 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIA-HARM: Dialectal Disparities in Harmful Content Detection Across 50 English Dialects
Apr 07, 2026Harmful content detectors-particularly disinformation classifiers-are predominantly developed and evaluated on Standard American English (SAE), leaving their robustness to dialectal variation unexplored. We present DIA-HARM, the first benchmark for evaluating disinformation detection robustness across 50 English dialects spanning U.S., British, African, Caribbean, and Asia-Pacific varieties. Using Multi-VALUE's linguistically grounded transformations, we introduce D3 (Dialectal Disinformation Detection), a corpus of 195K samples derived from established disinformation benchmarks. Our evaluation of 16 detection models reveals systematic vulnerabilities: human-written dialectal content degrades detection by 1.4-3.6% F1, while AI-generated content remains stable. Fine-tuned transformers substantially outperform zero-shot LLMs (96.6% vs. 78.3% best-case F1), with some models exhibiting catastrophic failures exceeding 33% degradation on mixed content. Cross-dialectal transfer analysis across 2,450 dialect pairs shows that multilingual models (mDeBERTa: 97.2% average F1) generalize effectively, while monolingual models like RoBERTa and XLM-RoBERTa fail on dialectal inputs. These findings demonstrate that current disinformation detectors may systematically disadvantage hundreds of millions of non-SAE speakers worldwide. We release the DIA-HARM framework, D3 corpus, and evaluation tools: https://github.com/jsl5710/dia-harm
BLUFF: Benchmarking the Detection of False and Synthetic Content across 58 Low-Resource Languages
Feb 28, 2026Multilingual falsehoods threaten information integrity worldwide, yet detection benchmarks remain confined to English or a few high-resource languages, leaving low-resource linguistic communities without robust defense tools. We introduce BLUFF, a comprehensive benchmark for detecting false and synthetic content, spanning 79 languages with over 202K samples, combining human-written fact-checked content (122K+ samples across 57 languages) and LLM-generated content (79K+ samples across 71 languages). BLUFF uniquely covers both high-resource "big-head" (20) and low-resource "long-tail" (59) languages, addressing critical gaps in multilingual research on detecting false and synthetic content. Our dataset features four content types (human-written, LLM-generated, LLM-translated, and hybrid human-LLM text), bidirectional translation (English$\leftrightarrow$X), 39 textual modification techniques (36 manipulation tactics for fake news, 3 AI-editing strategies for real news), and varying edit intensities generated using 19 diverse LLMs. We present AXL-CoI (Adversarial Cross-Lingual Agentic Chainof-Interactions), a novel multi-agentic framework for controlled fake/real news generation, paired with mPURIFY, a quality filtering pipeline ensuring dataset integrity. Experiments reveal state-of-theart detectors suffer up to 25.3% F1 degradation on low-resource versus high-resource languages. BLUFF provides the research community with a multilingual benchmark, extensive linguistic-oriented benchmark evaluation, comprehensive documentation, and opensource tools to advance equitable falsehood detection. Dataset and code are available at: https://jsl5710.github.io/BLUFF/
Beyond speculation: Measuring the growing presence of LLM-generated texts in multilingual disinformation
Mar 29, 2025Increased sophistication of large language models (LLMs) and the consequent quality of generated multilingual text raises concerns about potential disinformation misuse. While humans struggle to distinguish LLM-generated content from human-written texts, the scholarly debate about their impact remains divided. Some argue that heightened fears are overblown due to natural ecosystem limitations, while others contend that specific "longtail" contexts face overlooked risks. Our study bridges this debate by providing the first empirical evidence of LLM presence in the latest real-world disinformation datasets, documenting the increase of machine-generated content following ChatGPT's release, and revealing crucial patterns across languages, platforms, and time periods.
Masks and Mimicry: Strategic Obfuscation and Impersonation Attacks on Authorship Verification
Mar 24, 2025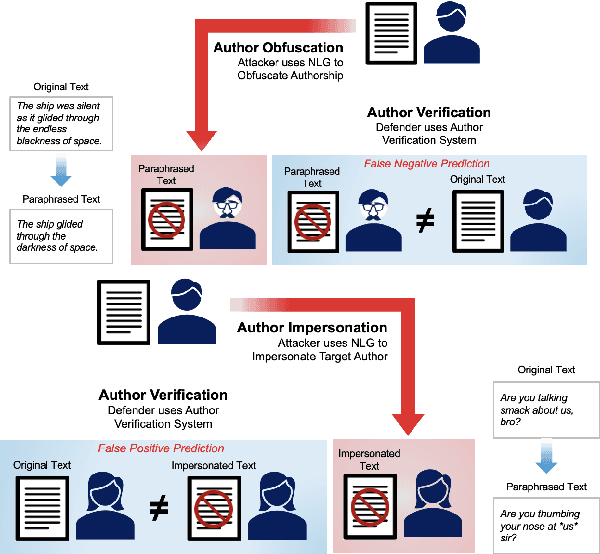

