 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRODIGy: a PROfile-based DIalogue Generation dataset
Nov 09, 2023
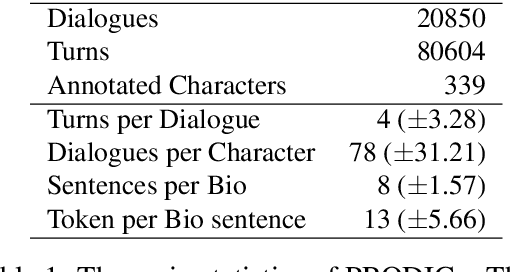


Providing dialogue agents with a profile representation can improve their consistency and coherence, leading to better conversations. However, current profile-based dialogue datasets for training such agents contain either explicit profile representations that are simple and dialogue-specific, or implicit representations that are difficult to collect. In this work, we propose a unified framework in which we bring together both standard and more sophisticated profile representations by creating a new resource where each dialogue is aligned with all possible speaker representations such as communication style, biographies, and personality. This framework allows to test several baselines built using generative language models with several profile configurations. The automatic evaluation shows that profile-based models have better generalisation capabilities than models trained on dialogues only, both in-domain and cross-domain settings. These results are consistent for fine-tuned models and instruction-based LLMs. Additionally, human evaluation demonstrates a clear preference for generations consistent with both profile and context. Finally, to account for possible privacy concerns, all experiments are done under two configurations: inter-character and intra-character. In the former, the LM stores the information about the character in its internal representation, while in the latter, the LM does not retain any personal information but uses it only at inference time.
Benchmarking the Generation of Fact Checking Explanations
Aug 29, 2023Fighting misinformation is a challenging, yet crucial, task. Despite the growing number of experts being involved in manual fact-checking, this activity is time-consuming and cannot keep up with the ever-increasing amount of Fake News produced daily. Hence, automating this process is necessary to help curb misinformation. Thus far, researchers have mainly focused on claim veracity classification. In this paper, instead, we address the generation of justifications (textual explanation of why a claim is classified as either true or false) and benchmark it with novel datasets and advanced baselines. In particular, we focus on summarization approaches over unstructured knowledge (i.e. news articles) and we experiment with several extractive and abstractive strategies. We employed two datasets with different styles and structures, in order to assess the generalizability of our findings. Results show that in justification production summarization benefits from the claim information, and, in particular, that a claim-driven extractive step improves abstractive summarization performances. Finally, we show that although cross-dataset experiments suffer from performance degradation, a unique model trained on a combination of the two datasets is able to retain style information in an efficient manner.
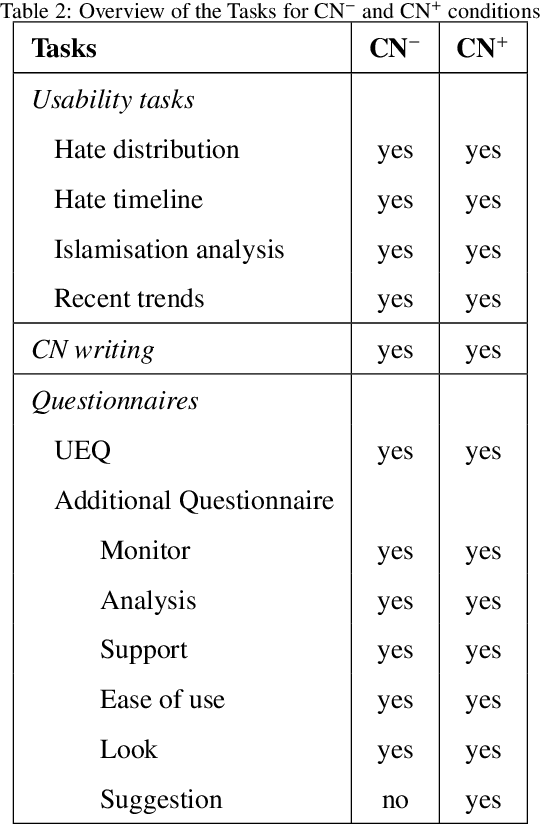
Human-Machine Collaboration Approaches to Build a Dialogue Dataset for Hate Speech Countering
Nov 07, 2022



Fighting online hate speech is a challenge that is usually addressed using Natural Language Processing via automatic detection and removal of hate content. Besides this approach, counter narratives have emerged as an effective tool employed by NGOs to respond to online hate on social media platforms. For this reason, Natural Language Generation is currently being studied as a way to automatize counter narrative writing. However, the existing resources necessary to train NLG models are limited to 2-turn interactions (a hate speech and a counter narrative as response), while in real life, interactions can consist of multiple turns. In this paper, we present a hybrid approach for dialogical data collection, which combines the intervention of human expert annotators over machine generated dialogues obtained using 19 different configurations. The result of this work is DIALOCONAN, the first dataset comprising over 3000 fictitious multi-turn dialogues between a hater and an NGO operator, covering 6 targets of hate.
