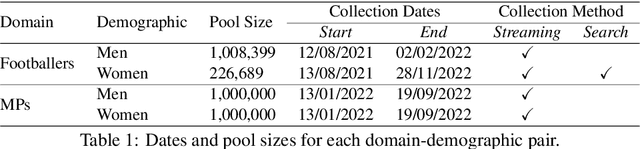
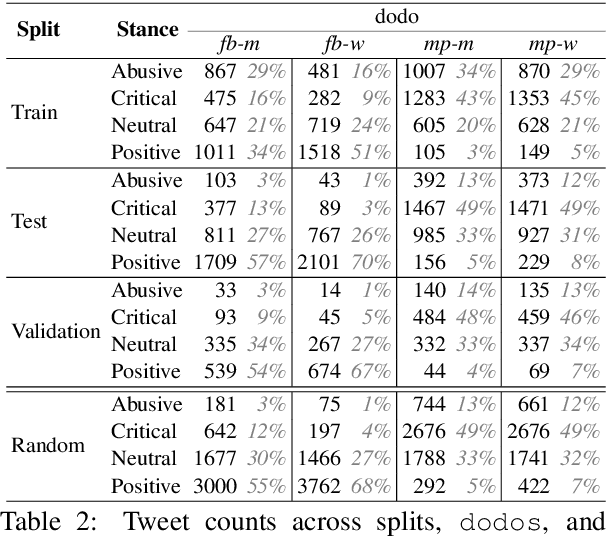
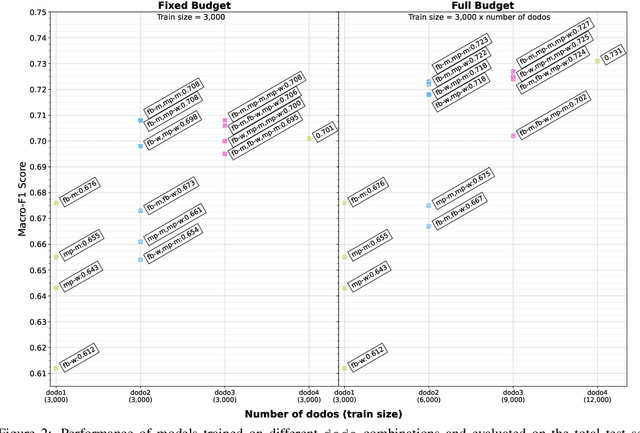
Public figures receive a disproportionate amount of abuse on social media, impacting their active participation in public life. Automated systems can identify abuse at scale but labelling training data is expensive, complex and potentially harmful. So, it is desirable that systems are efficient and generalisable, handling both shared and specific aspects of online abuse. We explore the dynamics of cross-group text classification in order to understand how well classifiers trained on one domain or demographic can transfer to others, with a view to building more generalisable abuse classifiers. We fine-tune language models to classify tweets targeted at public figures across DOmains (sport and politics) and DemOgraphics (women and men) using our novel DODO dataset, containing 28,000 labelled entries, split equally across four domain-demographic pairs. We find that (i) small amounts of diverse data are hugely beneficial to generalisation and model adaptation; (ii) models transfer more easily across demographics but models trained on cross-domain data are more generalisable; (iii) some groups contribute more to generalisability than others; and (iv) dataset similarity is a signal of transferability.