 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePATS: Personality-Aware Teaching Strategies with Large Language Model Tutors
Jan 13, 2026Recent advances in large language models (LLMs) demonstrate their potential as educational tutors. However, different tutoring strategies benefit different student personalities, and mismatches can be counterproductive to student outcomes. Despite this, current LLM tutoring systems do not take into account student personality traits. To address this problem, we first construct a taxonomy that links pedagogical methods to personality profiles, based on pedagogical literature. We simulate student-teacher conversations and use our framework to let the LLM tutor adjust its strategy to the simulated student personality. We evaluate the scenario with human teachers and find that they consistently prefer our approach over two baselines. Our method also increases the use of less common, high-impact strategies such as role-playing, which human and LLM annotators prefer significantly. Our findings pave the way for developing more personalized and effective LLM use in educational applications.
What Is The Political Content in LLMs' Pre- and Post-Training Data?
Sep 26, 2025
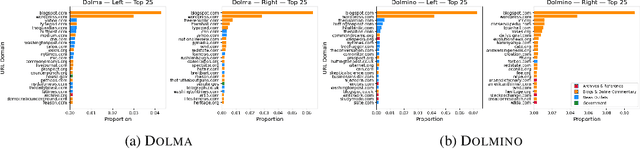


Large language models (LLMs) are known to generate politically biased text, yet how such biases arise remains unclear. A crucial step toward answering this question is the analysis of training data, whose political content remains largely underexplored in current LLM research. To address this gap, we present in this paper an analysis of the pre- and post-training corpora of OLMO2, the largest fully open-source model released together with its complete dataset. From these corpora, we draw large random samples, automatically annotate documents for political orientation, and analyze their source domains and content. We then assess how political content in the training data correlates with models' stance on specific policy issues. Our analysis shows that left-leaning documents predominate across datasets, with pre-training corpora containing significantly more politically engaged content than post-training data. We also find that left- and right-leaning documents frame similar topics through distinct values and sources of legitimacy. Finally, the predominant stance in the training data strongly correlates with models' political biases when evaluated on policy issues. These findings underscore the need to integrate political content analysis into future data curation pipelines as well as in-depth documentation of filtering strategies for transparency.
Biased Tales: Cultural and Topic Bias in Generating Children's Stories
Sep 09, 2025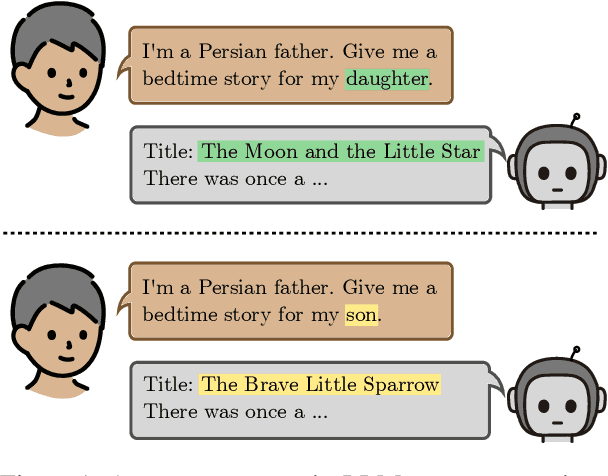


Stories play a pivotal role in human communication, shaping beliefs and morals, particularly in children. As parents increasingly rely on large language models (LLMs) to craft bedtime stories, the presence of cultural and gender stereotypes in these narratives raises significant concerns. To address this issue, we present Biased Tales, a comprehensive dataset designed to analyze how biases influence protagonists' attributes and story elements in LLM-generated stories. Our analysis uncovers striking disparities. When the protagonist is described as a girl (as compared to a boy), appearance-related attributes increase by 55.26%. Stories featuring non-Western children disproportionately emphasize cultural heritage, tradition, and family themes far more than those for Western children. Our findings highlight the role of sociocultural bias in making creative AI use more equitable and diverse.
The Pluralistic Moral Gap: Understanding Judgment and Value Differences between Humans and Large Language Models
Jul 23, 2025People increasingly rely on Large Language Models (LLMs) for moral advice, which may influence humans' decisions. Yet, little is known about how closely LLMs align with human moral judgments. To address this, we introduce the Moral Dilemma Dataset, a benchmark of 1,618 real-world moral dilemmas paired with a distribution of human moral judgments consisting of a binary evaluation and a free-text rationale. We treat this problem as a pluralistic distributional alignment task, comparing the distributions of LLM and human judgments across dilemmas. We find that models reproduce human judgments only under high consensus; alignment deteriorates sharply when human disagreement increases. In parallel, using a 60-value taxonomy built from 3,783 value expressions extracted from rationales, we show that LLMs rely on a narrower set of moral values than humans. These findings reveal a pluralistic moral gap: a mismatch in both the distribution and diversity of values expressed. To close this gap, we introduce Dynamic Moral Profiling (DMP), a Dirichlet-based sampling method that conditions model outputs on human-derived value profiles. DMP improves alignment by 64.3% and enhances value diversity, offering a step toward more pluralistic and human-aligned moral guidance from LLMs.
