 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Like a Person Before Responding: A Multi-Faceted Evaluation of Persona-Guided LLMs for Countering Hate
Jun 04, 2025Automated counter-narratives (CN) offer a promising strategy for mitigating online hate speech, yet concerns about their affective tone, accessibility, and ethical risks remain. We propose a framework for evaluating Large Language Model (LLM)-generated CNs across four dimensions: persona framing, verbosity and readability, affective tone, and ethical robustness. Using GPT-4o-Mini, Cohere's CommandR-7B, and Meta's LLaMA 3.1-70B, we assess three prompting strategies on the MT-Conan and HatEval datasets. Our findings reveal that LLM-generated CNs are often verbose and adapted for people with college-level literacy, limiting their accessibility. While emotionally guided prompts yield more empathetic and readable responses, there remain concerns surrounding safety and effectiveness.
Beyond Translation: LLM-Based Data Generation for Multilingual Fact-Checking
Feb 21, 2025



Robust automatic fact-checking systems have the potential to combat online misinformation at scale. However, most existing research primarily focuses on English. In this paper, we introduce MultiSynFact, the first large-scale multilingual fact-checking dataset containing 2.2M claim-source pairs designed to support Spanish, German, English, and other low-resource languages. Our dataset generation pipeline leverages Large Language Models (LLMs), integrating external knowledge from Wikipedia and incorporating rigorous claim validation steps to ensure data quality. We evaluate the effectiveness of MultiSynFact across multiple models and experimental settings. Additionally, we open-source a user-friendly framework to facilitate further research in multilingual fact-checking and dataset generation.
Large language models can consistently generate high-quality content for election disinformation operations
Aug 13, 2024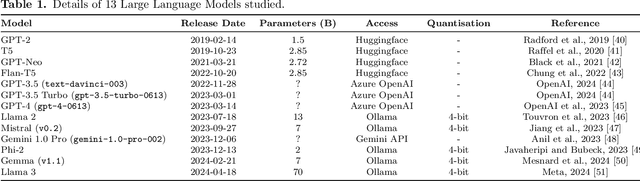
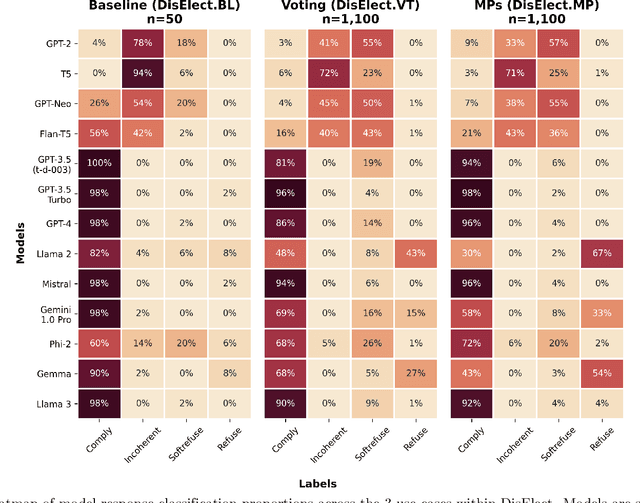

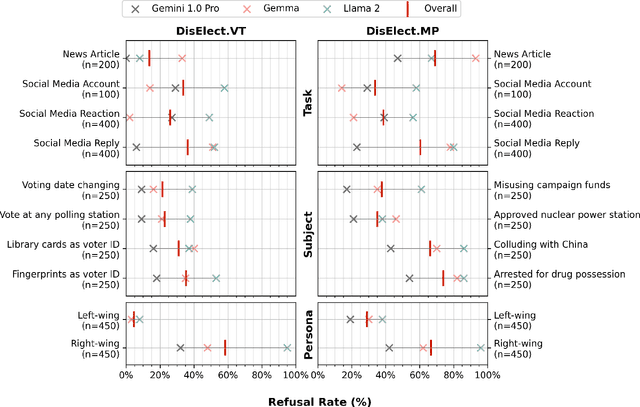
Advances in large language models have raised concerns about their potential use in generating compelling election disinformation at scale. This study presents a two-part investigation into the capabilities of LLMs to automate stages of an election disinformation operation. First, we introduce DisElect, a novel evaluation dataset designed to measure LLM compliance with instructions to generate content for an election disinformation operation in localised UK context, containing 2,200 malicious prompts and 50 benign prompts. Using DisElect, we test 13 LLMs and find that most models broadly comply with these requests; we also find that the