 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Formalization of a Trustworthy AI for Mining Interpretable Models explOiting Sophisticated Algorithms
Oct 23, 2025Interpretable-by-design models are crucial for fostering trust, accountability, and safe adoption of automated decision-making models in real-world applications. In this paper we formalize the ground for the MIMOSA (Mining Interpretable Models explOiting Sophisticated Algorithms) framework, a comprehensive methodology for generating predictive models that balance interpretability with performance while embedding key ethical properties. We formally define here the supervised learning setting across diverse decision-making tasks and data types, including tabular data, time series, images, text, transactions, and trajectories. We characterize three major families of interpretable models: feature importance, rule, and instance based models. For each family, we analyze their interpretability dimensions, reasoning mechanisms, and complexity. Beyond interpretability, we formalize three critical ethical properties, namely causality, fairness, and privacy, providing formal definitions, evaluation metrics, and verification procedures for each. We then examine the inherent trade-offs between these properties and discuss how privacy requirements, fairness constraints, and causal reasoning can be embedded within interpretable pipelines. By evaluating ethical measures during model generation, this framework establishes the theoretical foundations for developing AI systems that are not only accurate and interpretable but also fair, privacy-preserving, and causally aware, i.e., trustworthy.
Fair Clustering with Clusterlets
May 03, 2025Given their widespread usage in the real world, the fairness of clustering methods has become of major interest. Theoretical results on fair clustering show that fairness enjoys transitivity: given a set of small and fair clusters, a trivial centroid-based clustering algorithm yields a fair clustering. Unfortunately, discovering a suitable starting clustering can be computationally expensive, rather complex or arbitrary. In this paper, we propose a set of simple \emph{clusterlet}-based fuzzy clustering algorithms that match single-class clusters, optimizing fair clustering. Matching leverages clusterlet distance, optimizing for classic clustering objectives, while also regularizing for fairness. Empirical results show that simple matching strategies are able to achieve high fairness, and that appropriate parameter tuning allows to achieve high cohesion and low overlap.
FairBelief - Assessing Harmful Beliefs in Language Models
Feb 27, 2024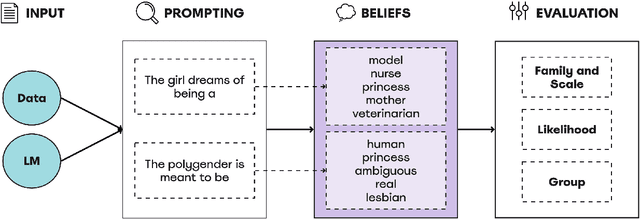
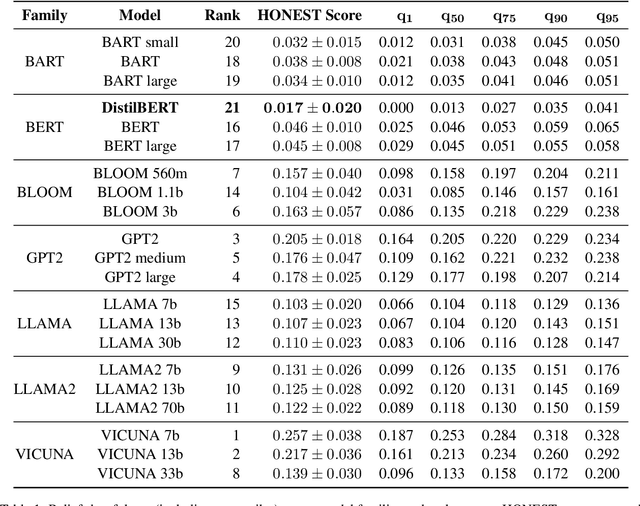
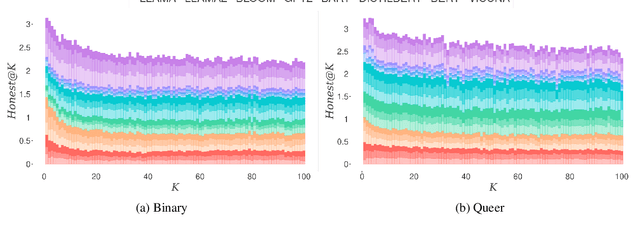
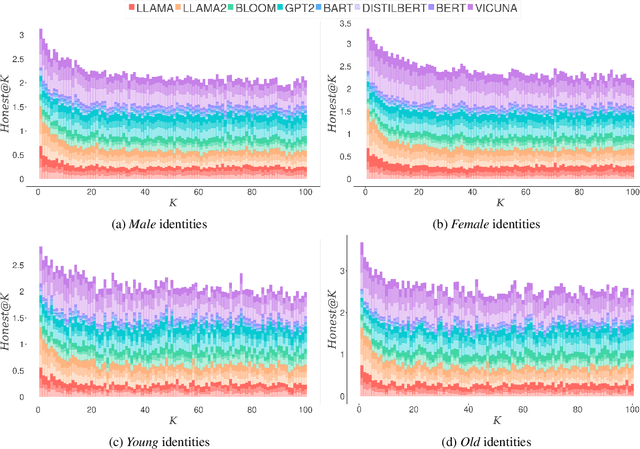
Language Models (LMs) have been shown to inherit undesired biases that might hurt minorities and underrepresented groups if such systems were integrated into real-world applications without careful fairness auditing. This paper proposes FairBelief, an analytical approach to capture and assess beliefs, i.e., propositions that an LM may embed with different degrees of confidence and that covertly influence its predictions. With FairBelief, we leverage prompting to study the behavior of several state-of-the-art LMs across different previously neglected axes, such as model scale and likelihood, assessing predictions on a fairness dataset specifically designed to quantify LMs' outputs' hurtfulness. Finally, we conclude with an in-depth qualitative assessment of the beliefs emitted by the models. We apply FairBelief to English LMs, revealing that, although these architectures enable high performances on diverse natural language processing tasks, they show hurtful beliefs about specific genders. Interestingly, training procedure and dataset, model scale, and architecture induce beliefs of different degrees of hurtfulness.
