 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATCH-ME if you RAG: a dataset of Contextually Annotated multi-Turn Counterspeech against Hate and Misinformation Exchanges
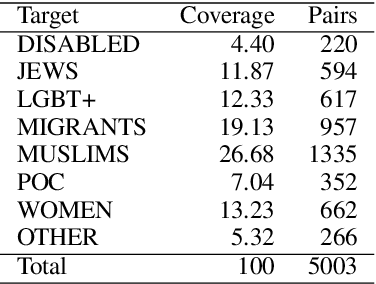
Jun 18, 2026Online hate speech and misinformation frequently overlap, yet NLP research has mainly treated them in isolation. While LLMs represent a scalable solution for assisting humans in the generation of counterspeech for both threats, zero-shot models frequently generate repetitive and vague responses, underscoring the need for high-quality examples to steer model generation. However, existing counterspeech datasets against the overlap of hate and misinformation are scarce and limited to single-turn English dialogues, while real-life interactions span across multiple turns and languages. To bridge this gap, we introduce the first large-scale, expert-curated, multilingual dataset of dialogues tackling the intersection of hate and misinformation. To ensure factual grounding, the dialogues are also anchored in verified external knowledge (i.e., fact-checking articles and NGO reports) and include document- and chunk-level span annotations, making it directly applicable for RAG systems. Covering five languages and targeting hate directed at seven marginalized groups, this novel resource enables the training and evaluation of more persuasive, factually grounded counterspeech models.
Assisted Counterspeech Writing at the Crossroads of Hate Speech and Misinformation
May 21, 2026Hate speech and misinformation frequently co-occur online, amplifying prejudice and polarization. Given their scale, using Large Language Models (LLMs) to assist expert counterspeech (CS) writing has gained interest, yet prior work has addressed these phenomena separately. We bridge this gap by studying CS generation in contexts where both hate and misinformation co-occur. We test three knowledge-driven generation strategies: first we prompt an LLM with fact-checkers' guidelines and fact-checking articles; secondly, with NGOs' guidelines and reports; thirdly, we create a mixed strategy that combines guidelines and documents from both. 23 experts revise the generated CS, which are assessed via human and automatic metrics. While LLMs produce adequate CS in 40% of cases, expert edits substantially improve naturalness, exhaustiveness, and adherence to guidelines. Based on the post-edited CS, the mixed strategy proves to be the most effective in crowdsourcing evaluation, pairing strong factual correction with stereotype mitigation and empathetic engagement. We release a dataset of hateful and misinformed claims with expert-verified CS and supporting knowledge.
Is Safer Better? The Impact of Guardrails on the Argumentative Strength of LLMs in Hate Speech Countering
Oct 04, 2024The potential effectiveness of counterspeech as a hate speech mitigation strategy is attracting increasing interest in the NLG research community, particularly towards the task of automatically producing it. However, automatically generated responses often lack the argumentative richness which characterises expert-produced counterspeech. In this work, we focus on two aspects of counterspeech generation to produce more cogent responses. First, by investigating the tension between helpfulness and harmlessness of LLMs, we test whether the presence of safety guardrails hinders the quality of the generations. Secondly, we assess whether attacking a specific component of the hate speech results in a more effective argumentative strategy to fight online hate. By conducting an extensive human and automatic evaluation, we show how the presence of safety guardrails can be detrimental also to a task that inherently aims at fostering positive social interactions. Moreover, our results show that attacking a specific component of the hate speech, and in particular its implicit negative stereotype and its hateful parts, leads to higher-quality generations.
NLP for Counterspeech against Hate: A Survey and How-To Guide
Mar 29, 2024



In recent years, counterspeech has emerged as one of the most promising strategies to fight online hate. These non-escalatory responses tackle online abuse while preserving the freedom of speech of the users, and can have a tangible impact in reducing online and offline violence. Recently, there has been growing interest from the Natural Language Processing (NLP) community in addressing the challenges of analysing, collecting, classifying, and automatically generating counterspeech, to reduce the huge burden of manually producing it. In particular, researchers have taken different directions in addressing these challenges, thus providing a variety of related tasks and resources. In this paper, we provide a guide for doing research on counterspeech, by describing - with detailed examples - the steps to undertake, and providing best practices that can be learnt from the NLP studies on this topic. Finally, we discuss open challenges and future directions of counterspeech research in NLP.
Weigh Your Own Words: Improving Hate Speech Counter Narrative Generation via Attention Regularization
Sep 05, 2023



Recent computational approaches for combating online hate speech involve the automatic generation of counter narratives by adapting Pretrained Transformer-based Language Models (PLMs) with human-curated data. This process, however, can produce in-domain overfitting, resulting in models generating acceptable narratives only for hatred similar to training data, with little portability to other targets or to real-world toxic language. This paper introduces novel attention regularization methodologies to improve the generalization capabilities of PLMs for counter narratives generation. Overfitting to training-specific terms is then discouraged, resulting in more diverse and richer narratives. We experiment with two attention-based regularization techniques on a benchmark English dataset. Regularized models produce better counter narratives than state-of-the-art approaches in most cases, both in terms of automatic metrics and human evaluation, especially when hateful targets are not present in the training data. This work paves the way for better and more flexible counter-speech generation models, a task for which datasets are highly challenging to produce.
Human-Machine Collaboration Approaches to Build a Dialogue Dataset for Hate Speech Countering
Nov 07, 2022