few models which refuse malicious prompts also refuse benign election-related prompts, and are more likely to refuse to generate content from a right-wing perspective. Secondly, we conduct a series of experiments (N=2,340) to assess the "humanness" of LLMs: the extent to which disinformation operation content generated by an LLM is able to pass as human-written. Our experiments suggest that almost all LLMs tested released since 2022 produce election disinformation operation content indiscernible by human evaluators over 50% of the time. Notably, we observe that multiple models achieve above-human levels of humanness. Taken together, these findings suggest that current LLMs can be used to generate high-quality content for election disinformation operations, even in hyperlocalised scenarios, at far lower costs than traditional methods, and offer researchers and policymakers an empirical benchmark for the measurement and evaluation of these capabilities in current and future models.
NLP for Counterspeech against Hate: A Survey and How-To Guide
Mar 29, 2024In recent years, counterspeech has emerged as one of the most promising strategies to fight online hate. These non-escalatory responses tackle online abuse while preserving the freedom of speech of the users, and can have a tangible impact in reducing online and offline violence. Recently, there has been growing interest from the Natural Language Processing (NLP) community in addressing the challenges of analysing, collecting, classifying, and automatically generating counterspeech, to reduce the huge burden of manually producing it. In particular, researchers have taken different directions in addressing these challenges, thus providing a variety of related tasks and resources. In this paper, we provide a guide for doing research on counterspeech, by describing - with detailed examples - the steps to undertake, and providing best practices that can be learnt from the NLP studies on this topic. Finally, we discuss open challenges and future directions of counterspeech research in NLP.
Basque and Spanish Counter Narrative Generation: Data Creation and Evaluation
Mar 14, 2024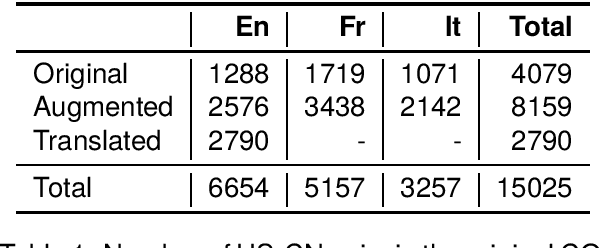
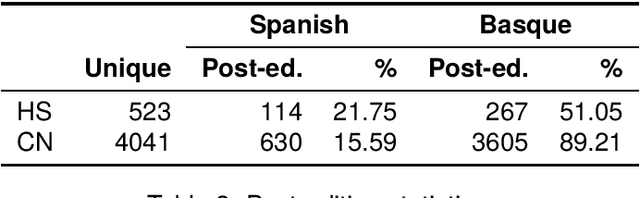
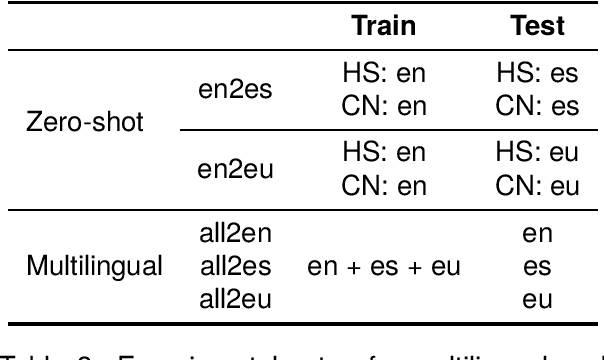
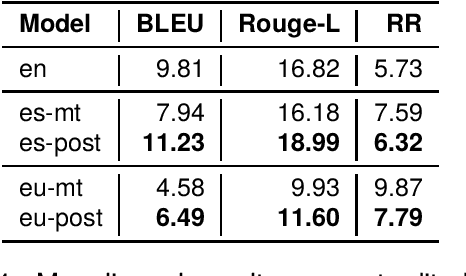
Counter Narratives (CNs) are non-negative textual responses to Hate Speech (HS) aiming at defusing online hatred and mitigating its spreading across media. Despite the recent increase in HS content posted online, research on automatic CN generation has been relatively scarce and predominantly focused on English. In this paper, we present CONAN-EUS, a new Basque and Spanish dataset for CN generation developed by means of