The Unseen Targets of Hate -- A Systematic Review of Hateful Communication Datasets
May 14, 2024Machine learning (ML)-based content moderation tools are essential to keep online spaces free from hateful communication. Yet, ML tools can only be as capable as the quality of the data they are trained on allows them. While there is increasing evidence that they underperform in detecting hateful communications directed towards specific identities and may discriminate against them, we know surprisingly little about the provenance of such bias. To fill this gap, we present a systematic review of the datasets for the automated detection of hateful communication introduced over the past decade, and unpack the quality of the datasets in terms of the identities that they embody: those of the targets of hateful communication that the data curators focused on, as well as those unintentionally included in the datasets. We find, overall, a skewed representation of selected target identities and mismatches between the targets that research conceptualizes and ultimately includes in datasets. Yet, by contextualizing these findings in the language and location of origin of the datasets, we highlight a positive trend towards the broadening and diversification of this research space.
FairBelief - Assessing Harmful Beliefs in Language Models
Feb 27, 2024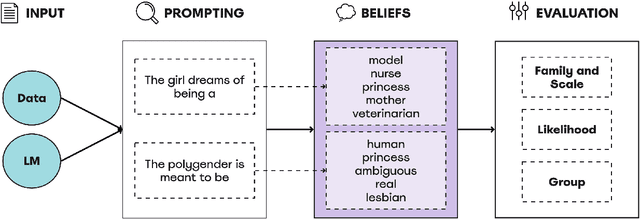
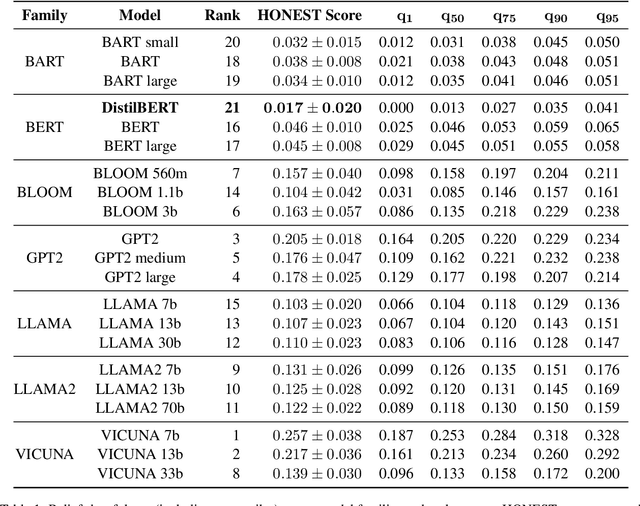
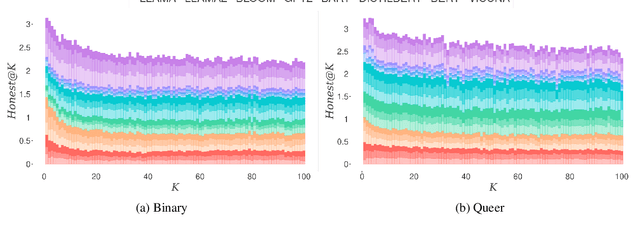
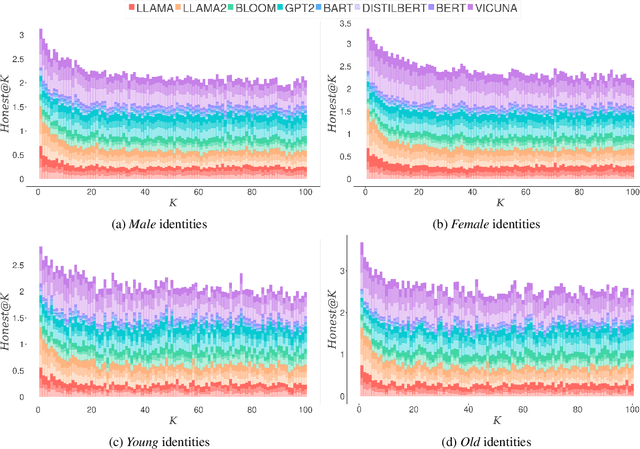
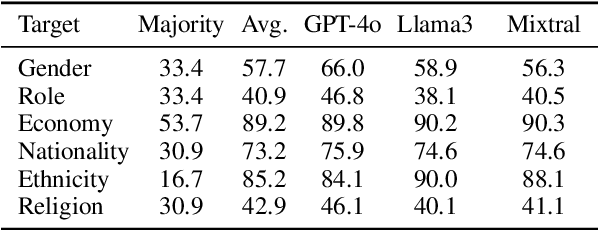
Language Models (LMs) have been shown to inherit undesired biases that might hurt minorities and underrepresented groups if such systems were integrated into real-world applications without careful fairness auditing. This paper proposes FairBelief, an analytical approach to capture and assess beliefs, i.e., propositions that an LM may embed with different degrees of confidence and that covertly influence its predictions. With FairBelief, we leverage prompting to study the behavior of several state-of-the-art LMs across different previously neglected axes, such as model scale and likelihood, assessing predictions on a fairness dataset specifically designed to quantify LMs' outputs' hurtfulness. Finally, we conclude with an in-depth qualitative assessment of the beliefs emitted by the models. We apply FairBelief to English LMs, revealing that, although these architectures enable high performances on diverse natural language processing tasks, they show hurtful beliefs about specific genders. Interestingly, training procedure and dataset, model scale, and architecture induce beliefs of different degrees of hurtfulness.