Fighting online hate speech is a challenge that is usually addressed using Natural Language Processing via automatic detection and removal of hate content. Besides this approach, counter narratives have emerged as an effective tool employed by NGOs to respond to online hate on social media platforms. For this reason, Natural Language Generation is currently being studied as a way to automatize counter narrative writing. However, the existing resources necessary to train NLG models are limited to 2-turn interactions (a hate speech and a counter narrative as response), while in real life, interactions can consist of multiple turns. In this paper, we present a hybrid approach for dialogical data collection, which combines the intervention of human expert annotators over machine generated dialogues obtained using 19 different configurations. The result of this work is DIALOCONAN, the first dataset comprising over 3000 fictitious multi-turn dialogues between a hater and an NGO operator, covering 6 targets of hate.
Using Pre-Trained Language Models for Producing Counter Narratives Against Hate Speech: a Comparative Study
Apr 04, 2022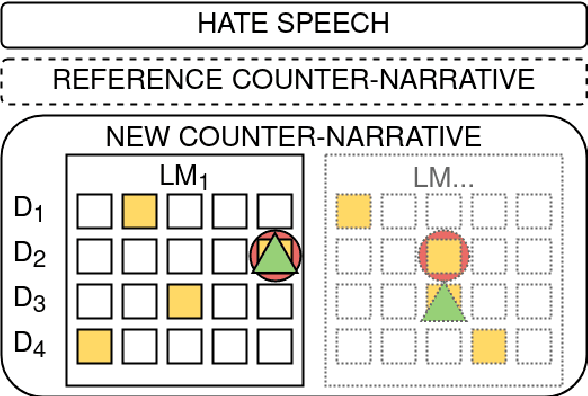


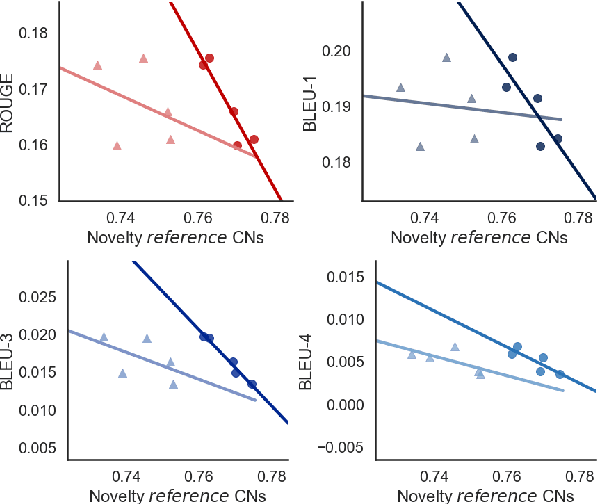
In this work, we present an extensive study on the use of pre-trained language models for the task of automatic Counter Narrative (CN) generation to fight online hate speech in English. We first present a comparative study to determine whether there is a particular Language Model (or class of LMs) and a particular decoding mechanism that are the most appropriate to generate CNs. Findings show that autoregressive models combined with stochastic decodings are the most promising. We then investigate how an LM performs in generating a CN with regard to an unseen target of hate. We find out that a key element for successful `out of target' experiments is not an overall similarity with the training data but the presence of a specific subset of training data, i.e. a target that shares some commonalities with the test target that can be defined a-priori. We finally introduce the idea of a pipeline based on the addition of an automatic post-editing step to refine generated CNs.
Human-in-the-Loop for Data Collection: a Multi-Target Counter Narrative Dataset to Fight Online Hate Speech
Jul 19, 2021
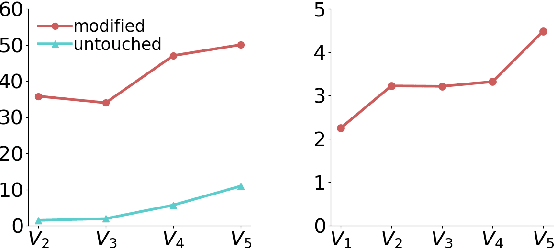
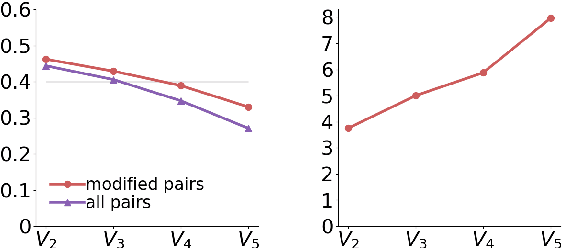
Undermining the impact of hateful content with informed and non-aggressive responses, called counter narratives, has emerged as a possible solution for having healthier online communities. Thus, some NLP studies have started addressing the task of counter narrative generation. Although such studies have made an effort to build hate speech / counter narrative (HS/CN) datasets for neural generation, they fall short in reaching either high-quality and/or high-quantity. In this paper, we propose a novel human-in-the-loop data collection methodology in which a generative language model is refined iteratively by using its own data from the previous loops to generate new training samples that experts review and/or post-edit. Our experiments comprised several loops including dynamic variations. Results show that the methodology is scalable and facilitates diverse, novel, and cost-effective data collection. To our knowledge, the resulting dataset is the only expert-based multi-target HS/CN dataset available to the community.