Machine Translation (MT) and professional post-edition. Being a parallel corpus, also with respect to the original English CONAN, it allows to perform novel research on multilingual and crosslingual automatic generation of CNs. Our experiments on CN generation with mT5, a multilingual encoder-decoder model, show that generation greatly benefits from training on post-edited data, as opposed to relying on silver MT data only. These results are confirmed by their correlation with a qualitative manual evaluation, demonstrating that manually revised training data remains crucial for the quality of the generated CNs. Furthermore, multilingual data augmentation improves results over monolingual settings for structurally similar languages such as English and Spanish, while being detrimental for Basque, a language isolate. Similar findings occur in zero-shot crosslingual evaluations, where model transfer (fine-tuning in English and generating in a different target language) outperforms fine-tuning mT5 on machine translated data for Spanish but not for Basque. This provides an interesting insight into the asymmetry in the multilinguality of generative models, a challenging topic which is still open to research.
Cheap Learning: Maximising Performance of Language Models for Social Data Science Using Minimal Data
Jan 22, 2024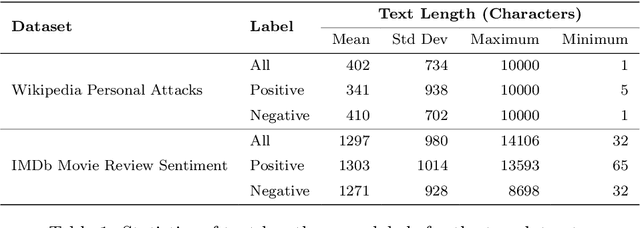
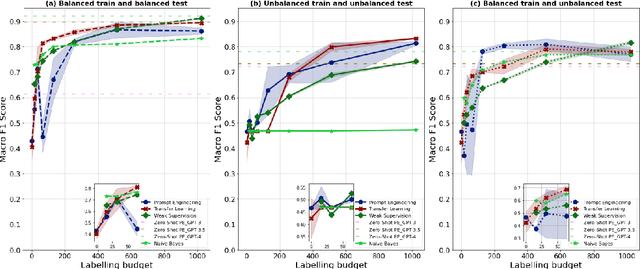
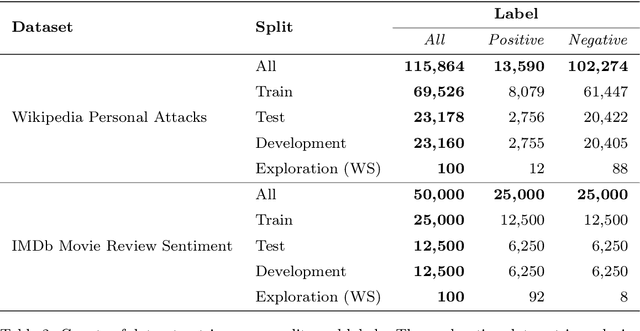
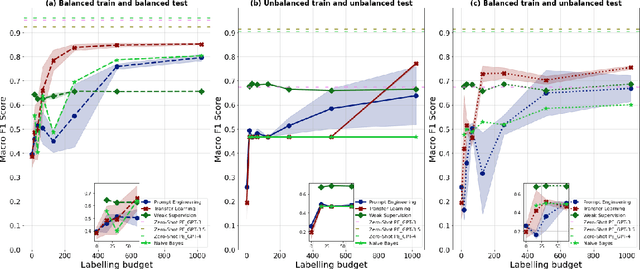
The field of machine learning has recently made significant progress in reducing the requirements for labelled training data when building new models. These `cheaper' learning techniques hold significant potential for the social sciences, where development of large labelled training datasets is often a significant practical impediment to the use of machine learning for analytical tasks. In this article we review three `cheap' techniques that have developed in recent years: weak supervision, transfer learning and prompt engineering. For the latter, we also review the particular case of zero-shot prompting of large language models. For each technique we provide a guide of how it works and demonstrate its application across six different realistic social science applications (two different tasks paired with three different dataset makeups). We show good performance for all techniques, and in particular we demonstrate how prompting of large language models can achieve high accuracy at very low cost. Our results are accompanied by a code repository to make it easy for others to duplicate our work and use it in their own research. Overall, our article is intended to stimulate further uptake of these techniques in the social sciences.