Using Pre-Trained Language Models for Producing Counter Narratives Against Hate Speech: a Comparative Study
Apr 04, 2022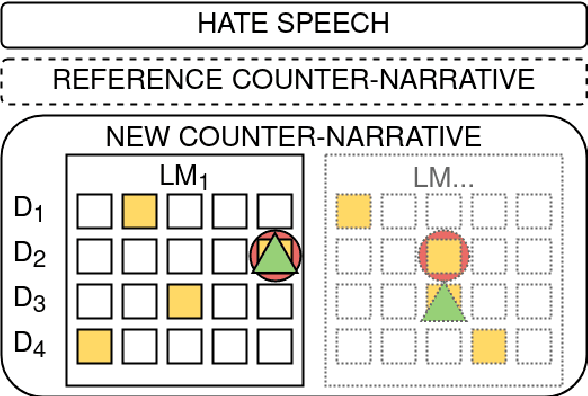


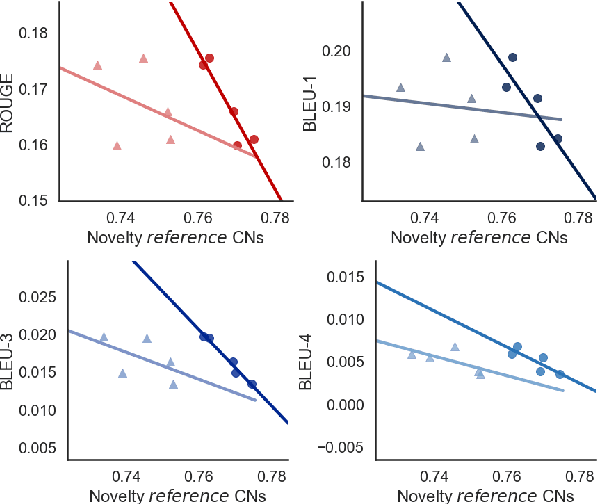
In this work, we present an extensive study on the use of pre-trained language models for the task of automatic Counter Narrative (CN) generation to fight online hate speech in English. We first present a comparative study to determine whether there is a particular Language Model (or class of LMs) and a particular decoding mechanism that are the most appropriate to generate CNs. Findings show that autoregressive models combined with stochastic decodings are the most promising. We then investigate how an LM performs in generating a CN with regard to an unseen target of hate. We find out that a key element for successful `out of target' experiments is not an overall similarity with the training data but the presence of a specific subset of training data, i.e. a target that shares some commonalities with the test target that can be defined a-priori. We finally introduce the idea of a pipeline based on the addition of an automatic post-editing step to refine generated CNs.