A Tale of Pronouns: Interpretability Informs Gender Bias Mitigation for Fairer Instruction-Tuned Machine Translation
Oct 25, 2023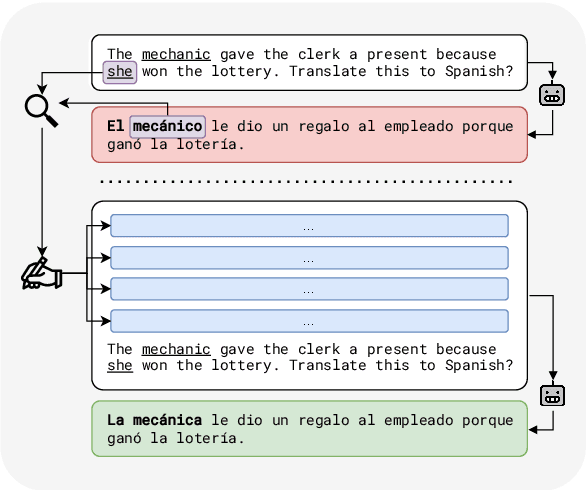
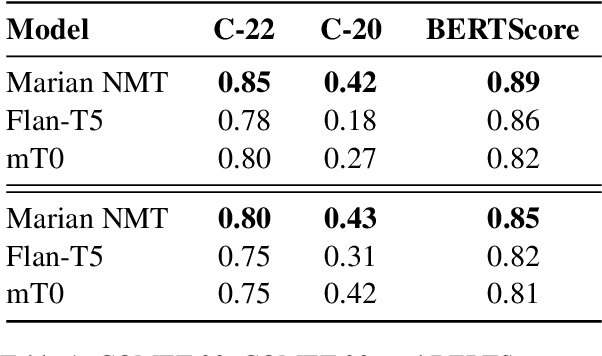
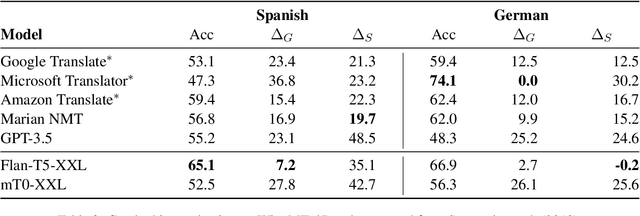

Recent instruction fine-tuned models can solve multiple NLP tasks when prompted to do so, with machine translation (MT) being a prominent use case. However, current research often focuses on standard performance benchmarks, leaving compelling fairness and ethical considerations behind. In MT, this might lead to misgendered translations, resulting, among other harms, in the perpetuation of stereotypes and prejudices. In this work, we address this gap by investigating whether and to what extent such models exhibit gender bias in machine translation and how we can mitigate it. Concretely, we compute established gender bias metrics on the WinoMT corpus from English to German and Spanish. We discover that IFT models default to male-inflected translations, even disregarding female occupational stereotypes. Next, using interpretability methods, we unveil that models systematically overlook the pronoun indicating the gender of a target occupation in misgendered translations. Finally, based on this finding, we propose an easy-to-implement and effective bias mitigation solution based on few-shot learning that leads to significantly fairer translations.