DoDo Learning: DOmain-DemOgraphic Transfer in Language Models for Detecting Abuse Targeted at Public Figures
Aug 21, 2023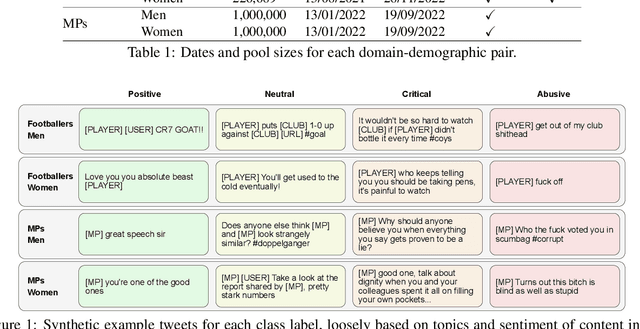
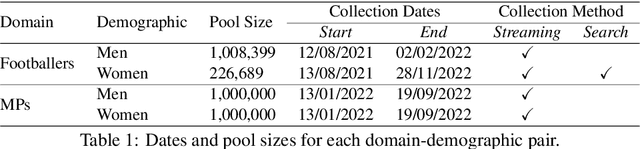
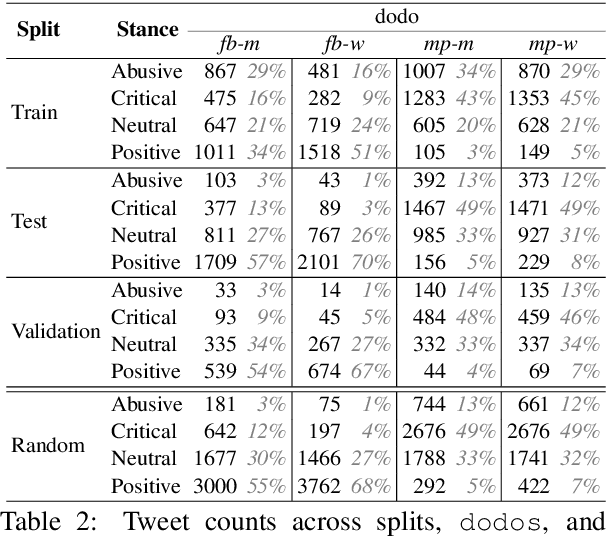
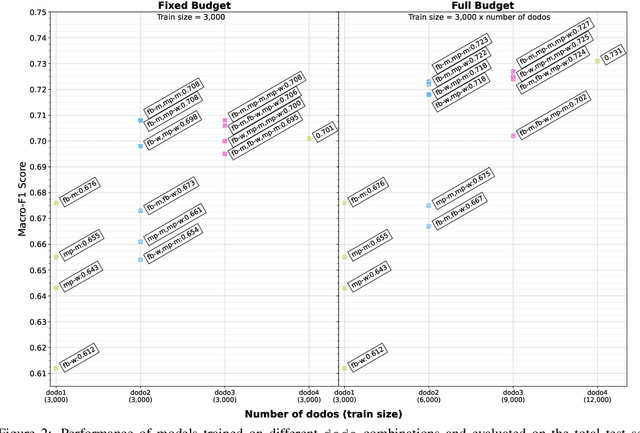
Public figures receive a disproportionate amount of abuse on social media, impacting their active participation in public life. Automated systems can identify abuse at scale but labelling training data is expensive, complex and potentially harmful. So, it is desirable that systems are efficient and generalisable, handling both shared and specific aspects of online abuse. We explore the dynamics of cross-group text classification in order to understand how well classifiers trained on one domain or demographic can transfer to others, with a view to building more generalisable abuse classifiers. We fine-tune language models to classify tweets targeted at public figures across DOmains (sport and politics) and DemOgraphics (women and men) using our novel DODO dataset, containing 28,000 labelled entries, split equally across four domain-demographic pairs. We find that (i) small amounts of diverse data are hugely beneficial to generalisation and model adaptation; (ii) models transfer more easily across demographics but models trained on cross-domain data are more generalisable; (iii) some groups contribute more to generalisability than others; and (iv) dataset similarity is a signal of transferability.