Human-in-the-Loop for Data Collection: a Multi-Target Counter Narrative Dataset to Fight Online Hate Speech
Jul 19, 2021
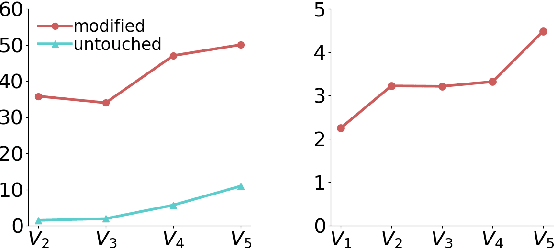
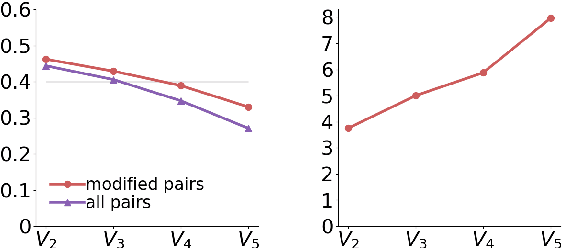
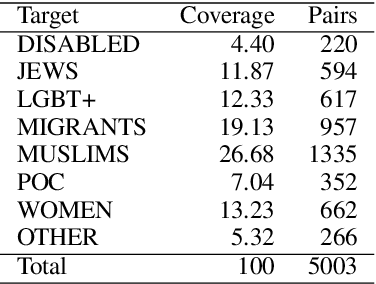
Undermining the impact of hateful content with informed and non-aggressive responses, called counter narratives, has emerged as a possible solution for having healthier online communities. Thus, some NLP studies have started addressing the task of counter narrative generation. Although such studies have made an effort to build hate speech / counter narrative (HS/CN) datasets for neural generation, they fall short in reaching either high-quality and/or high-quantity. In this paper, we propose a novel human-in-the-loop data collection methodology in which a generative language model is refined iteratively by using its own data from the previous loops to generate new training samples that experts review and/or post-edit. Our experiments comprised several loops including dynamic variations. Results show that the methodology is scalable and facilitates diverse, novel, and cost-effective data collection. To our knowledge, the resulting dataset is the only expert-based multi-target HS/CN dataset available to the community.
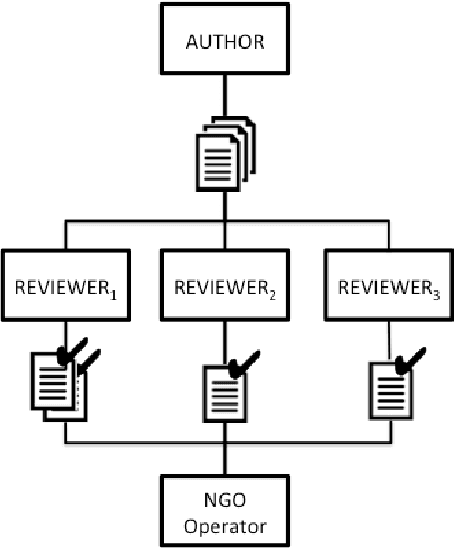
Empowering NGOs in Countering Online Hate Messages
Jul 06, 2021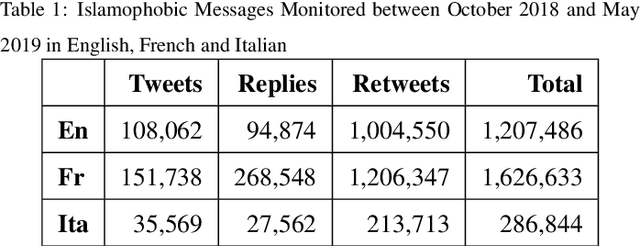
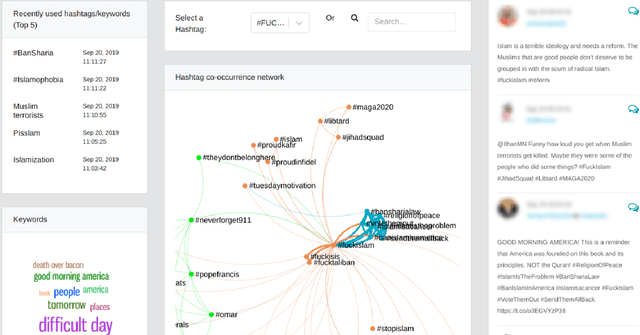
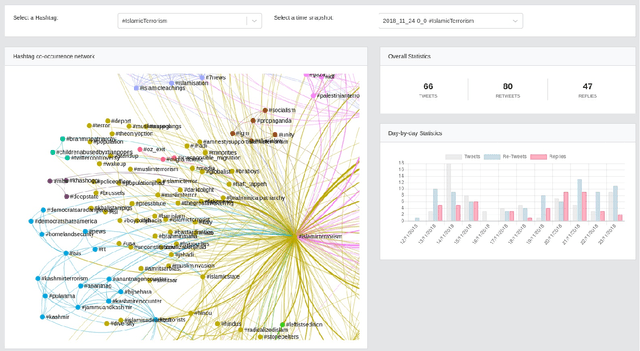
Studies on online hate speech have mostly focused on the automated detection of harmful messages. Little attention has been devoted so far to the development of effective strategies to fight hate speech, in particular through the creation of counter-messages. While existing manual scrutiny and intervention strategies are time-consuming