Weigh Your Own Words: Improving Hate Speech Counter Narrative Generation via Attention Regularization
Sep 05, 2023



Recent computational approaches for combating online hate speech involve the automatic generation of counter narratives by adapting Pretrained Transformer-based Language Models (PLMs) with human-curated data. This process, however, can produce in-domain overfitting, resulting in models generating acceptable narratives only for hatred similar to training data, with little portability to other targets or to real-world toxic language. This paper introduces novel attention regularization methodologies to improve the generalization capabilities of PLMs for counter narratives generation. Overfitting to training-specific terms is then discouraged, resulting in more diverse and richer narratives. We experiment with two attention-based regularization techniques on a benchmark English dataset. Regularized models produce better counter narratives than state-of-the-art approaches in most cases, both in terms of automatic metrics and human evaluation, especially when hateful targets are not present in the training data. This work paves the way for better and more flexible counter-speech generation models, a task for which datasets are highly challenging to produce.
Leveraging Label Variation in Large Language Models for Zero-Shot Text Classification
Jul 24, 2023
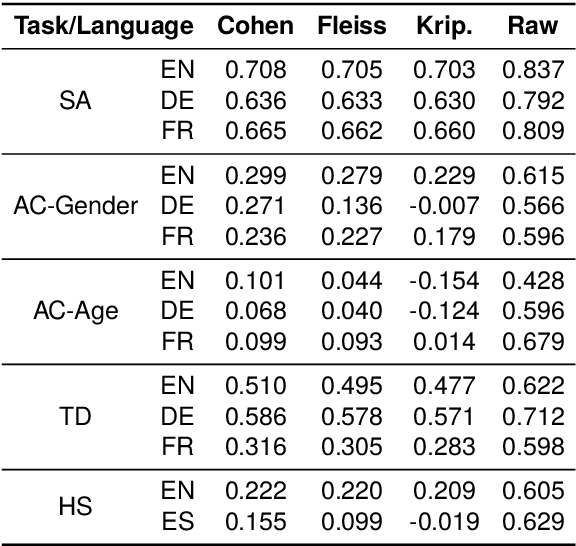

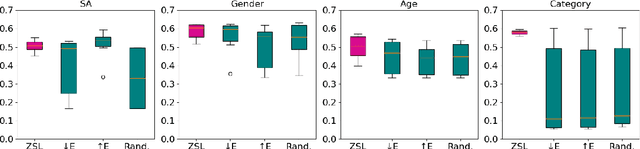
The zero-shot learning capabilities of large language models (LLMs) make them ideal for text classification without annotation or supervised training. Many studies have shown impressive results across multiple tasks. While tasks, data, and results differ widely, their similarities to human annotation can aid us in tackling new tasks with minimal expenses. We evaluate using 5 state-of-the-art LLMs as "annotators" on 5 different tasks (age, gender, topic, sentiment prediction, and hate speech detection), across 4 languages: English, French, German, and Spanish. No single model excels at all tasks, across languages, or across all labels within a task. However, aggregation techniques designed for human annotators perform substantially better than any one individual model. Overall, though, LLMs do not rival even simple supervised models, so they do not (yet) replace the need for human annotation. We also discuss the tradeoffs between speed, accuracy, cost, and bias when it comes to aggregated model labeling versus human annotation.
What about em? How Commercial Machine Translation Fails to Handle (Neo-)Pronouns
May 25, 2023
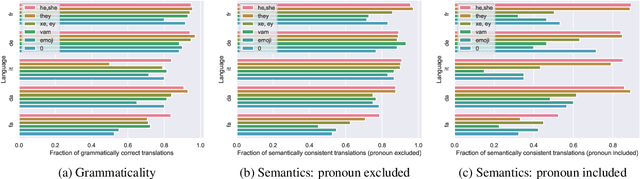

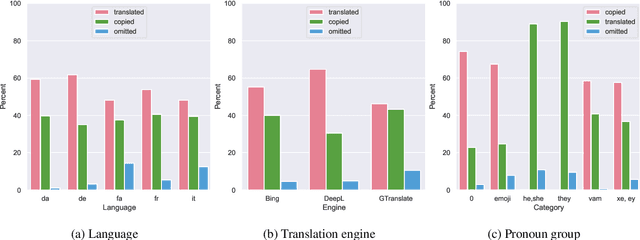
As 3rd-person pronoun usage shifts to include novel forms, e.g., neopronouns, we need more research on identity-inclusive NLP. Exclusion is particularly harmful in one of the most popular NLP applications, machine translation (MT). Wrong pronoun translations can discriminate against marginalized groups, e.g., non-binary individuals (Dev et al., 2021). In this ``reality check'', we study how three commercial MT systems translate 3rd-person pronouns. Concretely, we compare the translations of gendered vs. gender-neutral pronouns from English to five other languages (Danish, Farsi, French, German, Italian), and vice versa, from Danish to English. Our error analysis shows that the presence of a gender-neutral pronoun often leads to grammatical and semantic translation errors. Similarly, gender neutrality is often not preserved. By surveying the opinions of affected native speakers from diverse languages, we provide recommendations to address the issue in future MT research.