AI, Meet Human: Learning Paradigms for Hybrid Decision Making Systems
Feb 09, 2024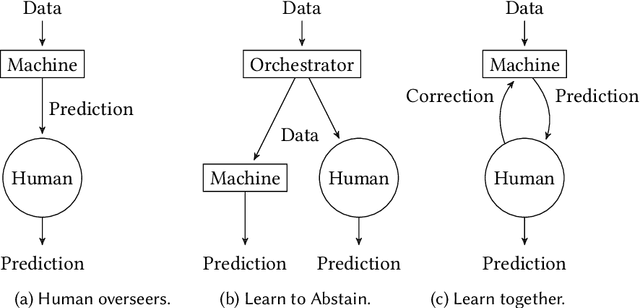



Everyday we increasingly rely on machine learning models to automate and support high-stake tasks and decisions. This growing presence means that humans are now constantly interacting with machine learning-based systems, training and using models everyday. Several different techniques in computer science literature account for the human interaction with machine learning systems, but their classification is sparse and the goals varied. This survey proposes a taxonomy of Hybrid Decision Making Systems, providing both a conceptual and technical framework for understanding how current computer science literature models interaction between humans and machines.
Correlation and Unintended Biases on Univariate and Multivariate Decision Trees
Dec 04, 2023Decision Trees are accessible, interpretable, and well-performing classification models. A plethora of variants with increasing expressiveness has been proposed in the last forty years. We contrast the two families of univariate DTs, whose split functions partition data through axis-parallel hyperplanes, and multivariate DTs, whose splits instead partition data through oblique hyperplanes. The latter include the former, hence multivariate DTs are in principle more powerful. Surprisingly enough, however, univariate DTs consistently show comparable performances in the literature. We analyze the reasons behind this, both with synthetic and real-world benchmark datasets. Our research questions test whether the pre-processing phase of removing correlation among features in datasets has an impact on the relative performances of univariate vs multivariate DTs. We find that existing benchmark datasets are likely biased towards favoring univariate DTs.
Explainable Authorship Identification in Cultural Heritage Applications: Analysis of a New Perspective
Nov 03, 2023



While a substantial amount of work has recently been devoted to enhance the performance of computational Authorship Identification (AId) systems, little to no attention has been paid to endowing AId systems with the ability to explain the reasons behind their predictions. This lacking substantially hinders the practical employment of AId methodologies, since the predictions returned by such systems are hardly useful unless they are supported with suitable explanations. In this paper, we explore the applicability of existing general-purpose eXplainable Artificial Intelligence (XAI) techniques to AId, with a special focus on explanations addressed to scholars working in cultural heritage. In particular, we assess the relative merits of three different types of XAI techniques (feature ranking, probing, factuals and counterfactual selection) on three different AId tasks (authorship attribution, authorship verification, same-authorship verification) by running experiments on real AId data. Our analysis shows that, while these techniques make important first steps towards explainable Authorship Identification, more work remains to be done in order to provide tools that can be profitably integrated in the workflows of scholars.