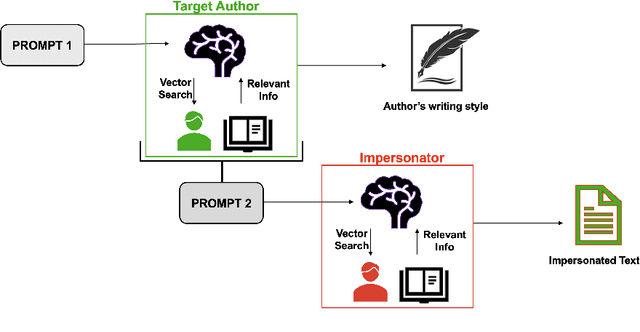
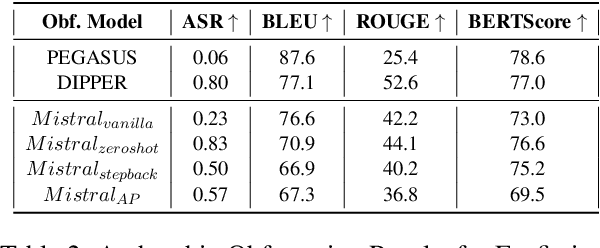
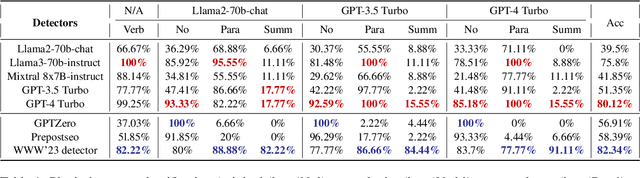
The increasing use of Artificial Intelligence (AI) technologies, such as Large Language Models (LLMs) has led to nontrivial improvements in various tasks, including accurate authorship identification of documents. However, while LLMs improve such defense techniques, they also simultaneously provide a vehicle for malicious actors to launch new attack vectors. To combat this security risk, we evaluate the adversarial robustness of authorship models (specifically an authorship verification model) to potent LLM-based attacks. These attacks include untargeted methods - \textit{authorship obfuscation} and targeted methods - \textit{authorship impersonation}. For both attacks, the objective is to mask or mimic the writing style of an author while preserving the original texts' semantics, respectively. Thus, we perturb an accurate authorship verification model, and achieve maximum attack success rates of 92\% and 78\% for both obfuscation and impersonation attacks, respectively.
Unveiling Topological Structures in Text: A Comprehensive Survey of Topological Data Analysis Applications in NLP
Nov 15, 2024



The surge of data available on the internet has led to the adoption of various computational methods to analyze and extract valuable insights from this wealth of information. Among these, the field of Machine Learning (ML) has thrived by leveraging data to extract meaningful insights. However, ML techniques face notable challenges when dealing with real-world data, often due to issues of imbalance, noise, insufficient labeling, and high dimensionality. To address these limitations, some researchers advocate for the adoption of Topological Data Analysis (TDA), a statistical approach that discerningly captures the intrinsic shape of data despite noise. Despite its potential, TDA has not gained as much traction within the Natural Language Processing (NLP) domain compared to structurally distinct areas like computer vision. Nevertheless, a dedicated community of researchers has been exploring the application of TDA in NLP, yielding 85 papers we comprehensively survey in this paper. Our findings categorize these efforts into theoretical and nontheoretical approaches. Theoretical approaches aim to explain linguistic phenomena from a topological viewpoint, while non-theoretical approaches merge TDA with ML features, utilizing diverse numerical representation techniques. We conclude by exploring the challenges and unresolved questions that persist in this niche field. Resources and a list of papers on this topic can be found at: https://github.com/AdaUchendu/AwesomeTDA4NLP.
Beemo: Benchmark of Expert-edited Machine-generated Outputs
Nov 06, 2024The rapid proliferation of large language models (LLMs) has increased the volume of machine-generated texts (MGTs) and blurred text authorship in various domains. However, most existing MGT benchmarks include single-author texts (human-written and machine-generated). This conventional design fails to capture more practical multi-author scenarios, where the user refines the LLM response for natural flow, coherence, and factual correctness. Our paper introduces the Benchmark of Expert-edited Machine-generated Outputs (Beemo), which includes 6.5k texts written by humans, generated by ten instruction-finetuned LLMs, and edited by experts for various use cases, ranging from creative writing to summarization. Beemo additionally comprises 13.1k machine-generated and LLM-edited texts, allowing for diverse MGT detection evaluation across various edit types. We document Beemo's creation protocol and present the results of benchmarking 33 configurations of MGT detectors in different experimental setups. We find that expert-based editing evades MGT detection, while LLM-edited texts are unlikely to be recognized as human-written. Beemo and all materials are publicly available.
PlagBench: Exploring the Duality of Large Language Models in Plagiarism Generation and Detection
Jun 24, 2024
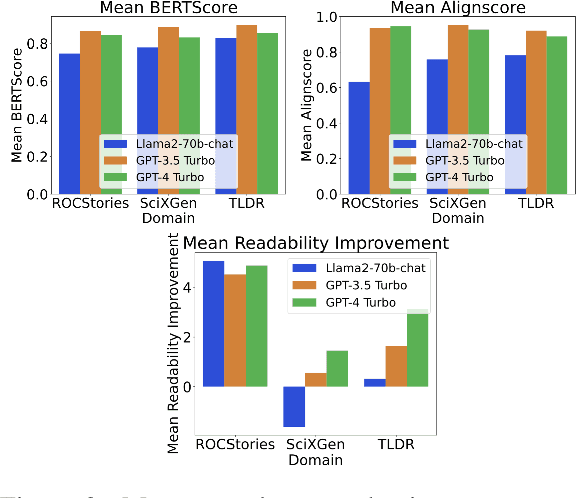

