 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Formalization of a Trustworthy AI for Mining Interpretable Models explOiting Sophisticated Algorithms
Oct 23, 2025Interpretable-by-design models are crucial for fostering trust, accountability, and safe adoption of automated decision-making models in real-world applications. In this paper we formalize the ground for the MIMOSA (Mining Interpretable Models explOiting Sophisticated Algorithms) framework, a comprehensive methodology for generating predictive models that balance interpretability with performance while embedding key ethical properties. We formally define here the supervised learning setting across diverse decision-making tasks and data types, including tabular data, time series, images, text, transactions, and trajectories. We characterize three major families of interpretable models: feature importance, rule, and instance based models. For each family, we analyze their interpretability dimensions, reasoning mechanisms, and complexity. Beyond interpretability, we formalize three critical ethical properties, namely causality, fairness, and privacy, providing formal definitions, evaluation metrics, and verification procedures for each. We then examine the inherent trade-offs between these properties and discuss how privacy requirements, fairness constraints, and causal reasoning can be embedded within interpretable pipelines. By evaluating ethical measures during model generation, this framework establishes the theoretical foundations for developing AI systems that are not only accurate and interpretable but also fair, privacy-preserving, and causally aware, i.e., trustworthy.
FairBelief - Assessing Harmful Beliefs in Language Models
Feb 27, 2024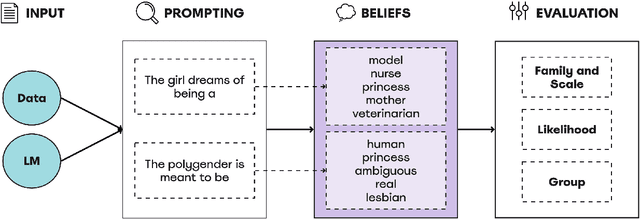
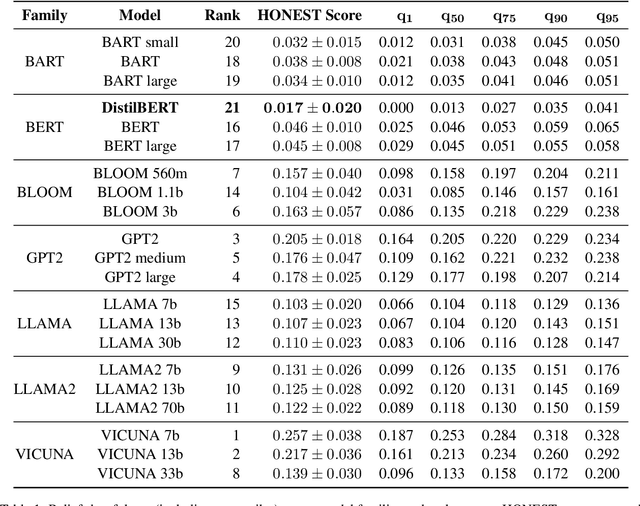
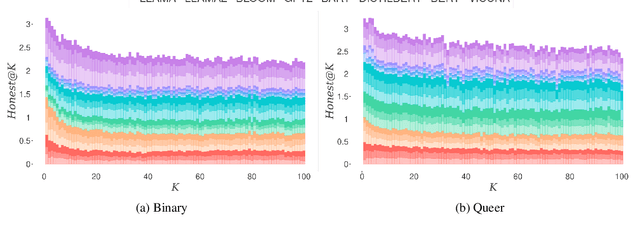
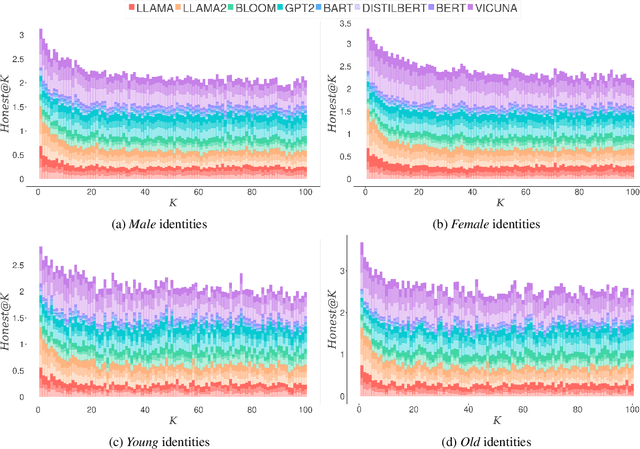
Language Models (LMs) have been shown to inherit undesired biases that might hurt minorities and underrepresented groups if such systems were integrated into real-world applications without careful fairness auditing. This paper proposes FairBelief, an analytical approach to capture and assess beliefs, i.e., propositions that an LM may embed with different degrees of confidence and that covertly influence its predictions. With FairBelief, we leverage prompting to study the behavior of several state-of-the-art LMs across different previously neglected axes, such as model scale and likelihood, assessing predictions on a fairness dataset specifically designed to quantify LMs' outputs' hurtfulness. Finally, we conclude with an in-depth qualitative assessment of the beliefs emitted by the models. We apply FairBelief to English LMs, revealing that, although these architectures enable high performances on diverse natural language processing tasks, they show hurtful beliefs about specific genders. Interestingly, training procedure and dataset, model scale, and architecture induce beliefs of different degrees of hurtfulness.
Social Bias Probing: Fairness Benchmarking for Language Models
Nov 15, 2023Large language models have been shown to encode a variety of social biases, which carries the risk of downstream harms. While the impact of these biases has been recognized, prior methods for bias evaluation have been limited to binary association tests on small datasets, offering a constrained view of the nature of societal biases within language models. In this paper, we propose an original framework for probing language models for societal biases. We collect a probing dataset to analyze language models' general associations, as well as along the axes of societal categories, identities, and stereotypes. To this end, we leverage a novel perplexity-based fairness score. We curate a large-scale benchmarking dataset addressing drawbacks and limitations of existing fairness collections, expanding to a variety of different identities and stereotypes. When comparing our methodology with prior work, we demonstrate that biases within language models are more nuanced than previously acknowledged. In agreement with recent findings, we find that larger model variants exhibit a higher degree of bias. Moreover, we expose how identities expressing different religions lead to the most pronounced disparate treatments across all models.