 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Pre-Trained Language Models for Producing Counter Narratives Against Hate Speech: a Comparative Study
Paper and Code
Apr 04, 2022


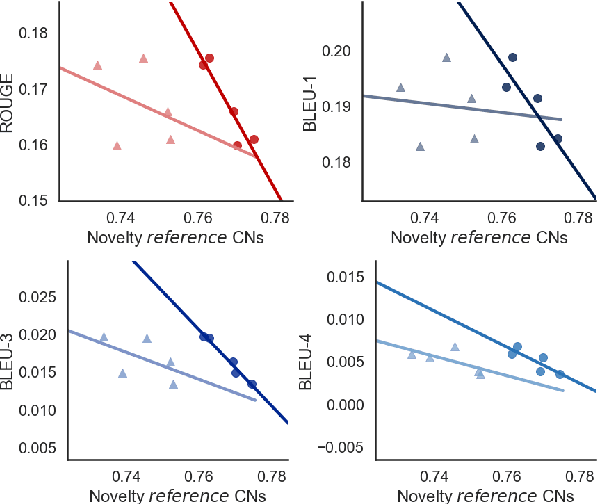
In this work, we present an extensive study on the use of pre-trained language models for the task of automatic Counter Narrative (CN) generation to fight online hate speech in English. We first present a comparative study to determine whether there is a particular Language Model (or class of LMs) and a particular decoding mechanism that are the most appropriate to generate CNs. Findings show that autoregressive models combined with stochastic decodings are the most promising. We then investigate how an LM performs in generating a CN with regard to an unseen target of hate. We find out that a key element for successful `out of target' experiments is not an overall similarity with the training data but the presence of a specific subset of training data, i.e. a target that shares some commonalities with the test target that can be defined a-priori. We finally introduce the idea of a pipeline based on the addition of an automatic post-editing step to refine generated CNs.