 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Pre-Trained Language Models for Producing Counter Narratives Against Hate Speech: a Comparative Study
Apr 04, 2022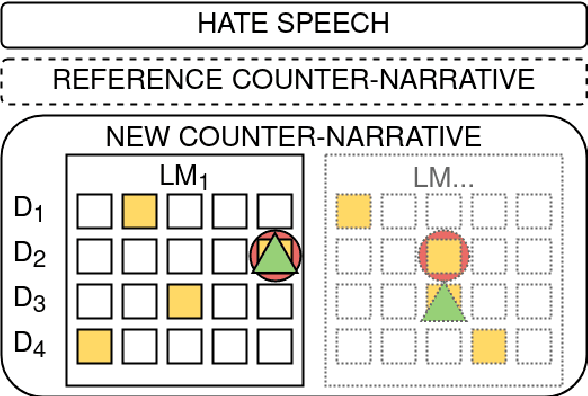


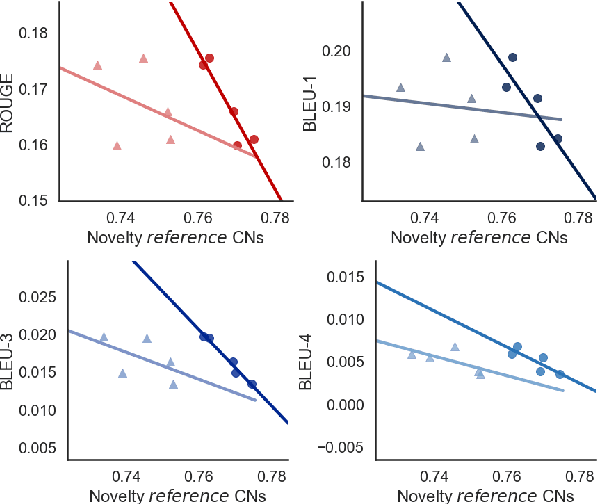
In this work, we present an extensive study on the use of pre-trained language models for the task of automatic Counter Narrative (CN) generation to fight online hate speech in English. We first present a comparative study to determine whether there is a particular Language Model (or class of LMs) and a particular decoding mechanism that are the most appropriate to generate CNs. Findings show that autoregressive models combined with stochastic decodings are the most promising. We then investigate how an LM performs in generating a CN with regard to an unseen target of hate. We find out that a key element for successful `out of target' experiments is not an overall similarity with the training data but the presence of a specific subset of training data, i.e. a target that shares some commonalities with the test target that can be defined a-priori. We finally introduce the idea of a pipeline based on the addition of an automatic post-editing step to refine generated CNs.
Human-in-the-Loop for Data Collection: a Multi-Target Counter Narrative Dataset to Fight Online Hate Speech
Jul 19, 2021
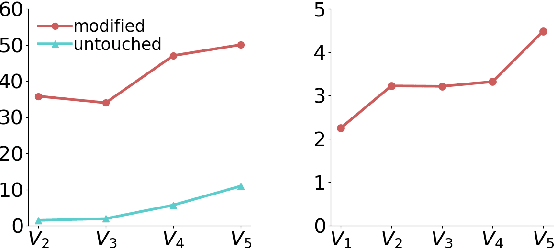
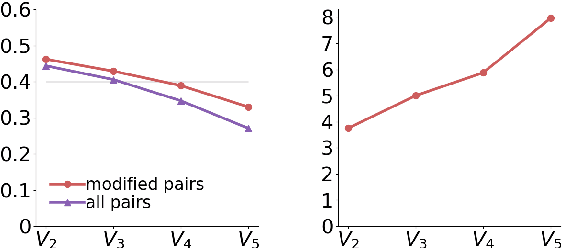
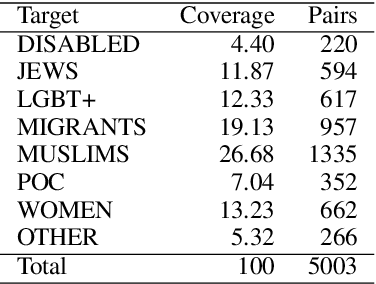
Undermining the impact of hateful content with informed and non-aggressive responses, called counter narratives, has emerged as a possible solution for having healthier online communities. Thus, some NLP studies have started addressing the task of counter narrative generation. Although such studies have made an effort to build hate speech / counter narrative (HS/CN) datasets for neural generation, they fall short in reaching either high-quality and/or high-quantity. In this paper, we propose a novel human-in-the-loop data collection methodology in which a generative language model is refined iteratively by using its own data from the previous loops to generate new training samples that experts review and/or post-edit. Our experiments comprised several loops including dynamic variations. Results show that the methodology is scalable and facilitates diverse, novel, and cost-effective data collection. To our knowledge, the resulting dataset is the only expert-based multi-target HS/CN dataset available to the community.