and not scalable, advances in natural language processing have the potential to provide a systematic approach to hatred management. In this paper, we introduce a novel ICT platform that NGO operators can use to monitor and analyze social media data, along with a counter-narrative suggestion tool. Our platform aims at increasing the efficiency and effectiveness of operators' activities against islamophobia. We test the platform with more than one hundred NGO operators in three countries through qualitative and quantitative evaluation. Results show that NGOs favor the platform solution with the suggestion tool, and that the time required to produce counter-narratives significantly decreases.
Towards Knowledge-Grounded Counter Narrative Generation for Hate Speech
Jun 22, 2021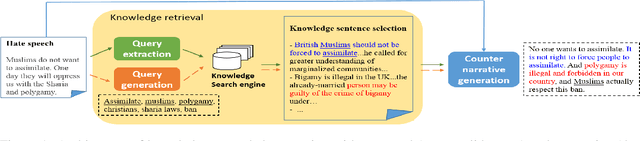


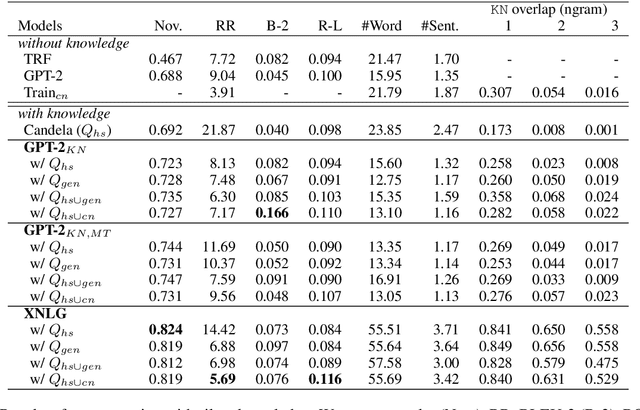
Tackling online hatred using informed textual responses - called counter narratives - has been brought under the spotlight recently. Accordingly, a research line has emerged to automatically generate counter narratives in order to facilitate the direct intervention in the hate discussion and to prevent hate content from further spreading. Still, current neural approaches tend to produce generic/repetitive responses and lack grounded and up-to-date evidence such as facts, statistics, or examples. Moreover, these models can create plausible but not necessarily true arguments. In this paper we present the first complete knowledge-bound counter narrative generation pipeline, grounded in an external knowledge repository that can provide more informative content to fight online hatred. Together with our approach, we present a series of experiments that show its feasibility to produce suitable and informative counter narratives in in-domain and cross-domain settings.