Recent literature has highlighted potential risks to academic integrity associated with large language models (LLMs), as they can memorize parts of training instances and reproduce them in the generated texts without proper attribution. In addition, given their capabilities in generating high-quality texts, plagiarists can exploit LLMs to generate realistic paraphrases or summaries indistinguishable from original work. In response to possible malicious use of LLMs in plagiarism, we introduce PlagBench, a comprehensive dataset consisting of 46.5K synthetic plagiarism cases generated using three instruction-tuned LLMs across three writing domains. The quality of PlagBench is ensured through fine-grained automatic evaluation for each type of plagiarism, complemented by human annotation. We then leverage our proposed dataset to evaluate the plagiarism detection performance of five modern LLMs and three specialized plagiarism checkers. Our findings reveal that GPT-3.5 tends to generates paraphrases and summaries of higher quality compared to Llama2 and GPT-4. Despite LLMs' weak performance in summary plagiarism identification, they can surpass current commercial plagiarism detectors. Overall, our results highlight the potential of LLMs to serve as robust plagiarism detection tools.
Authorship Obfuscation in Multilingual Machine-Generated Text Detection
Jan 15, 2024



High-quality text generation capability of latest Large Language Models (LLMs) causes concerns about their misuse (e.g., in massive generation/spread of disinformation). Machine-generated text (MGT) detection is important to cope with such threats. However, it is susceptible to authorship obfuscation (AO) methods, such as paraphrasing, which can cause MGTs to evade detection. So far, this was evaluated only in monolingual settings. Thus, the susceptibility of recently proposed multilingual detectors is still unknown. We fill this gap by comprehensively benchmarking the performance of 10 well-known AO methods, attacking 37 MGT detection methods against MGTs in 11 languages (i.e., 10 $\times$ 37 $\times$ 11 = 4,070 combinations). We also evaluate the effect of data augmentation on adversarial robustness using obfuscated texts. The results indicate that all tested AO methods can cause detection evasion in all tested languages, where homoglyph attacks are especially successful.
A Ship of Theseus: Curious Cases of Paraphrasing in LLM-Generated Texts
Nov 14, 2023



In the realm of text manipulation and linguistic transformation, the question of authorship has always been a subject of fascination and philosophical inquiry. Much like the \textbf{Ship of Theseus paradox}, which ponders whether a ship remains the same when each of its original planks is replaced, our research delves into an intriguing question: \textit{Does a text retain its original authorship when it undergoes numerous paraphrasing iterations?} Specifically, since Large Language Models (LLMs) have demonstrated remarkable proficiency in the generation of both original content and the modification of human-authored texts, a pivotal question emerges concerning the determination of authorship in instances where LLMs or similar paraphrasing tools are employed to rephrase the text. This inquiry revolves around \textit{whether authorship should be attributed to the original human author or the AI-powered tool, given the tool's independent capacity to produce text that closely resembles human-generated content.} Therefore, we embark on a philosophical voyage through the seas of language and authorship to unravel this intricate puzzle.
HANSEN: Human and AI Spoken Text Benchmark for Authorship Analysis
Oct 25, 2023Authorship Analysis, also known as stylometry, has been an essential aspect of Natural Language Processing (NLP) for a long time. Likewise, the recent advancement of Large Language Models (LLMs) has made authorship analysis increasingly crucial for distinguishing between human-written and AI-generated texts. However, these authorship analysis tasks have primarily been focused on written texts, not considering spoken texts. Thus, we introduce the largest benchmark for spoken texts - HANSEN (Human ANd ai Spoken tExt beNchmark). HANSEN encompasses meticulous curation of existing speech datasets accompanied by transcripts, alongside the creation of novel AI-generated spoken text datasets. Together, it comprises 17 human datasets, and AI-generated spoken texts created using 3 prominent LLMs: ChatGPT, PaLM2, and Vicuna13B. To evaluate and demonstrate the utility of HANSEN, we perform Authorship Attribution (AA) & Author Verification (AV) on human-spoken datasets and conducted Human vs. AI spoken text detection using state-of-the-art (SOTA) models. While SOTA methods, such as, character ngram or Transformer-based model, exhibit similar AA & AV performance in human-spoken datasets compared to written ones, there is much room for improvement in AI-generated spoken text detection. The HANSEN benchmark is available at: https://huggingface.co/datasets/HANSEN-REPO/HANSEN.