HANSEN: Human and AI Spoken Text Benchmark for Authorship Analysis
Oct 25, 2023Authorship Analysis, also known as stylometry, has been an essential aspect of Natural Language Processing (NLP) for a long time. Likewise, the recent advancement of Large Language Models (LLMs) has made authorship analysis increasingly crucial for distinguishing between human-written and AI-generated texts. However, these authorship analysis tasks have primarily been focused on written texts, not considering spoken texts. Thus, we introduce the largest benchmark for spoken texts - HANSEN (Human ANd ai Spoken tExt beNchmark). HANSEN encompasses meticulous curation of existing speech datasets accompanied by transcripts, alongside the creation of novel AI-generated spoken text datasets. Together, it comprises 17 human datasets, and AI-generated spoken texts created using 3 prominent LLMs: ChatGPT, PaLM2, and Vicuna13B. To evaluate and demonstrate the utility of HANSEN, we perform Authorship Attribution (AA) & Author Verification (AV) on human-spoken datasets and conducted Human vs. AI spoken text detection using state-of-the-art (SOTA) models. While SOTA methods, such as, character ngram or Transformer-based model, exhibit similar AA & AV performance in human-spoken datasets compared to written ones, there is much room for improvement in AI-generated spoken text detection. The HANSEN benchmark is available at: https://huggingface.co/datasets/HANSEN-REPO/HANSEN.
GLocalX -- From Local to Global Explanations of Black Box AI Models
Jan 26, 2021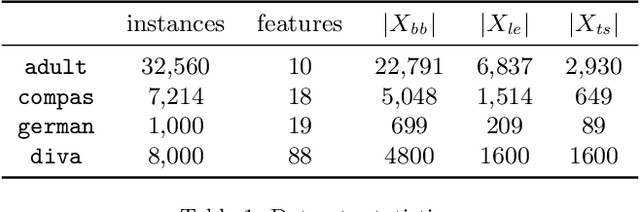
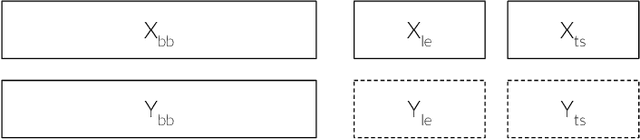
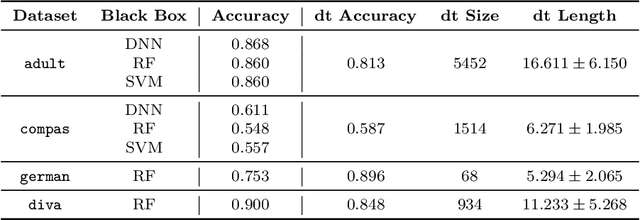
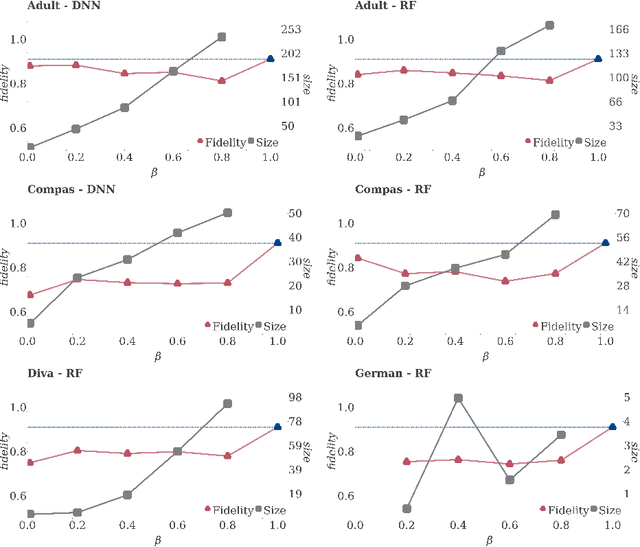
Artificial Intelligence (AI) has come to prominence as one of the major components of our society, with applications in most aspects of our lives. In this field, complex and highly nonlinear machine learning models such as ensemble models, deep neural networks, and Support Vector Machines have consistently shown remarkable accuracy in solving complex tasks. Although accurate, AI models often are "black boxes" which we are not able to understand. Relying on these models has a multifaceted impact and raises significant concerns about their transparency. Applications in sensitive and critical domains are a strong motivational factor in trying to understand the behavior of black boxes. We propose to address this issue by providing an interpretable layer on top of black box models by aggregating "local" explanations. We present GLocalX, a "local-first" model agnostic explanation method. Starting from local explanations expressed in form of local decision rules, GLocalX iteratively generalizes them into global explanations by hierarchically aggregating them. Our goal is to learn accurate yet simple interpretable models to emulate the given black box, and, if possible, replace it entirely. We validate GLocalX in a set of experiments in standard and constrained settings with limited or no access to either data or local explanations. Experiments show that GLocalX is able to accurately emulate several models with simple and small models, reaching state-of-the-art performance against natively global solutions. Our findings show how it is often possible to achieve a high level of both accuracy and comprehensibility of classification models, even in complex domains with high-dimensional data, without necessarily trading one property for the other. This is a key requirement for a trustworthy AI, necessary for adoption in high-stakes decision making applications.