Toward Stance-based Personas for Opinionated Dialogues
Oct 07, 2020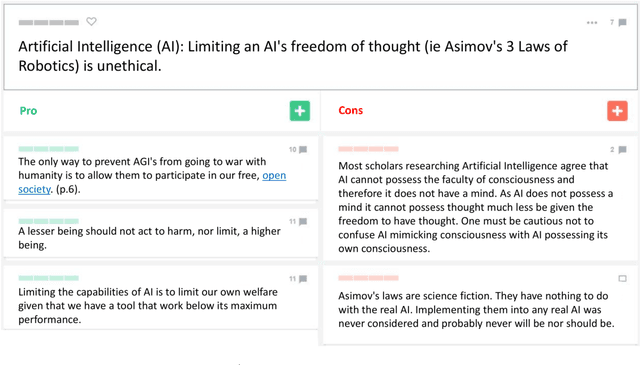


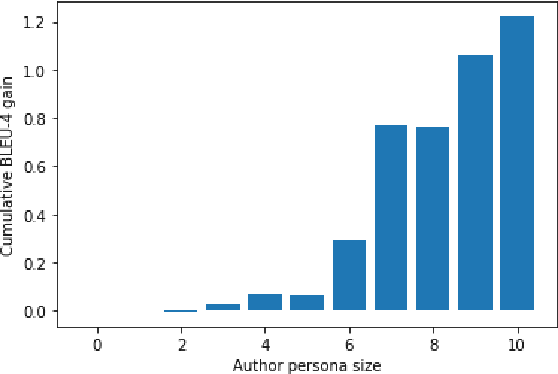
In the context of chit-chat dialogues it has been shown that endowing systems with a persona profile is important to produce more coherent and meaningful conversations. Still, the representation of such personas has thus far been limited to a fact-based representation (e.g. "I have two cats."). We argue that these representations remain superficial w.r.t. the complexity of human personality. In this work, we propose to make a step forward and investigate stance-based persona, trying to grasp more profound characteristics, such as opinions, values, and beliefs to drive language generation. To this end, we introduce a novel dataset allowing to explore different stance-based persona representations and their impact on claim generation, showing that they are able to grasp abstract and profound aspects of the author persona.
Generating Counter Narratives against Online Hate Speech: Data and Strategies
Apr 08, 2020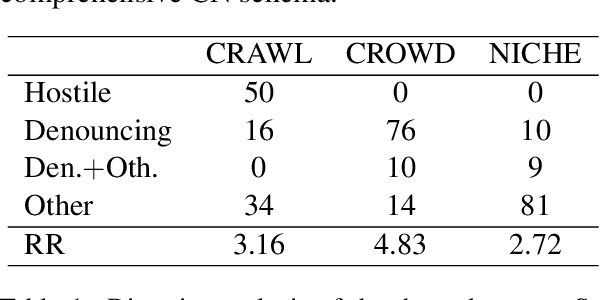

Recently research has started focusing on avoiding undesired effects that come with content moderation, such as censorship and overblocking, when dealing with hatred online. The core idea is to directly intervene in the discussion with textual responses that are meant to counter the hate content and prevent it from further spreading. Accordingly, automation strategies, such as natural language generation, are beginning to be investigated. Still, they suffer from the lack of sufficient amount of quality data and tend to produce generic/repetitive responses. Being aware of the aforementioned limitations, we present a study on how to collect responses to hate effectively, employing large scale unsupervised language models such as GPT-2 for the generation of silver data, and the best annotation strategies/neural architectures that can be used for data filtering before expert validation/post-editing.
Generating Challenge Datasets for Task-Oriented Conversational Agents through Self-Play
Oct 16, 2019



End-to-end neural approaches are becoming increasingly common in conversational scenarios due to their promising performances when provided with sufficient amount of data. In this paper, we present a novel methodology to address the interpretability of neural approaches in such scenarios by creating challenge datasets using dialogue self-play over multiple tasks/intents. Dialogue self-play allows generating large amount of synthetic data; by taking advantage of the complete control over the generation process, we show how neural approaches can be evaluated in terms of unseen dialogue patterns. We propose several out-of-pattern test cases each of which introduces a natural and unexpected user utterance phenomenon. As a proof of concept, we built a single and a multiple memory network, and show that these two architectures have diverse performances depending on the peculiar dialogue patterns.