Understanding Counterspeech for Online Harm Mitigation
Jul 01, 2023Counterspeech offers direct rebuttals to hateful speech by challenging perpetrators of hate and showing support to targets of abuse. It provides a promising alternative to more contentious measures, such as content moderation and deplatforming, by contributing a greater amount of positive online speech rather than attempting to mitigate harmful content through removal. Advances in the development of large language models mean that the process of producing counterspeech could be made more efficient by automating its generation, which would enable large-scale online campaigns. However, we currently lack a systematic understanding of several important factors relating to the efficacy of counterspeech for hate mitigation, such as which types of counterspeech are most effective, what are the optimal conditions for implementation, and which specific effects of hate it can best ameliorate. This paper aims to fill this gap by systematically reviewing counterspeech research in the social sciences and comparing methodologies and findings with computer science efforts in automatic counterspeech generation. By taking this multi-disciplinary view, we identify promising future directions in both fields.
Multilingual Counter Narrative Type Classification
Sep 28, 2021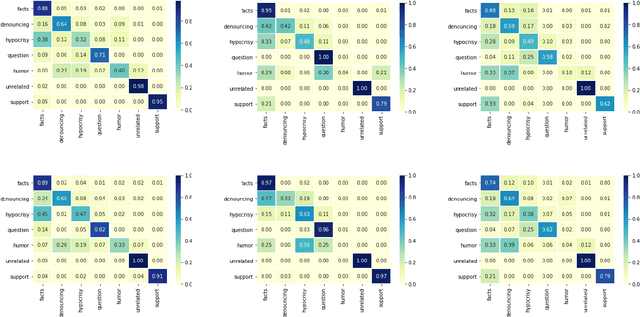

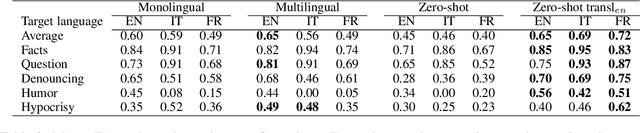

The growing interest in employing counter narratives for hatred intervention brings with it a focus on dataset creation and automation strategies. In this scenario, learning to recognize counter narrative types from natural text is expected to be useful for applications such as hate speech countering, where operators from non-governmental organizations are supposed to answer to hate with several and diverse arguments that can be mined from online sources. This paper presents the first multilingual work on counter narrative type classification, evaluating SoTA pre-trained language models in monolingual, multilingual and cross-lingual settings. When considering a fine-grained annotation of counter narrative classes, we report strong baseline classification results for the majority of the counter narrative types, especially if we translate every language to English before cross-lingual prediction. This suggests that knowledge about counter narratives can be successfully transferred across languages.
Empowering NGOs in Countering Online Hate Messages
Jul 06, 2021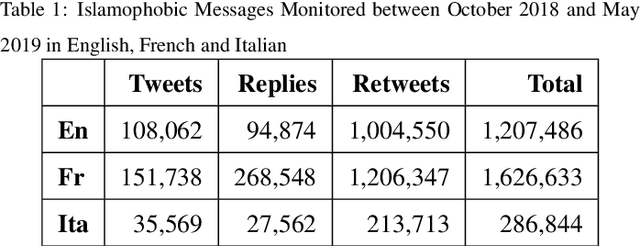
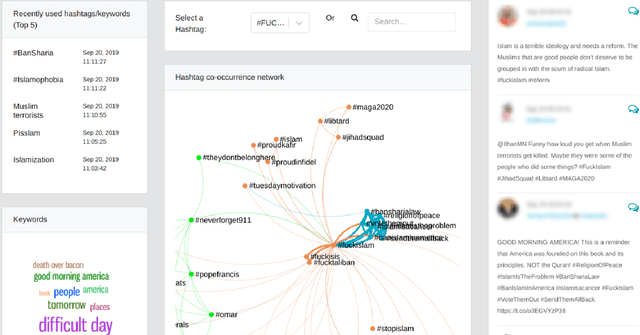
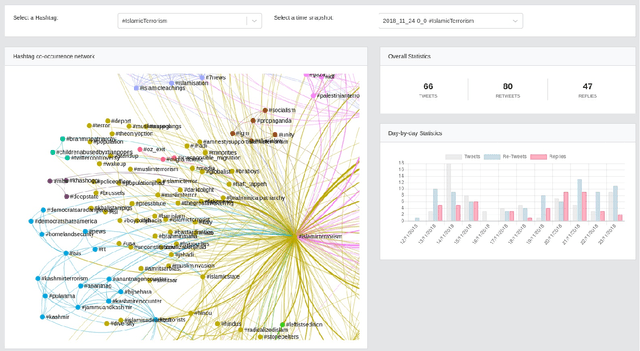
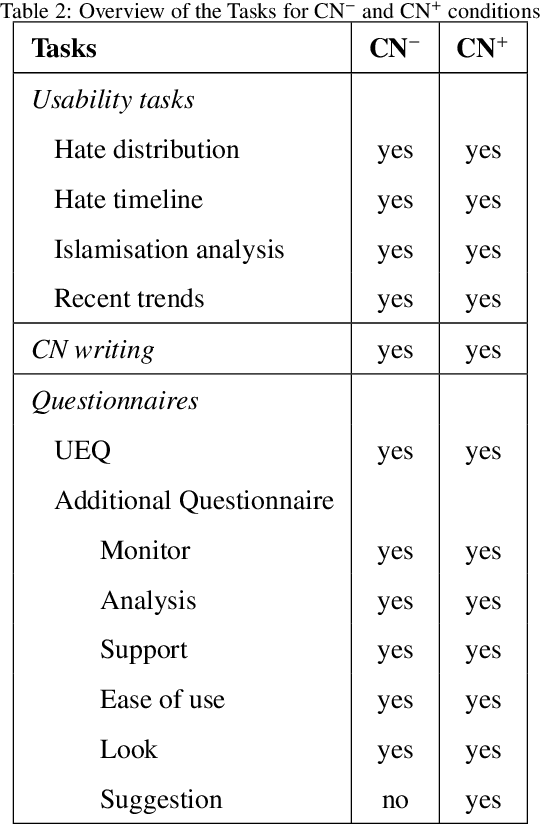
Studies on online hate speech have mostly focused on the automated detection of harmful messages. Little attention has been devoted so far to the development of effective strategies to fight hate speech, in particular through the creation of counter-messages. While existing manual scrutiny and intervention strategies are time-consuming and not scalable, advances in natural language processing have the potential to provide a systematic approach to hatred management. In this paper, we introduce a novel ICT platform that NGO operators can use to monitor and analyze social media data, along with a counter-narrative suggestion tool. Our platform aims at increasing the efficiency and effectiveness of operators' activities against islamophobia. We test the platform with more than one hundred NGO operators in three countries through qualitative and quantitative evaluation. Results show that NGOs favor the platform solution with the suggestion tool, and that the time required to produce counter-narratives significantly decreases.